内容简介:Google 研究团队开源在 Tensorflow 中进行语义图像分割(Semantic Image Segmentation)模型 DeepLab-v3+,包括 Google Pixel 2 和 Pixel 2XL 手机上的人像模式(Portrait Mode),以及 YouTube 为影片实时更换背...
Google 研究团队开源在 Tensorflow 中进行语义图像分割(Semantic Image Segmentation)模型 DeepLab-v3+,包括 Google Pixel 2 和 Pixel 2XL 手机上的人像模式(Portrait Mode),以及 YouTube 为影片实时更换背景功能,都是这项技术的应用。

Google 研究软件工程师 Liang-Chieh Chen 以及 Yukun Zhu 表示,语义图像分割的主要目的是为每个像素指定语义标签,例如路、天空、人或是狗等物体,不少的程序需要这样的功能,像是合成浅景深效果(Synthetic Shallow Depth-of-field)效果,应用在手机 Pixel 2 和 Pixel 2XL 上提供的人像模式(Portrait Mode),能自动模糊人物的背景,作出类似单镜头反光相机的景深效果。

另外,在多数摄影 App 都会提供的实时影像分割(Video Segmentation),例如最近 YouTube 发表的新功能,为影片换背景的功能,也是语义影像分割的应用。
DeepLab-v3+ 在 Tensorflow 上进行,使用部署于服务器端的卷积神经网络(CNN)骨干架构,以获取最佳的结果。除了代码之外,研究团队也同时公开了 Tensorflow 模型训练以及评估程序,以及使用 Pascal VOC 2012 与 Cityscapes 资料集训练的模型。
DeepLab-v3+ 技术是基于三年前的 DeepLab 模型,期间改进了卷积神经网络特征萃取器、物体比例塑造模型以及同化前后内容的技术,再加上进步的模型训练过程,还有软硬件的升级,从 DeepLab-v2 到 DeepLab-v3,直到现在发表的 DeepLab-v3+,效果一代比一代好。
DeepLab-v3+ 是由 DeepLab-v3 扩充而来,研究团队增加了解码器模组,能够细化分割结果,能够更精准的处理物体的边缘,并进一步将深度卷积神经网络应用在空间金字塔池化(Spatial Pyramid Pooling,SPP)和解码器上,大幅提升处理物体大小以及不同长宽比例的能力,最后得到强而有力的语义分割编码解码器网络。
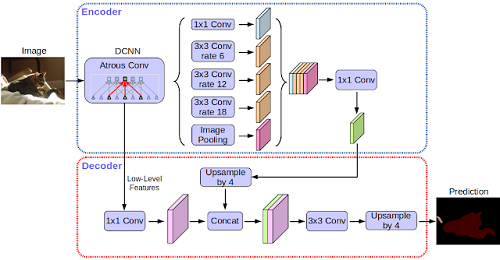
Liang-Chieh Chen 以及 Yukun Zhu 特别提到,随着软硬件的升级,建构在卷积神经网路上的现代语义图像分割功能,可以达到的水准已经远远超过5年前。
【声明】文章转载自:开源中国社区 [http://www.oschina.net]
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
- PyTorch语义分割开源库semseg
- CVPR2019| 12篇CVPR论文开源代码(DeepFashion2/语义分割/人脸数据集基准等)
- 南邮提出实时语义分割的轻量级网络:LEDNET,可达 71 FPS!70.6% class mIoU!即将开源
- 消息队列的消费语义和投递语义
- 剑桥构建视觉“语义大脑”:兼顾视觉信息和语义表示
- 新瓶装旧酒:语义网络,语义网,链接数据和知识图谱
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Effective JavaScript
赫尔曼 (David Herman) / 黄博文、喻杨 / 机械工业出版社 / 2014-1-1 / CNY 49.00
Effective 系列丛书经典著作,亚马逊五星级畅销书,Ecma 的JavaScript 标准化委员会著名专家撰写,JavaScript 语言之父、Mozilla CTO —— Brendan Eich 作序鼎力推荐!作者凭借多年标准化委员会工作和实践经验,深刻辨析JavaScript 的内部运作机制、特性、陷阱和编程最佳实践,将它们高度浓缩为极具实践指导意义的 68 条精华建议。 本书共......一起来看看 《Effective JavaScript》 这本书的介绍吧!


