内容简介:✏️ 作者:栾小凡, Zilliz 研发总监 2018 年 10 月,我们写下了向量数据库 Milvus 的第一行代码;在历经了 29 个月、19 个版本的迭代与全球 1000 家用户的实践验证后,终于在 2021 年 3月迎来了 Milvus 1.0 版本...


✏️ 作者:栾小凡, Zilliz 研发总监
2018 年 10 月,我们写下了向量数据库 Milvus 的第一行代码;在历经了 29 个月、19 个版本的迭代与全球 1000 家用户的实践验证后,终于在 2021 年 3月迎来了 Milvus 1.0 版本。Milvus 解决了对向量数据进行增删改查(CRUD)操作和数据持久化的问题,但随着新需求的出现,更多问题也逐渐浮现出来。本文旨在总结过去三年的经验,聊聊 Milvus 2.0 期待解决的问题,以及为什么 Milvus 2.0 是解决这些问题的良药。
Milvus 1.0 所面临的挑战
1. 数据孤岛: Milvus 1.0 仅支持处理非结构化数据产生的向量数据,缺乏标量查询能力。数据存储的割裂造成应用设计的复杂度增加和数据冗余,且标量和向量混合查询也因缺少统一的优化器导致性能不佳。
2. 实时性与效率的冲突: 与 Elasticsearch 类似,Milvus 1.0 是一套近实时系统,需要定期或者主动落盘来确保数据可见。这种模型给流式处理带来很大的复杂性和不确定性。另一方面,离线批量导入场景核心关注处理效率,批量写入在处理全量离线数据的场景下依然消耗了大量资源。
3. 可扩展性和弹性不足: Milvus 1.0 依赖 Mishards 中间件实现分布式扩展,下层依赖共享存储实现典型的 Shared Storage 架构,但整体扩展性不足,主要体现在以下三个方面:
-
写节点是一个单点,无法横向扩展。
-
读节点的扩展基于一致性 hash 进行路由。一致性哈希尽管实现简单,但数据调度不够灵活,仅仅解决了数据分布均匀性的问题,不能很好地解决数据和算力不匹配的问题。
-
依赖 MySQL 管理元数据——单机 MySQL 能支持的查询量和数据量都有限。
4. 可用性不足: 在传统的 CAP 定理中,Milvus 用户往往更加偏向于可用性(Availability)而不是一致性(Consistency)。Milvus 1.0 版本缺少多副本热备、跨机房容灾等能力,在可用性上并不理想。放弃一部分数据的准确性也有助于获得更好的性能。
5. 成本高昂: Milvus 1.0 依赖共享存储保证数据的持久性,而共享存储的成本通常是本地存储或者对象存储成本的 10 倍以上。由于向量搜索算法非常依赖计算资源和内存,过高的成本也成为了用户探索更大数据量和更多业务规则的阻碍。
6. 使用繁琐:
1)分布式版本部署复杂,运维成本高。
2)缺少好的图形化集群管理工具。
3)API 复杂,开发效率较低。
缝缝补补还是推倒重来,这是一个值得思考的问题。Milvus 项目发起人星爵认为,就像传统汽车巨头宝马奔驰永远造不出特斯拉,Milvus 需要成为非结构化数据领域的颠覆者,用户最终会像拥抱新能源汽车一样拥抱云原生的解决方案。Milvus 2.0 应云而生,作为我们贡献给非结构化数据处理的礼物。
Milvus 2.0 版本的诞生
架构设计理念
围绕以下三个理念,我们重新定义下一代云原生向量数据库:
-
云原生优先:我们认为,只有存储计算分离的架构才能发挥云的弹性,实现按需扩容的模式。另一个值得注意是 Milvus 2.0 采取了读写分离、实时离线分离、计算瓶颈/内存瓶颈/IO瓶颈分离的微服务化设计模式,这有助于我们面对复杂的工作负载选择最佳的资源配比。
-
日志即数据:Milvus 引入消息存储作为系统的骨架,数据的插入修改只通过消息存储交互,执行节点通过订阅消息流来执行数据库的增删改查操作。这一设计的优势在于降低了系统的复杂度,将数据库关键的持久化和闪回等能力都下钻到存储层;另一方面,日志订阅机制提供了极大的灵活性,为系统未来的拓展奠定了基础。
-
批流一体:Milvus 2.0 实现了 unified Lambda 流式处理架构,增量数据和离线数据一体化处理。相比 Kappa 架构,Milvus 引入对日志流的批量计算将日志快照和构建索引存入对象存储,这大大提高了故障恢复速度和查询效率。为了将无界的流式数据拆分成有界的窗口,Milvus 采用 watermark 机制,通过写入时间(也可以是事件发生时间)将数据切分为多个小的处理单元,并维护了一条时间轴便于用户基于某个时间点进行查询。
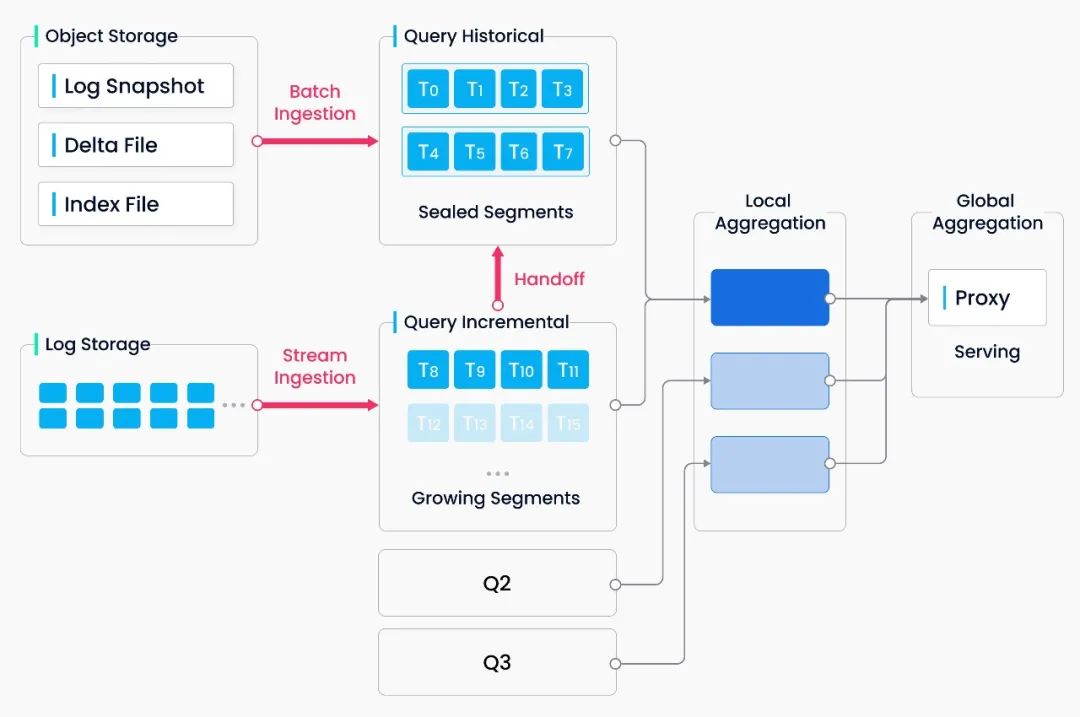
系统组件
Milvus 系统严格遵从存储与计算分离、控制平面与数据平面分离的设计原则,整个系统分为四个部分: 接入层(Access Layer)、协调服务(Coordinator Service)、执行节点(Worker Node)和存储层(Storage)。
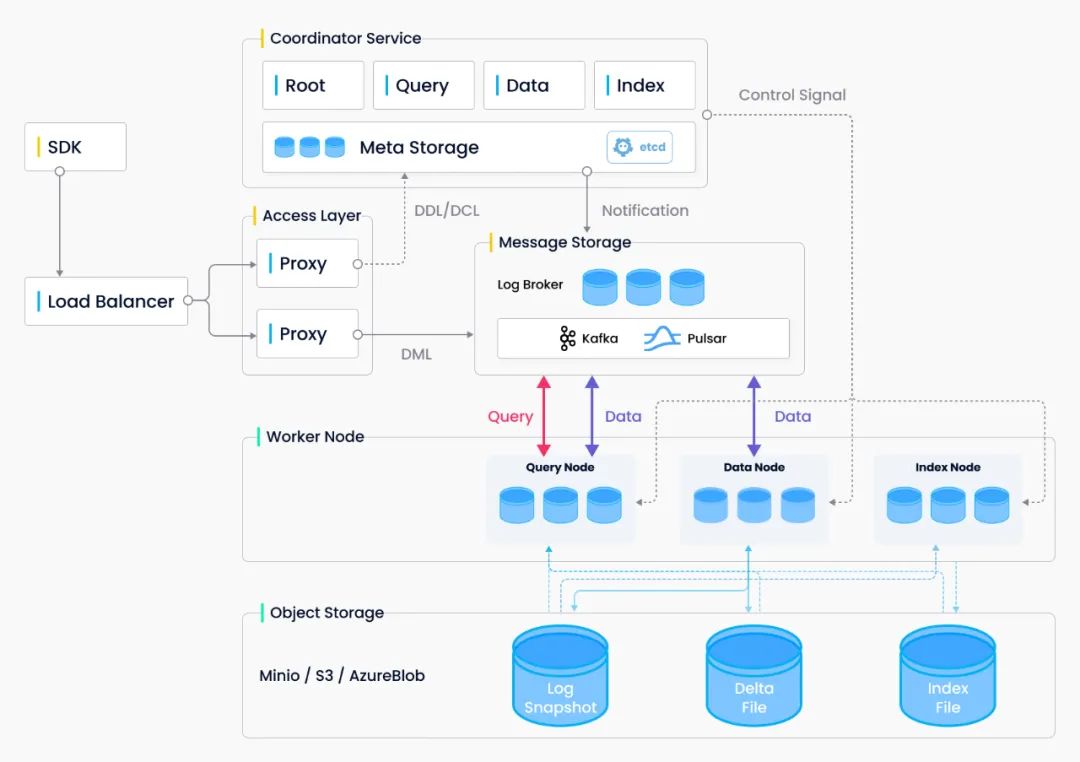
系统框架图
-
接入层:系统的门面,包含了一组对等的 proxy 节点。接入层是暴露给用户的统一 endpoint,负责转发请求并收集执行结果。
-
协调服务:系统的大脑。总共有四类协调者角色,分别为 root coord、data coord、query coord 和 index coord。
-
执行节点:系统的四肢。执行节点只负责被动执行协调服务发起的命令,响应接入层发起的读写请求。目前有三类执行节点,即 data node、query node 和 index node。
-
存储服务:系统的骨骼。Milvus 依赖三类存储:元数据存储、消息存储和对象存储。元数据存储便于协调服务存储 collection schema、数据消费位点等元信息,基于 etcd 实现。消息存储主要用于存储系统增量日志数据,实现可靠的异步通知机制,目前基于 Pulsar 实现。对象存储主要用于存储日志快照和索引数据,目前基于 MinIO 或 S3 实现。
功能亮点
Milvus 2.0 作为一款开源分布式向量数据库产品,始终将产品的易用性放在系统设计的第一优先级。一款数据库的使用成本不仅包含了运行态的资源消耗成本,也包含了运维成本和接入学习成本。Milvus 新版本支持了大量降低用户使用成本的功能。
1. 持续可用
实现数据的可靠存储和可持续的服务是对数据库产品的基本要求。我们的理念是 Fail cheap, fail small, fail often。Fail cheap 指的是 Milvus 采取的存储计算分离架构,节点失败恢复的处理十分简单,且代价很低。Fail small 指的是 Milvus 采取分而治之的思想,每个协调服务仅处理读/写/增量/历史数据中的一个部分,设计被大大简化。Fail often 指的是混沌测试的引入,通过故障注入模拟硬件异常、依赖失效等场景,加速问题在测试环境被发现的概率。
2. 向量/标量混合查询
为了解决结构化数据和非结构化数据的割裂问题,Milvus 2.0 支持标量存储和向量标量混合查询。混合查询帮助用户找出符合过滤表达式的近似邻,目前 Milvus 支持等于、大于、小于等关系运算以及 NOT、AND、OR 、IN 等逻辑运算。
3. 多一致性
Milvus 2.0 是基于消息存储构建的分布式数据库,遵循 PACELC 定理所定义的,必须在一致性和可用性/延迟之间进行取舍。绝大多数 Milvus 场景在生产中不应过分关注数据一致性的问题,原因是接受少量数据不可见对整体召回率的影响极小,但对于性能的提升帮助很大。尽管如此,我们认为强一致性、有界一致性、会话一致性等一致性保障语义依然有其独特的应用场景。比如,在功能测试场景下,用户可能期待使用强一致语义保证测试结果的正确性,因此 Milvus 支持请求级别的可调一致性级别。
4. 时间旅行:
数据工程师经常会因为脏数据、代码逻辑等问题需要回滚数据。传统的数据库通常通过快照方式来实现数据回滚,有时甚至需要重新训练,带来高昂的额外开销和维护成本。Milvus 对所有数据增删操作维护了一条时间轴,用户查询时可以指定时间戳以获取某个时间点之前的数据视图。基于 Time Travel,Milvus 还可以很轻量地实现备份和数据克隆功能。
5. ORM Python SDK:
对象关系映射(Object Relational Mapping)技术使用户更加关注于业务模型而非底层的数据模型,便于开发者维护表、字段与程序之间的关联关系。为了弥补 AI 算法概念验证(Proof of concept)到实际生产部署之间的缺口,我们设计了 Milvus ORM API,而其背后的实现可以是通过嵌入式的 Library、单机部署、分布式集群,也可能是云服务。通过统一的 API 提供一致的使用体验,避免云端两侧重复开发、测试与上线效果不一致等问题。
6. 丰富的周边支持:
1. 图形化管理界面:Milvus Insight 是 Milvus 图形化管理界面,包含了集群状态可视化、元数据管理、数据查询等实用功能。Milvus Insight 源码也会作为独立项目开源,期待有更多感兴趣的人加入共同建设。
2. 支持基于 helm 和 docker-compose 的一键部署。
3. 性能监控:Milvus 2.0 使用开源时序数据库 Prometheus 存储性能和监控数据,同时依赖 Grafana 进行指标展示。
以上是 Milvus 2.0 版本的简单介绍,如有兴趣了解更多 Milvus 2.0 的相关内容,请参阅完整的 Milvus 2.0 发版说明:https://github.com/milvus-io/milvus/releases。
关于未来
回顾 Milvus 的发展历程,我们认为基于大数据 + AI 的应用架构依然过于复杂,简化非结构化数据处理一直是 Milvus 社区努力的方向。接下来的 Milvus 项目会重点关注以下几个方向:
DB for AI:作为一款数据库,除了基本的 CRUD 功能之外,Milvus 必然还需要更强大的数据查询能力、更智能的查询优化器、更全的数据管理功能等。下一阶段我们将重点补齐 Milvus 2.0 目前还不支持的 DML 功能和数据类型,比如删除、更新操作和支持 string 数据类型。
AI for DB:向量索引类型、索引参数、用户工作负载、硬件类型、成本性能等的约束构成了一个非常庞大的 tradeoff,尽可能避免手动调优有助于降低使用复杂度。我们已经着手分析系统负载,收集访问热度的数据,后续将引入自动参数调优工作以降低用户的理解成本。
成本优化:向量召回的最大挑战是需要在限定时间内处理海量数据,这项工作既是计算密集型,也是访存密集型。在物理执行层引入 GPU、FPGA 等异构硬件加速可以大幅降低 CPU 开销。我们正在开发磁盘内存混合的 ANN 索引算法,可以在有限的内存下实现海量向量的高性能查询。于此同时,我们也在评估开源的 ScaNN、NGT 等向量索引算法的性能。
易用性:Milvus 易用性的提升体现在集群管理 工具 、多语言 SDK、部署工具、运维工具等许多方面,能够让大家快速上手使用是我们最有成就感的工作。
Milvus Roadmap
关于 Milvus 的未来的更多规划,欢迎大家通过项目 Roadmap 来了解:https://milvus.io/docs/v2.0.0/roadmap.md。
Thank you contributors!
最后感谢 Milvus 社区的 138 位贡献者,有了他们才有了今日的 Milvus 2.0。也欢迎大家开 issue 吐槽,或是加入社区一起贡献:https://milvus.io/community。
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 目前是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集。我们的技术在新药发现、计算机视觉、推荐引擎、聊天机器人等方面具有广泛的应用。
以上所述就是小编给大家介绍的《Milvus 2.0 新版本一览:重新定义向量数据库》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
猜你喜欢:
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。



