内容简介:PiFlow是一个基于分布式计算框架Spark开发的大数据流水线系统。该系统将数据的采集、清洗、计算、存储等各个环节封装成组件,以所见即所得方式进行流水线配置。简单易用,功能强大。本次版本更新如下特性: 增加了...

![]()
PiFlow是一个基于分布式计算框架Spark开发的大数据流水线系统。该系统将数据的采集、清洗、计算、存储等各个环节封装成组件,以所见即所得方式进行流水线配置。简单易用,功能强大。本次版本更新如下特性:
- 增加了运行单个数据处理组件、当前及以下数据处理组件功能;
- 增加了测试数据管理功能;
- 增加了数据处理组件显隐功能;
- 增加了表格组件,支持数据下载;
- 增加了 Sql 编辑器;
- 针对页面友好性进行了优化;
GitHub地址: https://github.com/cas-bigdatalab/piflow
1)运行单个数据处理组件
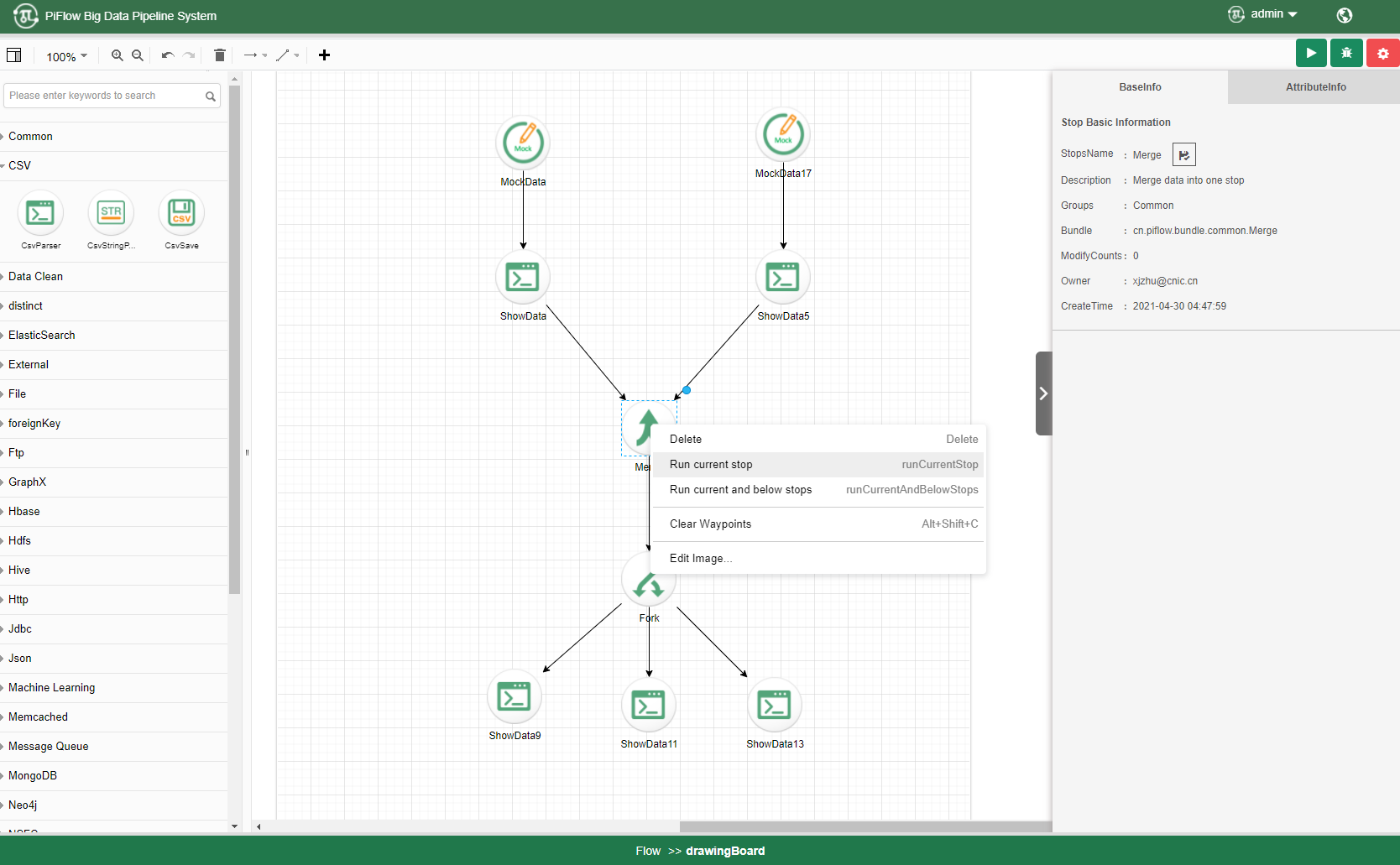
2)测试数据管理
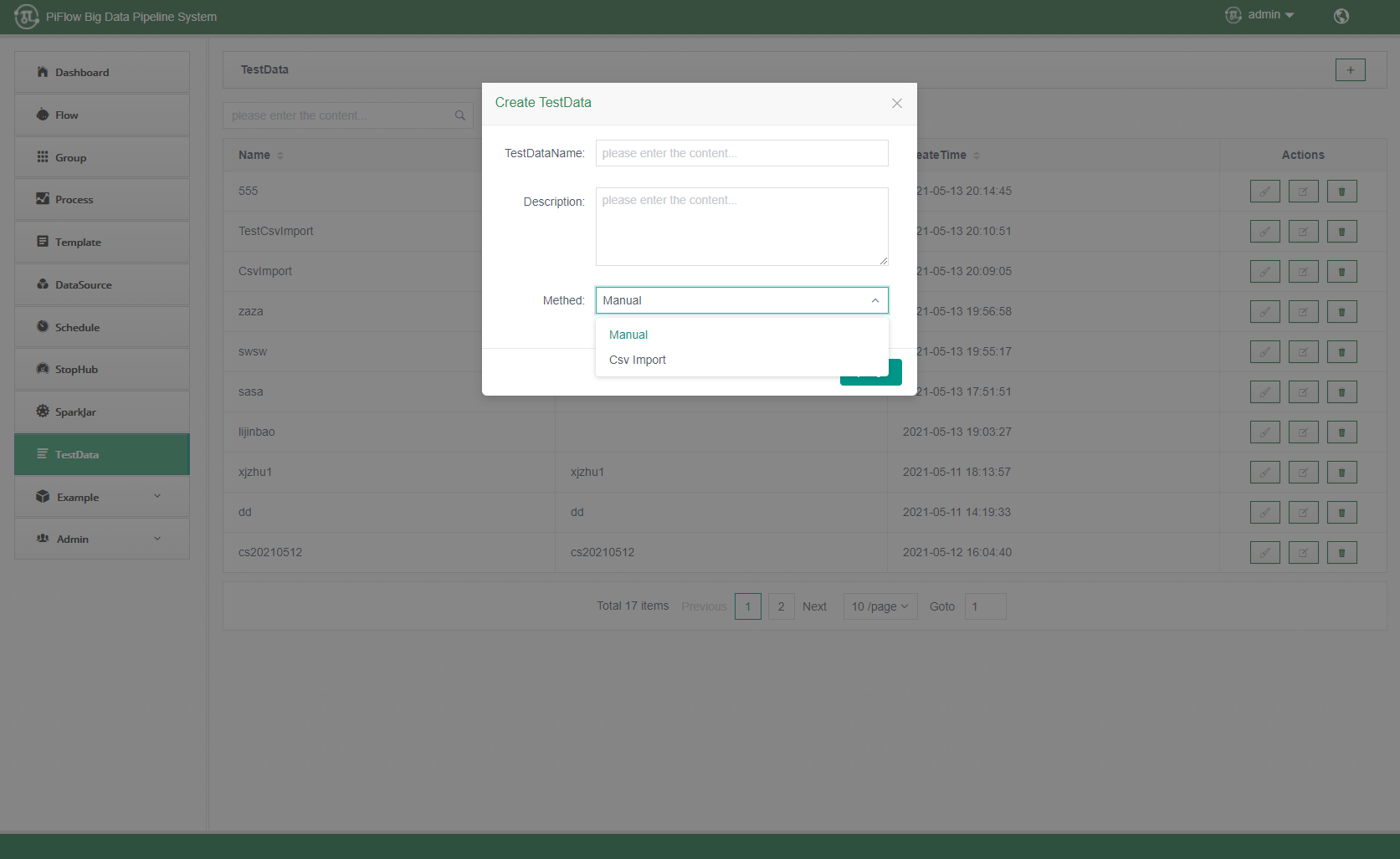
3)数据处理组件显隐
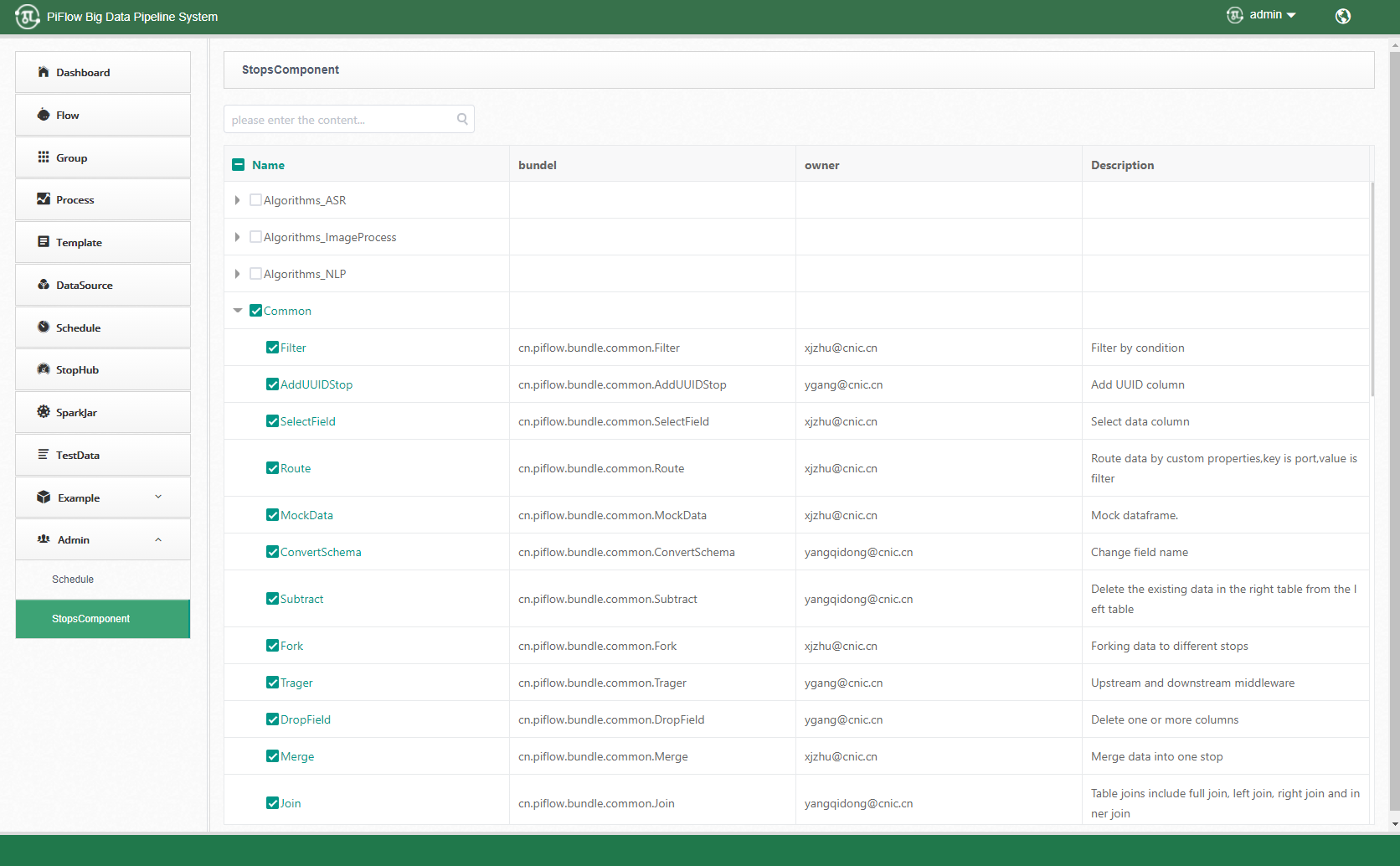
4)表格组件
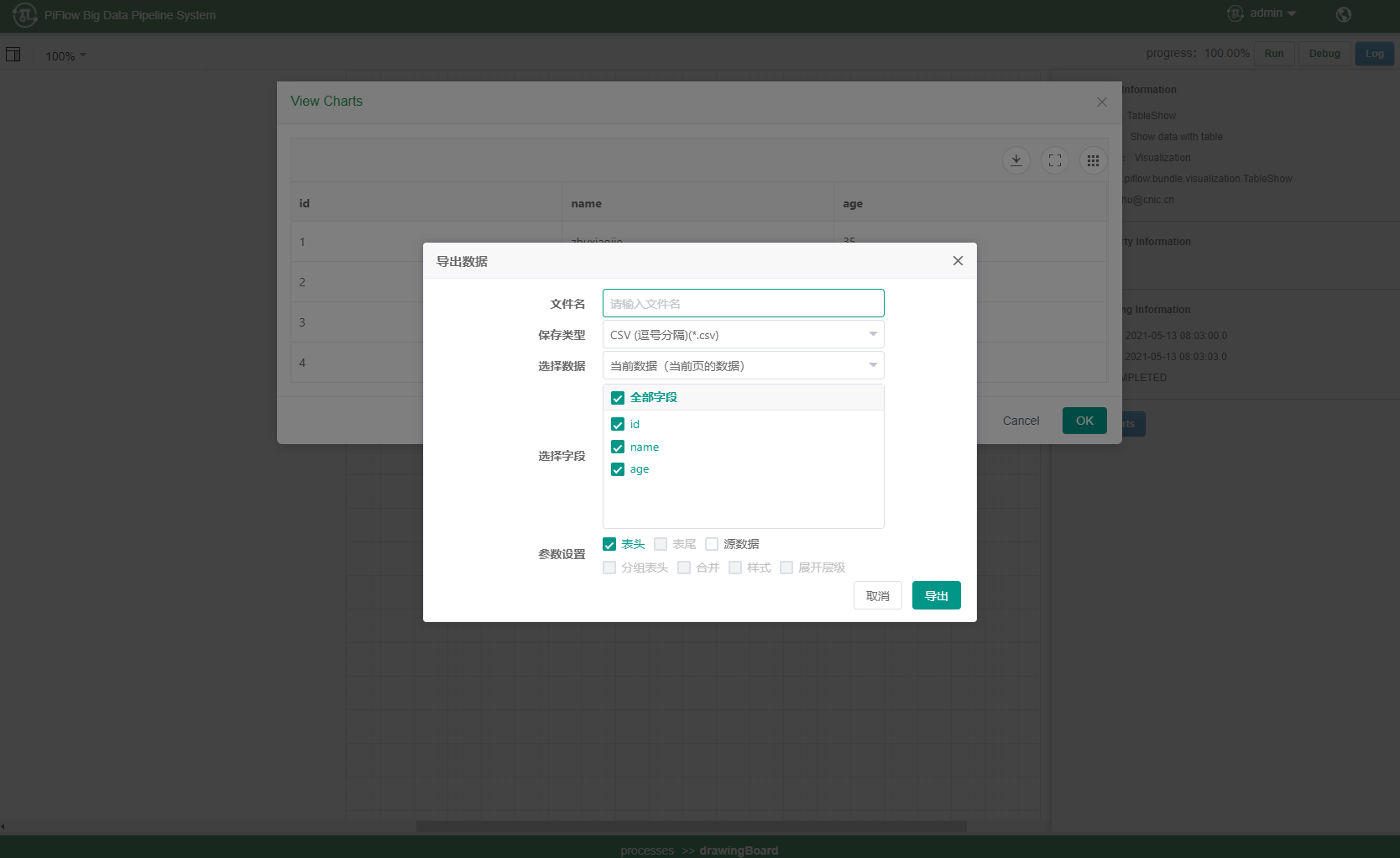
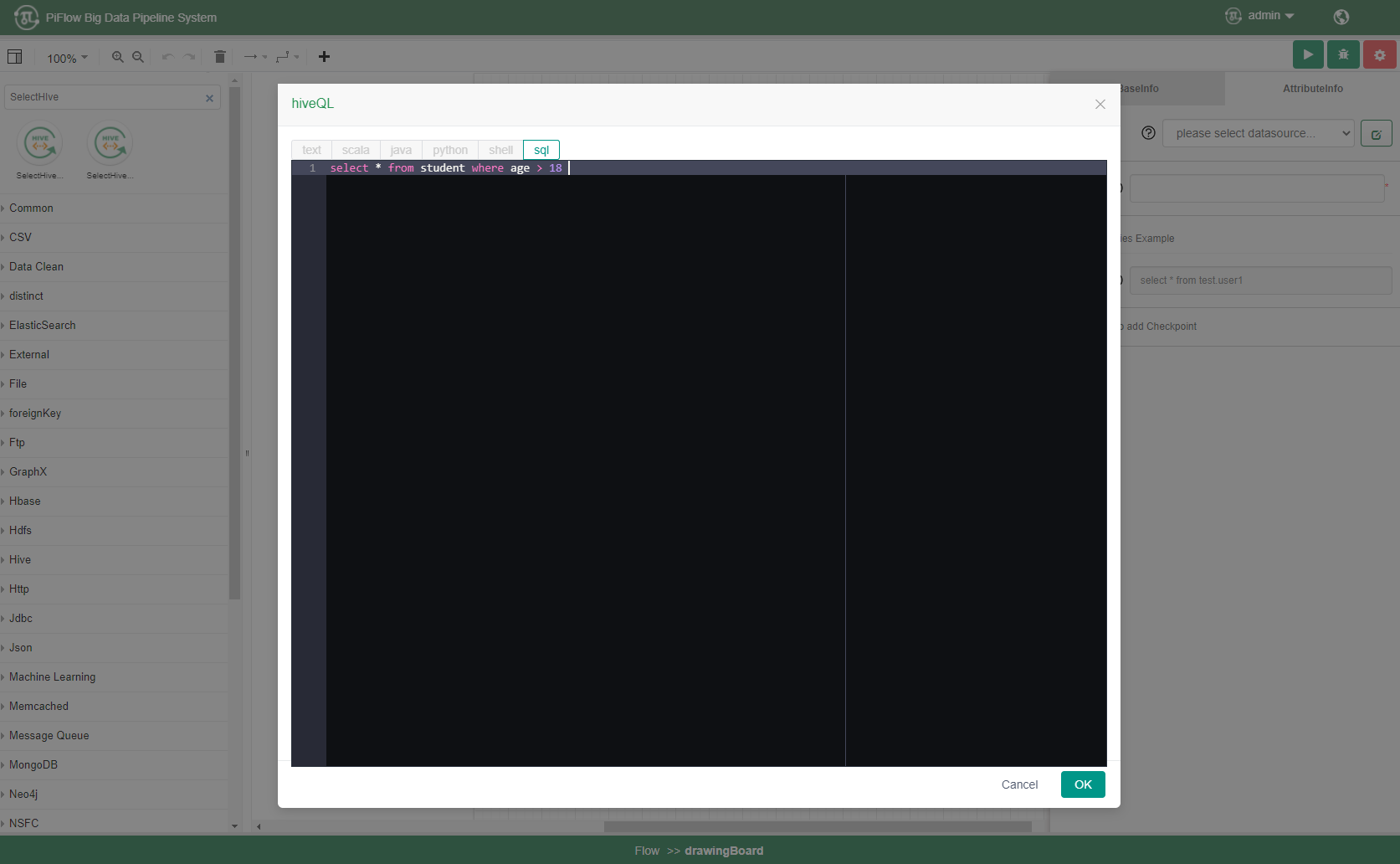
5)Sql编辑器
联系方式:18612673095(微信号)
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
- PiFlow v0.7 发布:大数据流水线系统
- PiFlow v0.8 发布,大数据流水线系统
- PiFlow v0.5 发布:大数据流水线系统
- PiFlow v0.5 发布:大数据流水线系统
- 开源大数据流水线系统 PiFlow V0.9 发布
- DevOps 测试流水线
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

互联网浪尖上的女性
田玉翠 / 人民出版社 / 2017-1 / 68.00
二十三个真实、前沿的女性创业者实例,带你走进“她世界”洞悉“她经济”。《互联网浪尖上的女性》不仅仅关于创业,更是关于女性如何追逐自己的梦想,让人生更丰满、更精彩。一起来看看 《互联网浪尖上的女性》 这本书的介绍吧!


