
Facebook 宣布推出 wav2vec Unsupervised (wav2vec-U),一种建立根本不需要转录数据的语音识别系统的方法。并表示,它可以与几年前的最佳监督模型的性能相媲美,这些模型是在近 1000 小时的转录语音上训练出来的。他们已经用斯瓦希里语和鞑靼语等语言对 wav2vec-U 进行了测试;因为缺乏广泛的标记训练数据集,这些语言目前还没有高质量的语音识别模型。
该公司称,wav2vec-U 是 Facebook AI 在语音识别、自我监督学习和无监督机器翻译方面多年工作的成果。“这是朝着建立仅仅通过从观察中学习就能解决广泛任务的机器迈出的重要一步。我们认为这项工作将使我们更接近一个为更多人提供语音技术的世界。”
根据 Facebook 所述,其新颖的系统可以使技术摆脱对文本到语音输入的依赖。这项耗时的任务涉及人类聆听和转录数小时的音频,这是一个单调的过程,必须对每种语言进行重复。而 Facebook 的"无监督"系统则纯粹从语音音频和未配对的文本中学习,使其更好地了解人类交流的声音。
Facebook 的模型基本上依赖于由"generator"和"discriminator"组成的生成式对抗网络(GAN)之间的反馈回路。前者吐出上传的语音模式的表示,这些语音模式看起来完全是胡言乱语,直到它们被放入相应的鉴别器网络,后者则充当了某种翻译。同时,Facebook 还输入由人类编写的额外文本,以帮助生成器收集计算机化和真实世界结果之间的差异。这个过程不断重复,直到生成器的输出与真实文本相匹配。
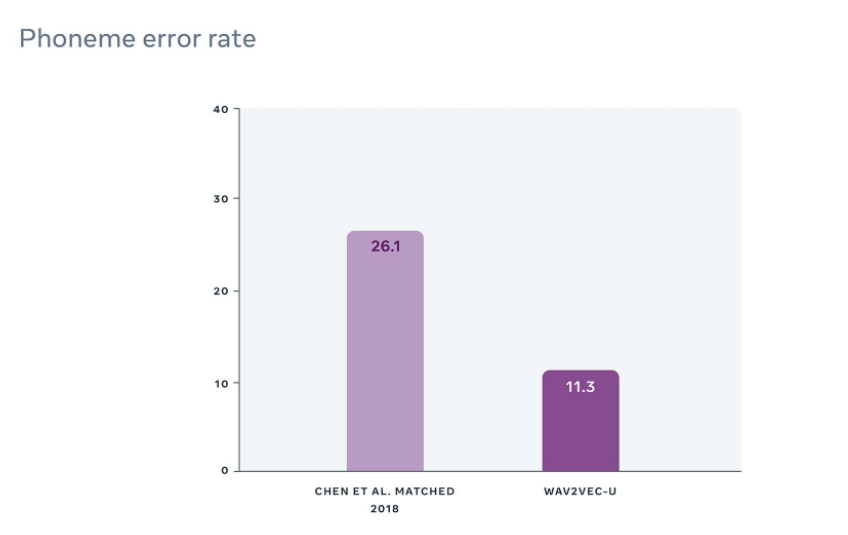
为了了解 wav2vec-U 的工作情况,Facebook 首先对 TIMIT 基准进行了评估。结果表明,与 TIMIT 基准测试中以前最好的无监督方法相比,wav2vec-U的错误率降低了 57%。
该公司表示,这一突破可以为全世界更多的语言和方言带来语音识别系统,帮助实现技术的民主化。
相关代码可查看:https://github.com/pytorch/fairseq/tree/master/examples/wav2vec/unsupervised
猜你喜欢: