
关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
GitHub 地址:http://github.com/apache/pulsar/
本文原文作者是 Carolyn King。原文地址:https://streamnative.io/en/blog/community/2021-06-11-pulsar-user-survey-2021-highlights。译者:sijia。
2021 年 Apache Pulsar 用户调查报告显示,在过去的一年里 Apache Pulsar 的应用和社区活跃度发生了突飞猛进的变化。
企业选择 Pulsar 的主要原因包括:容器化和云上服务成为趋势、企业生产环境的规模不断扩大、运维负担大、消息平台需要同时支持批处理和流工作负载、解锁更多使用场景等。
Pulsar 是统一的消息和流平台,不仅具备云原生能力,还具备诸多其他优秀特性,如高可扩展性、高可靠性,这些独特优势可以满足许多新兴需求。
本文将为你详细解读 2021 年 Apache Pulsar 用户调查报告[1]的要点信息。敬请期待中文版完整报告的推送。
1.生产环境中的 Pulsar & 规模化使用 Pulsar
2.Kafka 用户选择 Pulsar
3.选择 Pulsar 的两大原因:云原生和 K8s
4.Pulsar + Flink:Pulsar 持续创新
本文将为你逐一解读上述要点信息。
1. 生产环境中的 Pulsar & 规模化使用 Pulsar
Pulsar 2021 年用户调查报告中最重要的两点结论为:
- 将 Pulsar 用于生产环境的企业数量大幅增加;
- 规模化使用 Pulsar 的企业数量大幅增加。
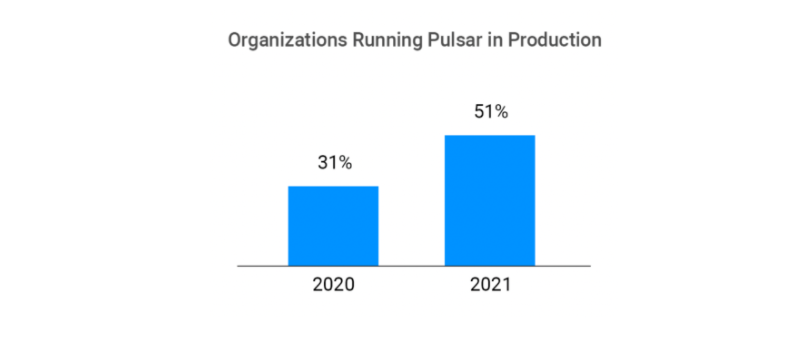
选择 Pulsar 的企业数量大幅上升,主要为在生产环境中部署 Pulsar(见上图)。Pulsar 2021 年用户调查报告显示 50% 的受访者所在团队已将 Pulsar 用于生产环境,而 2020 年这一比例仅为 31%。企业选择在生产环境中使用 Pulsar 证实了 Pulsar 具备交付关键任务的能力。
规模化使用 Pulsar
问:你所在企业每天使用 Pulsar 处理的消息量为多少?
答:12% 受访者的答案为超过 1 万亿条/天。
越来越多的企业在生产环境中使用 Pulsar,或实现企业级部署。12% 的受访者表示其所在企业使用 Pulsar 日均处理 1+ 万亿条消息,这些企业包括但不限于腾讯、Splunk、新大陆、金山云、Pactera 等。
Pulsar 在大规模使用场景中广受欢迎表明,Pulsar 在扩展性、可靠性等方面的能力足以满足当今企业的要求。值得一提的是,对于寻求消息和流一体化平台的团队而言,Pulsar 无疑是最佳选择。
2. 从 Kafka 到 Pulsar:越来越多 Kafka 用户决定使用 Pulsar
问:你所在企业除了使用 Pulsar 以外,还使用哪些消息队列?
答:68% 的受访者在使用 Pulsar 的同时,也在使用 Kafka。
问:你在用或者计划使用 Pulsar 的哪些 connector?
答:34% 的受访者选择 Kafka on Pulsar(KoP)
Kafka 用户使用 Pulsar
有多少 Kafka 用户开始使用 Pulsar?用户调查显示,在受访者中这一比例高达 68%。Kafka 更成熟、用户基数更大,不难推断,这 68% 的用户曾使用 Kafka,但现在他们决定使用 Pulsar(并非原本使用 Pulsar,而后开始使用 Kafka)。
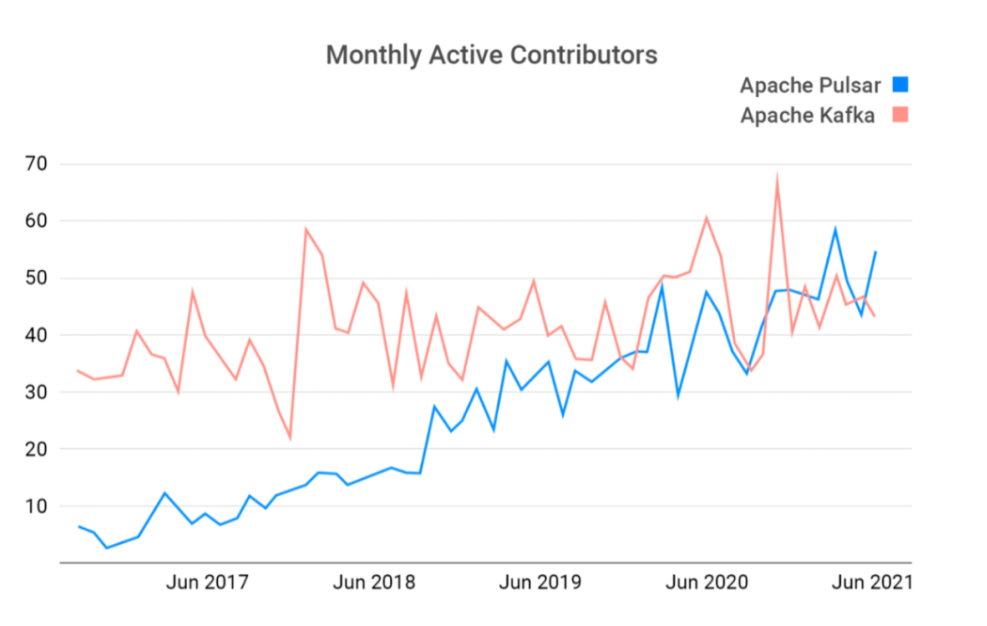
下图为 Pulsar 的活跃用户数据(来源:API7[2]),不难看出,Apache Pulsar 社区贡献者的月活跃度已经超过 Apache Kafka 社区。
此外,2021 年 Pulsar 用户调查还显示,超过三分之一的受访者使用或计划使用 Kafka on Pulsar(KoP)。KoP 于 2020 年推出,支持用户不编写任何代码,即可将 Kafka 应用程序和服务迁移到 Pulsar。
KoP 减少了 Kafka 用户使用 Pulsar 的阻碍,KoP 广受欢迎恰恰说明 Kafka 用户正在积极参与 Pulsar 的调研与使用,期待通过 Pulsar 解决 Kafka 的痛点问题,支撑更多使用场景。
Kafka 和 Pulsar 各有所长
超过三分之二(68%)的受访者正在同时使用 Kafka 和 Pulsar。Kafka 和 Pulsar 都适用于很多场景使用,这一数值似乎不合常理,但实际上 Kafka 和 Pulsar 的能力和使用场景不甚相同。
Kafka 旨在支持数据管道和大规模数据迁移,而 Pulsar 更适合用于消息和数据流场景,在这些场景中,通常需要处理数量更多的 topic 和更复杂的消费模型。
Pulsar 的原生特性包括多租户、跨地域复制、可扩展等,这些特性保证 Pulsar 在以下场景中表现优异,如:
(1)消息队列;
(2)发布/订阅;
(3)数据管道;
(4)流处理;
(5)微服务/事件源;
(6)数据集成;
(7)变更数据捕获;
(8)流 ETL 等。
由此可见,Pulsar 的使用范围比 Kafka 更广。
在过去的 12 个月里,Pulsar 新增了大量的使用案例,例如:
- Splunk 多年来一直在生产环境中使用 Kafka。去年,他们决定开始引入 Pulsar。在 2020 年 Pulsar Summit 上,Karthik Ramasamy 在分享中详细解释了为什么 Splunk 决定将 Pulsar 用于 Splunk DSP(一款分析应用,日处理数据量为数十亿)。观看“为什么 Splunk 选择 Pulsar[3]”,了解更多详细信息。
- Pulsar 支持处理数百万个 topic,具有高可靠性;对腾讯而言,Pulsar 的这两个特性最为重要。腾讯先后将 Pulsar 用于计费平台 Midas,联邦学习平台和腾讯游戏,取代了 Kafka 的日志管道。阅读博客原文[4],了解更多关于腾讯如何使用 Pulsar 的详细信息。
- Pulsar 在 Iterable 的使用历程则证明了 Pulsar 正在成为更多平台的选择。Iterable 首先使用 Pulsar 替换消息系统 RabbitMQ,然后替换 Kafka 和 Amazon SQS。阅读博文,了解更多关于 Iterable 如何使用 Pulsar 的详细信息。
用户调查报告显示,一旦企业中的某个团队开始使用 Pulsar,该企业内的其他团队也会陆续选择 Pulsar,腾讯和 Iterable 就是很好的例子。对于问题“你所在的团队是否会在 2021 年基于 Pulsar 搭建更多应用程序?”,回答“是”的受访者高达 66%,回答“在考虑中”的受访者比例为 10%。也就是说,大约 76% 的 Pulsar 用户正在考虑或计划增加 Pulsar 的使用。
3. 选择 Pulsar 的两大原因:云原生和 K8s
- 80% 的用户在云中使用 Pulsar
- 62% 的用户在 Kubernetes 上使用 Pulsar
- 49% 的用户认为 Pulsar 的云原生能力是他们选择 Pulsar 的最主要原因之一
更多企业选择上云或迁移到 Kubernetes,因此需要找到可以在云上运行、高可扩展,可以充分利用 Kubernetes 并可以在其上运行良好的中间件,这一趋势促进了 Pulsar 的使用。
单租户、单体架构,不支持跨地域复制和多云的系统已无法满足数据应用程序的需求。因此,越来越多的公司开始积极寻求通过云原生技术(如 Pulsar)来实现业务需求。
迁移到 Kubernetes 并非简单的迁移,这种迁移需要新的开发模式、新的工作方式,促使企业重新评估如何在云中部署和管理现有技术。例如,Kafka 等技术发布于云普及之前,因此很难映射到云和 Kubernetes 的功能。这些因素促使企业转而采用云原生技术,如 Pulsar。
4. Pulsar + Flink:Pulsar 持续创新
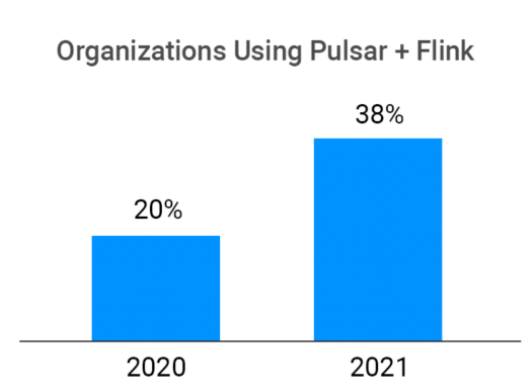
企业正在寻找统一的流解决方案,而 Pulsar 与 Flink 的集成增强了 Pulsar 社区的独特性,意义重大。对比 2020 年用户调查与 2021 年用户调查可知,在这一年时间里,Pulsar + Flink 用例的数量几乎翻了一番。Pulsar 的新增使用主要来自寻求实现新使用场景的公司,Pulsar + Flink 集成就是一个例子。
流处理器(如 Kafka Streams)擅长处理相对简单的流数据和近乎实时的计算,但不太适合处理大型历史数据集或需要执行多个合并操作和复杂分析的数据集。许多企业需要同时运行批数据处理器和流数据处理器,用于多条业务链,但维护多个系统既昂贵又复杂。
最近发布的新系统已经可以同时进行批处理和流处理,如 Apache Flink。目前,Flink 分别与 Kafka 和 Pulsar 结合使用进行流处理,但 Flink 的批处理功能与 Kafka 不完全兼容,因为 Kafka 只能以流交付数据,而这种方式的弊端是速度太慢,不能满足大多数批处理工作负载的要求。
Pulsar 采用分层存储模型,为 Flink 提供批处理所需的批量存储能力。借助 Pulsar + Flink,企业可以快速轻松地查询历史数据和实时数据,解锁更多竞争优势。
引用链接
[1] 2021 年 Apache Pulsar 用户调查报告: https://share.hsforms.com/1519w9knETd2kiCGqRocmwg3x5r4
[2] API7: https://www.apiseven.com/en/contributor-graph?chart=contributorMonthlyActivity&repo=apache/pulsar,apache/kafka
[3] 为什么 Splunk 选择 Pulsar: https://www.bilibili.com/video/BV12t4y1X7b5
[4] 博客原文: https://streamnative.io/en/blog/case/2020-02-18-pulsar-help-tencent
