ElasticSearch Elasticsearch源码解读三:创建索引过程详解
前言
说明:本文章使用的ES版本是:6.7.0
在上一篇文章搜索引擎ElasticSearch的启动过程中,介绍了ES的启动过程。
由此可知,在ES启动过程中,创建Node对象(new Node(environment))时,初始化了RestHandler,由其名字可以知道这是用来处理Rest请求的。
在ES源码中,RestHandlerAction如下图:

其中:
- admin
- cluster:处理集群相关请求
- indices:处理索引相关请求
- cat:日常查询
- document:文档处理
- ingest:pipeline处理。pipeline?干嘛的
- search:搜索
接下来我们具体的看一下ES是如何创建索引的:org.elasticsearch.rest.action.document.RestIndexAction
数据概念和结构
一个完整的ES集群由以下几个基本元素组成
| 名称 | 概念 | 对应关系型数据库概念 | 说明 |
|---|---|---|---|
| Cluster | 集群 | 一个或多个节点的集合,通过启动时指定名字作为唯一标识,默认cluster-state | |
| node | 节点 | 启动的ES的单个实例,保存数据并具有索引和搜索的能力,通过名字唯一标识,默认node-n | |
| index | 索引 | Database | 具有相似特点的文档的集合,可以对应为关系型数据库中的数据库,通过名字在集群内唯一标识 |
| type | 文档类别 | Table | 索引内部的逻辑分类,可以对应为 Mysql 中的表,ES 6.x 版本中,一个索引只允许一个type,不再支持多个type。7.x版本中,type将废弃。 |
| document | 文档 | Row | 构成索引的最小单元,属于一个索引的某个类别,从属关系为: Index -> Type -> Document,通过id 在Type 内唯一标识 |
| field | 字段 | Column | 构成文档的单元 |
| mapping | 索引映射(约束) | Schema | 用来约束文档字段的类型,可以理解为索引内部结构 |
| shard | 分片 | 将索引分为多个块,每块叫做一个分片。索引定义时需要指定分片数且不能更改,默认一个索引有5个分片,每个分片都是一个功能完整的Index,分片带来规模上(数据水平切分)和性能上(并行执行)的提升,是ES数据存储的最小单位 | |
| replicas | 分片的备份 | 每个分片默认一个备份分片,它可以提升节点的可用性,同时能够提升搜索时的并发性能(搜索可以在全部分片上并行执行) |
一个ES集群的结构如下:

每个节点默认有5个分片,每个分片有一个备分片。
6.x版本之前的索引的内部结构:

说明:ES 6.x 版本中,相同索引只允许一个type,不再支持多个type。7.x版本中,type将废弃。
所以,6.x版本的索引结构如下:

7.x版本的索引结构如下:

索引一个文档
启动ES实例后,发送如下请求:
curl -X PUT 'localhost:9200/index_name/type_name/1' -H 'Content-Type: application/json' -d '
{
"title": "我是文件标题,可被搜索到",
"text": "文本内容,ES时如何索引一个文档的",
"date": "2019/01/01"
}'
其中:
- index_name:表示索引名称
- type_name:类别名称
- 1:文档ID
ES执行流程:
客户端:
BaseRestHandler#handleRequest:处理请求
RestIndexAction#prepareRequest:封装request,识别行为,允许的行为如下,默认INDEX
enum OpType { /** * Index the source. If there an existing document with the id, it will * be replaced. */ INDEX(0), /** * Creates the resource. Simply adds it to the index, if there is an existing * document with the id, then it won't be removed. */ CREATE(1), /** Updates a document */ UPDATE(2), /** Deletes a document */ DELETE(3); ... }参数检查,查看是否有关键字,并获取相关关键字的值
0 = "parent" 1 = "pretty" 2 = "version_type" 3 = "format" 4 = "index" 5 = "refresh" 6 = "error_trace" 7 = "type" 8 = "timeout" 9 = "pipeline" 10 = "routing" 11 = "if_seq_no" 12 = "if_primary_term" 13 = "wait_for_active_shards" 14 = "id" 15 = "op_type" 16 = "human" 17 = "filter_path"NodeClient#doExecute:指定执行该请求的actionName:
indices:data/write/indexTransportAction#execute():将请求封装成CreateIndexRequest并发送到服务端,处理发送前置任务
IndexRequest#validate:校验参数内容,type、source、contentType
这里如果是更新或者删除操作,检查是否传入ID字段,没传如则报错
if (opType() != OpType.INDEX && id == null) { addValidationError("an id is required for a " + opType() + " operation", validationException); }判断ID长度,最长不能超过512个字符
Transport层
Transport将request封装成Task,将请求发送给服务端
服务端
服务端根据actionName获取具体响应请求的action,此处为执行:TransportBulkAction#doExecute()
读取AutoCreateIndex#AUTO_CREATE_INDEX_SETTING,该值由配置文件
elasticsearch.yml中的
auto_create_index控制,true表示当插入的索引不存在时,自动创建该索引

- 如果”auto_create_index”为true:
- 分析bulkRequest中的所有请求中的所有index,生成Set indices,
- 然后遍历indices,判断索引名称是否存在
- 索引不存在:将请求转发给TransportCreateIndexAction#masterOperation,创建索引,且索引创建完成后,执行第2步
- 索引存在:启动异步进程BulkOperation,该进程将负责创建索引
- 如果”auto_create_index”为false,则索引不存在的写入文档的请求
- 如果”auto_create_index”为true:

TransportCreateIndexAction 创建索引过程
- 该类继承TransportMasterNodeAction,它会启动一个异步线程来执行任务,如果当前节点是master节点,则执行masterOperation,否则转发给master节点(每个节点在启动时会加入集群,同时保存完整的集群信息,该信息又Discovery模块维护)
- TransportCreateIndexAction将CreateIndexRequest转换为CreateIndexClusterStateUpdateRequest,将请求作为参数,调用MetaDataCreateIndexService#createIndex
- 调用MetaDataCreateIndexService#onlyCreateIndex,该方法负责在clusterstate中创建新的index,并且等待指定数目(默认为1)状态为active的分片副本创建完成(activeShardsObserver.waitForActiveShards方法实现),最终返回给listener。
- onlyCreateIndex方法,其内部执行clusterService.submitStateUpdateTask,提交集群状态修改任务,提交任务的执行逻辑是AckedClusterStateUpdateTask类内部的execute方法。其内部逻辑为:
- 校验index的名字和settings是否合法(比如index名不能有大写,如果有别名,判断是否有重名)
- 根据index name 查找合适的模板信息,即mapping
- 构建indexSettingsBuilder,可以认为是该索引的默认环境变量
- 准备工作完成,开始写入索引IndicesService#createIndex,写入索引的动作由IndexModule#newIndexService完成
- 为indicesService服务增加index服务,mapperService服务,同时合并新老mappings
- 构建IndexMetaData,并生成新的ClusterState
- 如果index状态open,执行allocationService.reroute将分片分配到其他节点
- 最后删除索引服务(indicesService.removeIndex)
- 上一步修改完成clusterstate后
- 如果是master节点同步集群状态(如果是master)
- 通知集群状态监听器listener,其他节点接收到集群状态变化,启动indicesService服务
BulkOperation 写入文档过程
获取最新的集群状态clusterstate
遍历request中的文档
获取文档操作类型OpType,写入文档
对文档做一些加工,主要包括:解析routing(如果mapping里有的话)、指定的timestamp(如果没有带timestamp会使用当前时间),如果文档没有指定id字段,会自动生成一个base64UUID作为id字段
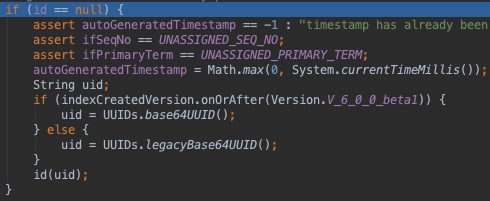
再次遍历所有的request,获取获取每个request应该发送到的shardId,获取的过程是这样的:如果上一步获取到了routing则取routing,否则取文档ID,取其hash值(哈希算法 Murmur3Hash)然后对当前索引的分片数量取模,得到分片ID:shardId
将相同分片的请求分组,将请求封装成BulkShardRequest,通过TransportBulkAction将请求发送到分片所在节点
请求转发到Node节点更新主分片,TransportReplicationAction.execute(),创建一个ReroutePhase异步线程,并执行,此处文档会写入主分片buffer中(InternalEngine#indexIntoLucene),最后并启动异步进程ReplicationPhase,更新副分片
至此,文档写入完成,但只是将数据写入内存buffer和transLog中,之后还有异步进程将数据refresh到索引中使其可搜索,将数据flush到磁盘

文档写入总结
- 通过副本分片和Translog日志保障数据安全和一致性
- 在可用性和一致性两者的取舍中,ES更看重可用性。主分片写入后,即可搜索。因此如果请求落到副分片可能出现不一致的情况,但是在搜索业务中,这种短时间的不一致大多是可以接受的
为您推荐与 elasticsearch 相关的帖子:
- Elasticsearch 9.0.4 版本发布
- Elasticsearch 8.12.2 发布
- Elasticsearch 8.13.1 发布
- Elasticsearch 8.13.2 发布
- Elasticsearch 8.13.3 发布
- Elasticsearch 7.17.22 发布
- Elasticsearch 8.14.2 发布
- Elasticsearch 8.15.2 发布
- Elasticsearch 8.15.3 发布
- Elasticsearch 8.11.3 发布
- Elasticsearch 9.1.0 发布
- Elasticsearch 9.1.1 发布
- Elasticsearch 9.1.2 发布
- Elasticsearch 9.1.3 发布
- Elasticsearch 9.1.4 发布
- Elasticsearch 9.2.3 发布
- Elasticsearch 9.2.4 发布
- 全文搜索引擎 Elasticsearch 入门教程
- Elasticsearch 8.11.1 发布
- Elasticsearch 8.10.1 发布
- Elasticsearch 7.17.13 和 8.9.2 版本发布
- Elasticsearch 8.8.0 发布
- Elasticsearch 8.7.0 发布
- Elasticsearch 8.6.2 发布
- Elasticsearch 7.17.9 发布
- Elasticsearch v8.4.2 已发布,全文搜索引擎
- Elasticsearch v8.3.3 已发布
- Elasticsearch 8.3.0 发布
- Elasticsearch源码解读六:ES中的倒排索引
- Elasticsearch源码解读五:搜索相关性排序算法详解
