
Vineyard 是一个专为云原生环境下大数据分析场景中端到端工作流提供内存数据共享的分布式引擎,我们很高兴宣布 Vineyard 在 2021 年 4 月 27 日被云原生基金会(CNCF)TOC 接受为沙箱(Sandbox)项目。
Vineyard 项目开源地址:https://github.com/alibaba/v6d
项目介绍
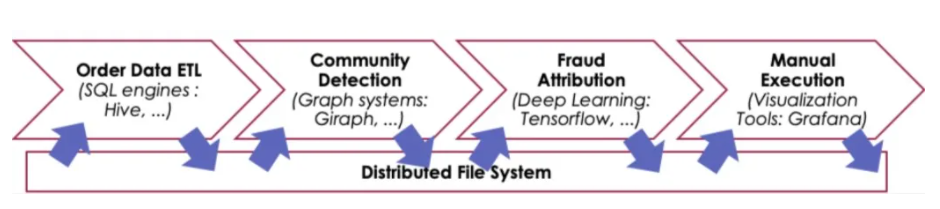
现有的大数据分析场景中,对于端到端任务,不同的子任务之间通常使用例如 HDFS、S3、OSS 这样的分布式文件系统或对象存储系统,来共享任务之间的中间数据,这种方式在运行效率和研发效率上存在诸多问题,以下图所示的一个风控作业工作流为例:
-
工作流中不同任务之间为了共享中间数据,前一个任务将结果写入文件系统,完成之后,后一个再将文件读出作为输入,这个过程带来了额外的序列化及反序列化、内存拷贝、以及网络、IO 的开销,我们从历史任务中观察到有超过 60% 的任务为此花费了 40% 以上的执行时间。
-
对于生产环境,为了高效地解决某一个特定范式的问题往往会引入一个新系统(例如分布式图计算),但这样的系统往往难以直接与工作流中的其他系统无缝衔接,需要很多重复的 IO、数据格式转换和适配的研发工作。
-
使用外部文件系统共享数据给工作流带来了额外的中断,因为往往只有当一个任务完全写完所有结果,下一个任务才能开始读取和计算,这使得跨任务的流水线并行无法被应用。
-
现有的分布式文件系统在共享中间数据时,特别是在云原生环境下,并没有很好的处理分布式数据的位置问题,造成网络开销的浪费,从而降低端到端执行效率。
为了解决现有大数据分析工作流中存在的上述问题,我们设计和实现了分布式内存数据共享引擎 Vineyard。
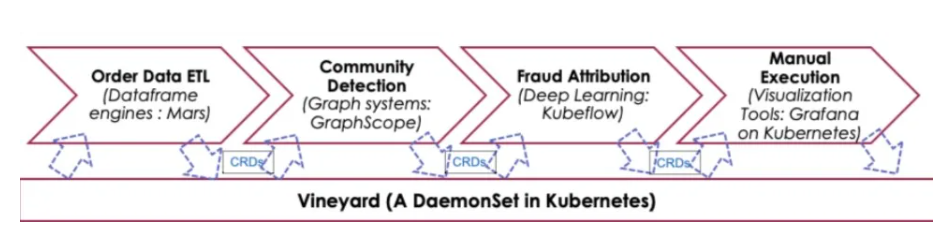
Vineyard 从以下三个角度来应对上述几个问题:
-
为了使端到端工作流中任务之间的数据共享更加高效,Vineyard 通过内存映射的方式,支持系统间零拷贝的数据共享,省去了额外的 IO 开销。
-
为了简化新计算引擎接入现有系统所需要的适配和开发,Vineyard 对常见的数据类型,提供了开箱即用的抽象,例如 Tensor、DataFrame、Graph,等等,从而不同计算引擎之间共享中间结果不再需要额外的序列化和反序列。同时,Vineyard 将 IO、数据迁移、快照等可复用的组件以插件的形式实现,使其能够很灵活地按需注册到计算引擎中去,降低与计算引擎本身无关的开发成本。
-
Vineyard 提供一系列 operators,来实现更高效灵活的数据共享。例如 Pipeline operator 实现了跨任务的流水线并行,使得后续任务可以随着前序任务输出的产生,同时进行计算,提高了端到端整体效率。
-
Vineyard 与 Kubernetes 集成,通过 Scheduler Plugin,让任务的调度能够感知所需要的数据的局部性,在 Kubernetes 让单个任务的 Pod 尽可能地调度到与 Pod 所需的输入数据对其的机器上,来减小数据迁移需要的网络开销,提升端到端性能。
在初步的对比实验中,相比于使用 HDFS 来共享中间数据,对于评测任务,Vineyard 能够大幅降低用于交换中间结果引入的额外开销,对于整个工作流的端到端时间有 1.34 倍的提升。
核心功能
接下来从 Vineyard 核心的设计与实现,以及 Vineyard 如何助力云原生环境中大数据分析任务两个方面来介绍 Vineyard 的核心功能。
1. 分布式内存数据共享
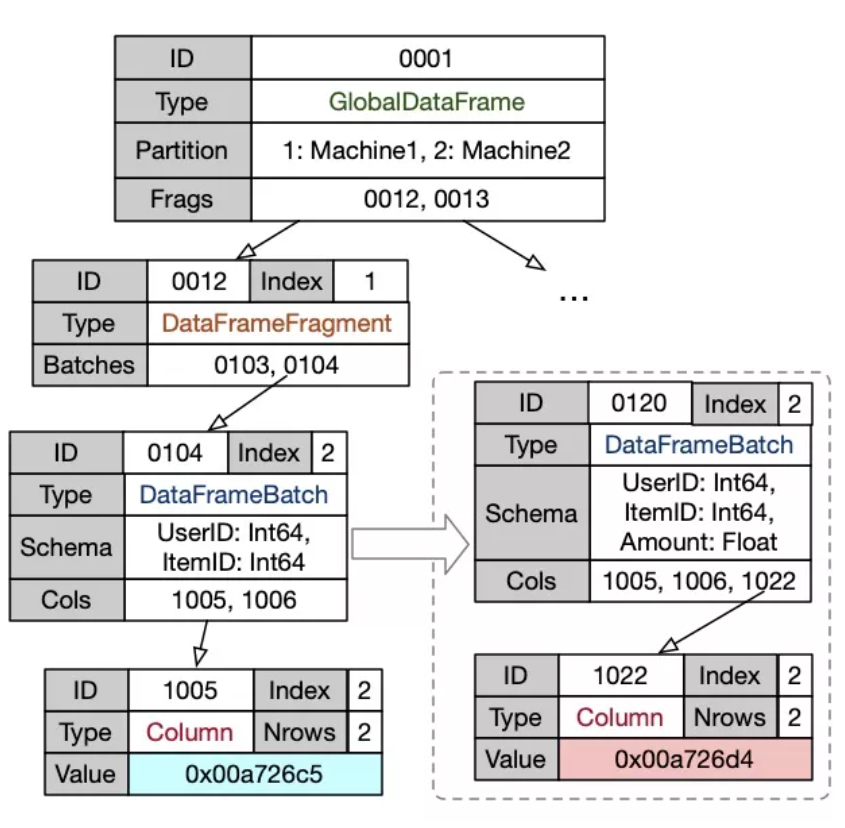
Vineyard 将内存中的数据表示为 Object。Object 可以是 Local 的,也可以是 Global 的,以分布式执行引擎 Mars 和 Dask 为例,一个 DataFrame 往往被拆分成很多个 Chunk 以利用多台机器的计算能力,每台机器上有多个 Chunk,这些 Chunk 是 Vineyard 中的 LocalObject,这些 Chunk 一起构成了一个全局的视图,即 GlobalDataFrame。这个 GlobalDataFrame 能够直接共享给其他计算引擎,如 GraphScope,作为图数据的输入。有了这些数据类型的抽象,Vineyard 上的不同计算引擎之间就可以无缝地共享中间结果,将一个任务的输出直接用作下一个任务的输出。
更具体地,Vineyard 中又是如果表达一个特定类型的 Object,使之能够很容易地适配到不同的计算引擎中去呢?这得益于 Vineyard 在 Object 的表示上提供的灵活性。Vineyard 中,一个 Object 包括两个部分,Metadata,以及一组 Blob。Blob 中存储着实际的数据,而 Metadata 则用于解释这些 Blob 的语义。例如对于 Tensor,Blob 是一段连续内存,存储着 Tensor 中所有的元素,而 Metadata 中记录了 Tensor 的类型、形状、以及行主序还是列主序等属性。在 Python 中,这个 Object 可以被解释为一个 Numpy 的 NDArray,而在 C++ 中,这个 Object 可以被解释为一个 xtensor 中的 tensor。这两种不同编程语言的 SDK 中,共享这个 Tensor 不会带来额外的 IO、拷贝、序列化/反序列化、以及类型转换的开销。
同时,Vineyard 中的 Metadata 是可嵌套的,这使得我们通过很容易地将任何复杂的数据类型描述为 Vineyard 中的 Object,不会限制计算引擎的表达能力。以 GlobalDataFrame 为例,见下图中 Metadata 的结构。
2. 云原生环境中数据与任务的协同调度
对于一个真实部署的大数据分析流水线,仅仅有任务之间的数据共享是远远不够的。在云环境中,一个端到端流水线中包含的多个子任务在被 Kubernetes 调度时仅仅考虑了需要的资源约束,连续的两个任务的 co-locate 无法保证,在两个任务之间共享中间结果时仍然有数据迁移引入的网络开销,如下图,在运行 Task B 时,因为两个任务的 Pod 没有对齐,数据分片 A3、A4 需要被迁移到 Pod 所在的 Vineyard 实例上。
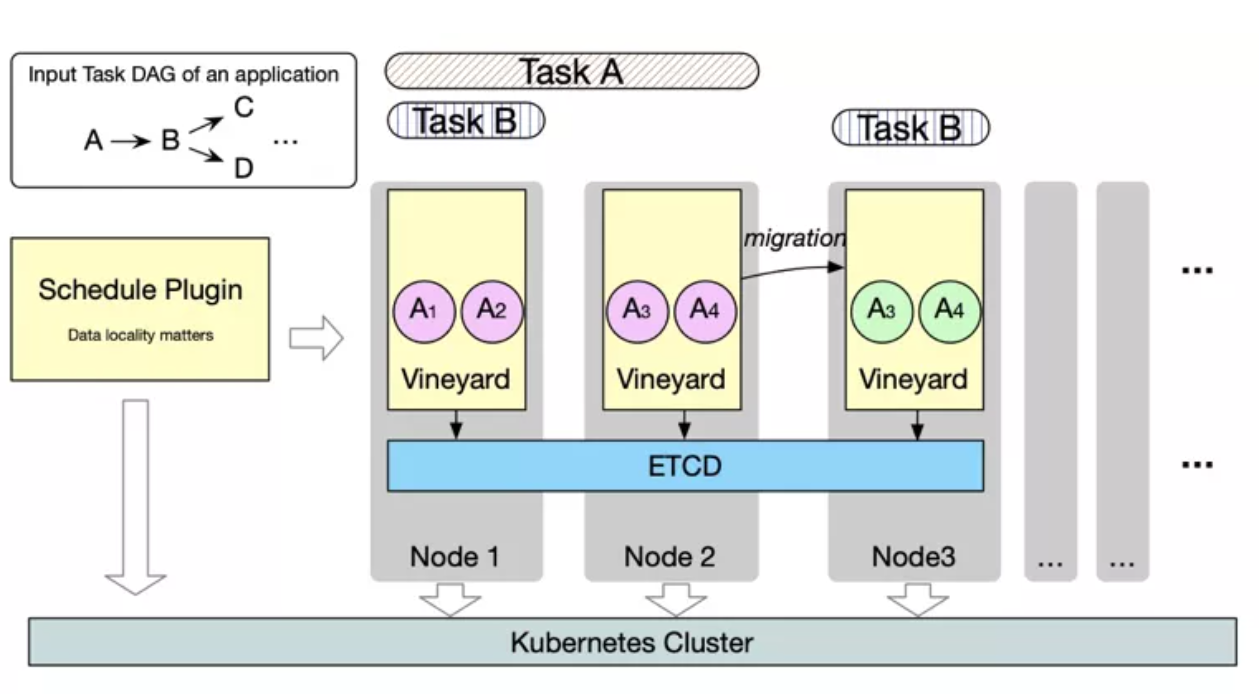
对此,Vineyard 通过 CRD 将集群中的数据(Vineyard Objects)表示为可观测的资源,并基于 Kubernetes 的 Scheduler Framework 设计和实现了一个考虑数据局部性的调度器插件。当前一个任务 Task A 完成后,从结果对象的 Metadata 中,调度器插件可以知道所有分片的位置,在启动下一个任务时,调度器给数据所在的节点(图中的 Node 1、Node 2)更高的优先级,使任务 Task B 也尽可能地被调度到对应的节点上,从而省去了数据迁移引入的额外开销,来改善端到端的性能。
快速上手
Vineyard 集成了 Helm 以方便用户安装和部署:
helm repo add vineyard https://vineyard.oss-ap-southeast-1.aliyuncs.com/charts/helm install vineyard vineyard/vineyard
安装之后,系统中会部署一个 Vineyard DaemonSet,并暴露一个 UNIX domain socket 用于与应用的任务 Pod 之间的共享内存和 IPC 通信。
此外,还可以参考 Vineyard 的演示视频:https://www.youtube.com/watch?v=vPbF1l5nwwQ&list=PLj6h78yzYM2NoiNaLVZxr-ERc1ifKP7n6&t=585
未来展望
Vineyard 已经作为分布式科学计算引擎 Mars 和一站式图计算系统 GraphScope 的存储引擎,Vineyard 助力大数据分析任务离不开与云原生社区的紧密互动,未来Vineyard 会进一步地完善与社区其他项目如 Kubeflow、Fluid 等的集成,助力更多云上大数据分析任务。
Vineyard 将继续与社区同行,支持关注社区的反馈,致力于推动云原生技术在大数据分析领域的生态建设和应用。欢迎大家关注 Vineyard 项目,加入 Vineyard 社区并参与项目的共建与落地!
猜你喜欢: