
北京时间2021年6月21日,全球顶级开源组织 Apache 软件基金会宣布,网易数帆开源的大数据项目 Kyuubi 以全票通过的表现,正式进入 Apache 软件基金会孵化器。根据投票结果,Kyuubi 获得了 13 个约束性投票(binding votes)和 8 个无约束性投票(non-binding votes),投票全部持赞同意见,无弃权票和反对票。
Kyuubi 是网易第一款贡献给 Apache 软件基金会进入孵化器的开源项目。开源至今,Kyuubi 已累积接受了 29 位国内外开发者超过 200 个以上的提交。当然,进入 Apache 孵化器只是一小步。未来, Kyuubi 社区将遵循「The Apache Way」, 打造更加多元化的生态和社区,由衷地欢迎更多的贡献者、用户能够参与到 Kyuubi 社区中来。
Kyuubi 系统介绍
Kyuubi 的命名源自中国神话《山海经》,意为“九尾狐”。狐会喷火,象征 Spark;狐有九尾,类比多租户,在 Spark 上实现多租户是系统设计之初的主要目的。然后我们取了《火影忍者》动漫中角色九尾的罗马音['kju????????],作为言简意赅的项目名称。Kyuubi 的最终目标是让“大数据平民化”。为实现这个目标,我们遵循“专业人做专业事”的准则,通过 Kyuubi的 C/S 架构,服务端大数据专家可以将 Spark 等大数据算力极致优化并高度封装后提供出来,业务端专家可通过该算力直接在自己擅长的业务领域处理数据产生价值,两者之间也通过简单的接口进行必要且有效的直接交互。
Kyuubi 使用场景
替换 HiveServer2,轻松获得 10~100 倍性能提升
-
Kyuubi 高度兼容 HiveServer2 接口及行为,支持无缝迁移
-
Kyuubi 分层架构,消除客户端兼容性问题,支持无感升级
-
Kyuubi 支持 Spark SQL 全链路优化及再增强,性能卓著
-
高可用、多租户、细粒度权限认证各种企业级特性统统都有
构建 Serverless Spark 平台
-
Serverless Spark 目标绝对不是让用户调用 Spark 的 API、继续写 Spark 作业
-
通过 Kyuubi 预置的 Engine 模块,用户无需理解 Spark 逻辑, 入门门槛极低
-
用户只需通过 JDBC 及 SQL 操作数据专注自身业务开发即可,资源弹性伸缩,0运维
-
支持资源管理器(Kubernetes, YARN等),Engine 生命周期,Spark 动态资源分配3级不同粒度全方位的资源弹性策略
-
支持 YARN/Kubernetes 多种资源管理器同时调度,保障历史作业安全迁移上云
-
Spark 自适应查询引擎(AQE)及 Kyuubi AQE plus,提供澎湃动力
构建统一数据湖探索分析管理平台
-
支持 Spark 所有官方数据源及第三方数据源
-
支持 Spark DSv2 元数据管理,直观进行数据湖构建及管理
-
支持 Apache Iceberg/Hudi, DeltaLake 等所有主流数据湖框架
-
一个接口一个引擎一份数据,提供统一的分析查询、数据摄取、数据湖管理平台
-
批流一体,支持流式作业(Upcoming)
致谢
Kyuubi 的成长和发展,尤其是进入 Apache 软件基金会孵化器,得到了来自各个组织的广大开源热爱者、贡献者以及终端用户的支持,在此特别感谢给 Kyuubi 提供指导的 Champion 和 Mentors:姜宁 Willem Ning Jiang 、章剑锋 Jeff Zhang、张铎 Duo Zhang、Akira Ajisaka。此外,也感谢提出 issue 和建议的伙伴们,以及国内外数十家企业用户的贡献与支持。
“很高兴 Kyuubi 项目得到 Apache 软件基金会的认可。Kyuubi 项目作为网易数帆‘人人用数据,天天用数据’理念的支撑技术,以及打造统一云原生操作系统的重要组件,我们把它捐献给 Apache 软件基金会,回馈社区,为普惠大数据贡献我们的力量。未来,网易数帆会在面向企业数字化的基础软件领域,和各个开源社区进行更加广泛和密切的合作。” -- 网易副总裁汪源
欢迎加入 Kyuubi 社区
Kyuubi 社区将践行"Community Over Code"的 Apache 社区文化,欢迎更多的组织和个人参与到 Kyuubi 社区建设,促进 Kyuubi 社区发展。
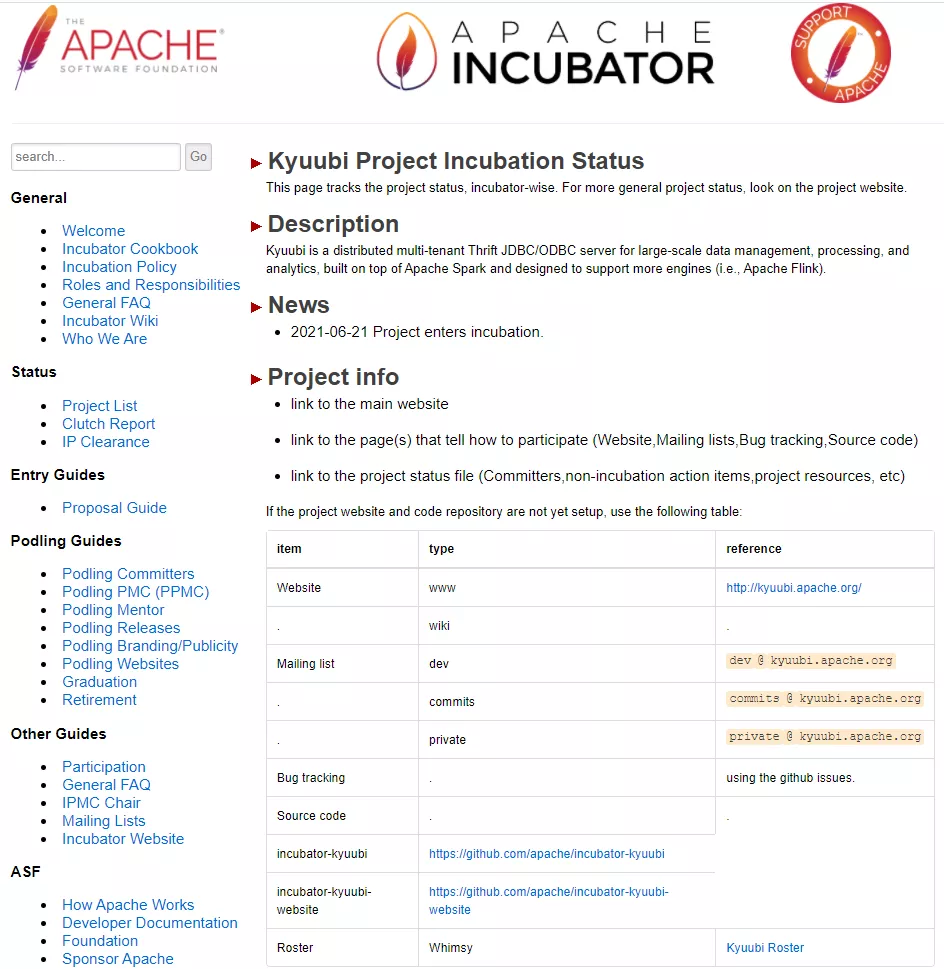
更多 Apache 孵化进展请参考:https://incubator.apache.org/projects/kyuubi
项目原始地址:https://github.com/NetEase/kyuubi
项目原始文档:https://kyuubi.readthedocs.io/en/latest/index.html
