一、常见的树结构:
二叉树:每个父节点大于左孩子节点,小于右孩子节点 。
平衡二叉树:二叉树的基础上,每个节点的子树高度差不大于1 。
BTree:是一种平衡多路搜索树,另外并保证了每个叶子结点到根节点的距离相同,每个节点保存了data
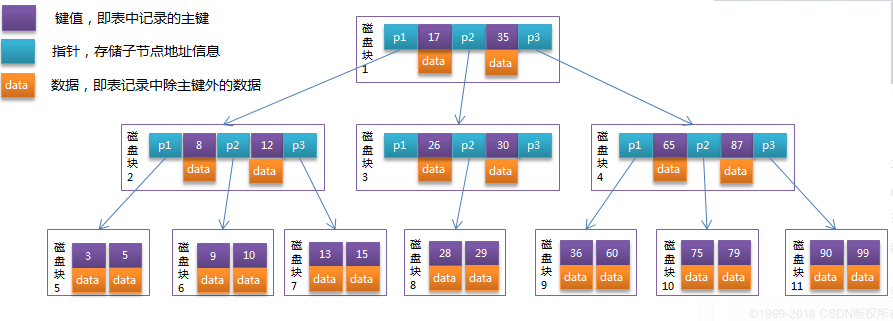
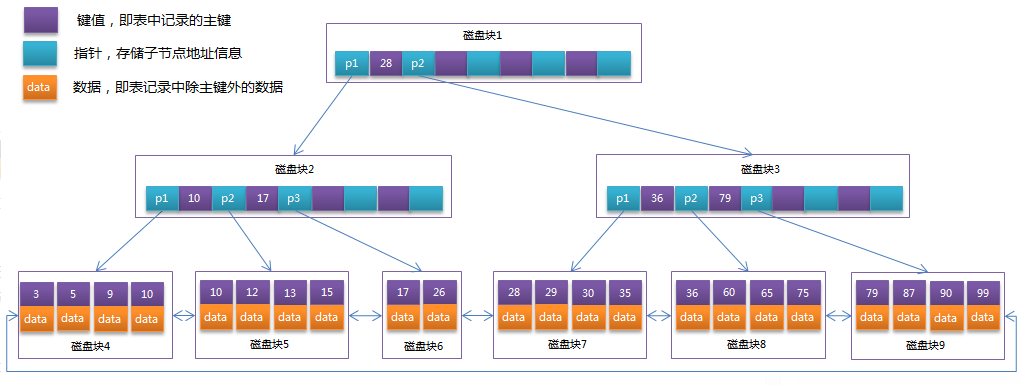
B+Tree:非叶子结点只存放key,叶子节点存储key,data.叶子节点可以包含一个指针指向另一个叶子节点以加速顺序存取。


二、MySql存储引擎
- InnoDB存储引擎 当前MySQL存储引擎中的主流,InnoDB存储引擎支持事务、支持行锁、支持非锁定读、支持外键。
- MyISAM存储引擎 MyISAM不支持事务,不支持行级锁,支持表锁(效率低),支持全文索引,最大的缺陷是崩溃后无法安全恢复。
在InnoDB和MyISAM中索引都采用了B+Tree结构,但是实现方式并不相同:
- 在MyISAM中叶子节点的data域并不存放数据而是存放数据记录的地址,所以MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
- 在InnoDB中有聚集索引和非聚集索引(辅助索引):
- 聚集索引:非叶子结点存放的是<key,point>,point就是指向下一层的指针。 叶子结点保存了这一行的信息,因此通过主键索引可以快速获取数据。InnoDB中通常主键就是一个聚集索引。准确来说聚集索引并不是某种单独的索引类型,而是一种数据存储方式。就是指在同一个结构中保存了B+tree索引以及数据行。 innoDB中,用户如果没有设置主键索引,会随机选择一个唯一的非空索引替代, 如果没有这样的索引,会隐式的定义一个主键作为隐式的聚集索引。
- 非聚集索引:非聚集索引的叶子结点并没有存放数据,而是存储相应行数据的聚集索引键,即主键。当通过非聚集助索引来查询数据时,InnoDB存储引擎会遍历非聚集索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
三、总结
使用B+Tree作为索引结构的原因:
- B-Tree每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
四、MySql常用优化
1.索引失效的情况
- 以%开头的like查询
- (is not null, not like)不会使用索引
- 如果条件中有or,即使其中有部分条件带索引也不会使用
- where 子句里对索引列上有数学运算或者使用函数,用不上索引
- 索引列的数据类型存在隐形转换则用不上索引。比如字符串,那一定要在条件中将数据使用引号引用起来
- 联合索引不符合最左匹配原则
2.sql优化
- 分解关联查询:将关联(join)放在应用中处理,执行简单的sql,好处是:分解后的 sql 通常由于简单固定,能更好的使用mysql缓存。还可以可以减少锁的竞争。
- SELECT子句中避免使用*号 ,它要通过查询数据字典完成的,意味着将耗费更多的时间,而且SQL语句也不够直观。
- 关于Limit 在使用Limit 2000,10这种操作的时候,mysql会扫描偏移量(2000条无效查询)数据,而只取后10条,尽量想办法规避。
- 通常情况下,使用一个性能好的sql代替使用多个sql。除非这个sql过长效率低下或者对于delete这种语句,过长的delete会导致太多的数据被锁定,耗尽资源,阻塞其他sql。
- WHERE子句中的连接顺序 数据库采用自右而左的顺序解析WHERE子句,所以那些可以过滤掉最大数量记录的条件最好写在WHERE子句的最右。
- 选择最有效率的表名顺序 数据库的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表将被最先处理 在FROM子句中包含多个表的情况下: 如果是完全无关系的话,将记录和列名最少的表写在最后。如果是有关系的话,将引用最多的表,放在最后。
- 删除全表数据用TRUNCATE替代DELETE 这里仅仅是:DELETE是一条一条记录的删除,而Truncate是将整个表删除,保留表结构,这样比DELETE快
- 多使用内部函数提高SQL效率
- 使用表或列的别名,使用简短的别名也能稍微提高一些SQL的性能。毕竟要扫描的字符长度变少了
- 用 >= 替代 > ,低效:> 3首先定位到=3的记录并且扫描到第一个大于3的记录。高效:>= 4 直接跳到第一个等于4的记录
- 用IN替代OR
3. 数据库结构优化
- 表结构优化:字段尽量使用非空约束,因为在MySql中含有空值的列很难进行查询优化,NUll值会使索引以及索引的统计信息变得很复杂
- 数值类型的比较比字符串类型的比较效率要高得多,
- 尽量使用TIMESTAMP而非DATETIME(查询效率)
- 单表不要有太多的字段,建议在20以内
- 合理加入冗余字段
- 垂直表拆分 水平表拆分
为您推荐与 mysql优化 相关的帖子:
暂无回复。
