
Common Voice 是 Mozilla 的开源项目,基于 MPL 协议发行,到目前为止已经诞生了几年时间,它允许志愿者们为语音识别软件的数据库做出贡献,而这个数据库属于公共领域,所有人都可以将这些数据用于语音合成和识别软件。
今年 4 月,Nvidia 通过向 Mozilla 投资 150 万美元的方式参与了这项计划的合作。
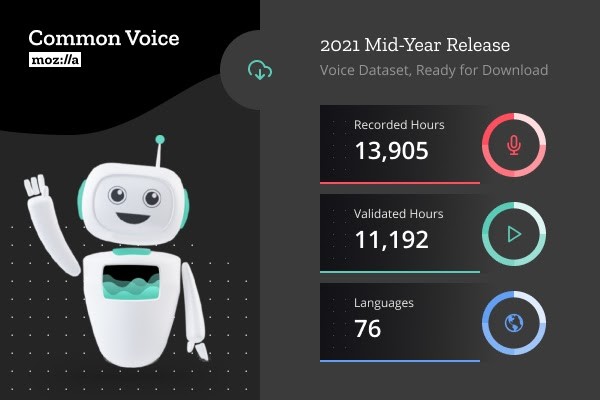
近日,在双方和整个社区的共同努力下,Common Voice 数据集的最新版本正式公开了。它带来了多项值得注意的新内容。首先,该语料数据集现在有超过 13000 小时的众包语音数据。与之前的版本相比,最新版本带来了 4622 小时的全新音频数据。还增加了 16 种新语言,即巴萨语、斯洛伐克语、北库尔德语、保加利亚语、哈萨克语、巴什基尔语、加利西亚语、维吾尔语、亚美尼亚语、白俄罗斯语、乌尔都语、瓜拉尼语、塞尔维亚语、乌兹别克斯坦语、阿塞拜疆语和豪萨语。这使得数据集中的语言总数达到了 76 种。总的来说,该数据集现在有超过 182,000 个独特的声音,过去六个月里贡献者社区增长了 25% 。
Mozilla 新发布的 Common Voice 数据集的其他内容包括:
- 按总时长排列的前五的语言是英语(2630 小时)、基尼亚卢旺达语(2260 小时)、德语(1040 小时)、加泰罗尼亚语(920 小时)和世界语(840 小时);
- 按百分比增加最多的语言是泰语(增长了 20 倍,从 12 小时增长到 250 小时),卢干达语(增长了 10 倍,从 8 小时到 80 小时),世界语(增长了 8 倍多,从 100 小时到 840 小时),以及泰米尔语(增长了 9 倍多,从 24 小时到 220 小时);
如果你有兴趣为 Common Voice 数据集做出贡献,可以访问项目官网参与这项计划,为项目添砖加瓦。想要将数据集用于相关项目开发的开发者可以在 GitHub 仓库中找到源代码和使用文档。作为 Mozilla 和 Nvidia 合作的一部分,在这个公共数据集上训练的模型可以通过 Nvidia NeMo 免费获得。
猜你喜欢:暂无回复。
