
消息队列的引入可以解决3个核心问题:
- 解耦
- 异步
- 削峰
解耦
在一个项目中,如果一个模块A产生的一个关键数据,需要调用其他模块接口服务;而需要调用的接口很多,又不确定之后是否还需要将数据传给其他模块的接口时。这时可以使用消息队列,使用了消息队列之后,模块A不需要在对接各个模块,而是直接对接消息队列。这样一来。当其他的模块需要这个数据时,也不用再修改A数据,而是去到MQ中订阅这个Topic。使得模块A与其他模块之间耦合度降低。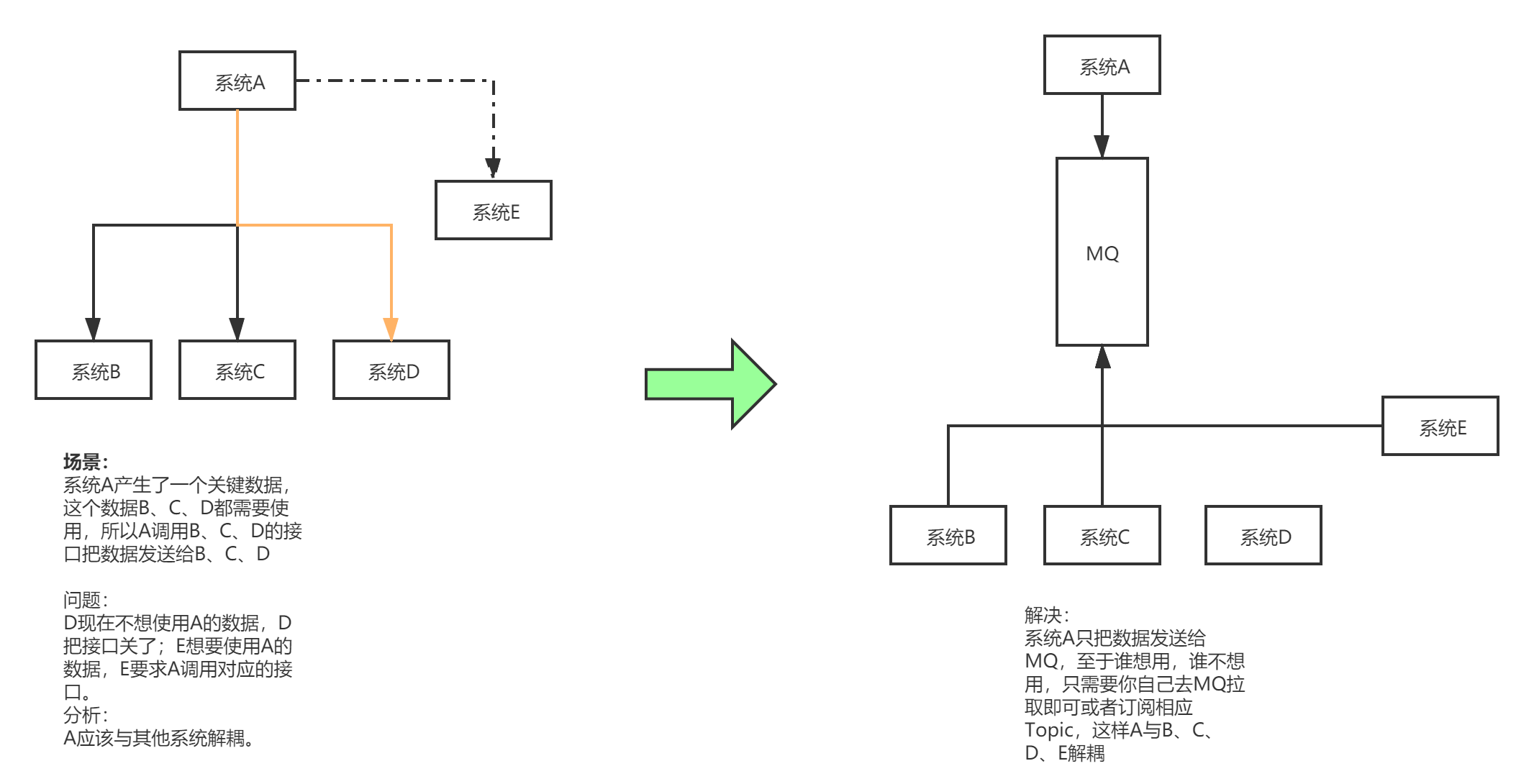
异步
在一个项目中,如果模块A的请求处理需要20ms,而模块A又依赖了模块B,模块C ,模块D 。在A请求处理结束后,A需要调用
模块B,C,D的对应请求处理,这时B请求处理需要100ms,C 需要200ms,D 需要400ms。这样一来,总体一个请求的总时长为
20 + 100 + 200 + 400 = 720 ms 远远大于模块A的请求处理时间。另一方面,模块B 模块C 模块D之间 并没有顺序关系。
这时可以引入消息队列 ,模块A在请求处理结束后,将自己的数据发送给消息队列MQ,由B,C ,D去消息队列获取数据,自行处理
模块A在处理完成后直接返回给客户端处理结果,而不需要等待B,C,D处理结束,如此一来,一个请求处理的就只需要计算
模块A的处理时间=20ms,大大提高了用户体验。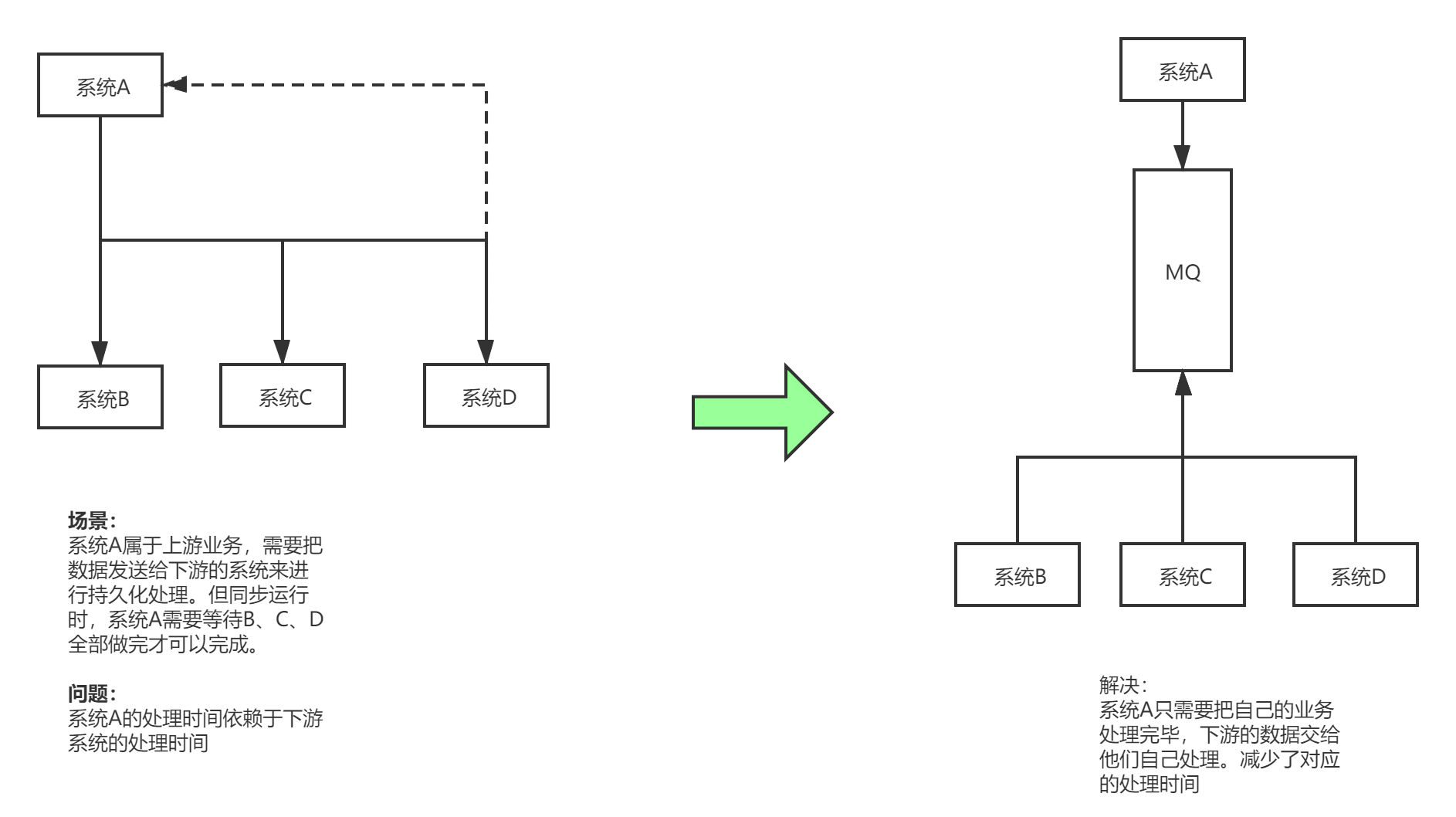
削峰
如果一个系统只能一秒钟处理5000个请求(MySQL一般只能2000QPS),而在特殊时期就只要1个小时的时间段内,请求量暴涨,一秒钟来了1W个请求。从而系统会之间宕机。但这种情况可能在平时不会发生,不需要升级相应的服务器配置。
问题在于在1小时的时间段,如何把请求从10000QPS 下降到5000QPS 使得系统能够正常运转而不发生宕机。
这时候可以引入消息队列,假设模块A负责处理请求,模块B负责将数据持久化到数据库。模块A在接受到请求时,把请求交给消息队列,由消息队列来缓解对应的请求压力,类似于Buffer建立一个缓冲区,模块B根据自己的请求处理速度去到消息队列中去消费数据。这样一来就解决了对应特定时间段的削峰问题。
要结合实际项目来说明:
体现上述的三个点。



为您推荐与 消息队列 相关的帖子:
