内容简介:刚刚 GitHub 通过官方博客发布了 21 日“挂掉”的事件分析。 GitHub 指出此次事件发生的原因是在 10 月 21 日 22:52 UTC 进行日常维护——更换发生故障的 100G 光纤设备时导致美国东海岸网络中心与美国东海岸数据...
刚刚 GitHub 通过官方博客发布了 21 日“挂掉”的事件分析。
GitHub 指出此次事件发生的原因是在 10 月 21 日 22:52 UTC 进行日常维护——更换发生故障的 100G 光纤设备时导致美国东海岸网络中心与美国东海岸数据中心之间的连接断开。

更具体地,GitHub 分析,虽然两地的连接在 43 秒内恢复,但这次短暂的中断引发了一系列事件,这才导致了长达 24 小时 11 分钟的服务降级。
为了大规模提高性能,GitHub 的应用程序将直接写入每个群集的相关主数据库,但在绝大多数情况下将读取请求委派给副本服务器的子集。GitHub 使用 Orchestrator 来管理 MySQL 集群拓扑并处理自动故障转移,Orchestrator 在此过程中考虑了许多变量,并在 Raft 共识机制之上达成共识。Orchestrator 可以实现应用程序无法支持的拓扑,因此必须注意将 Orchestrator 的配置与应用程序级别的期望保持一致。
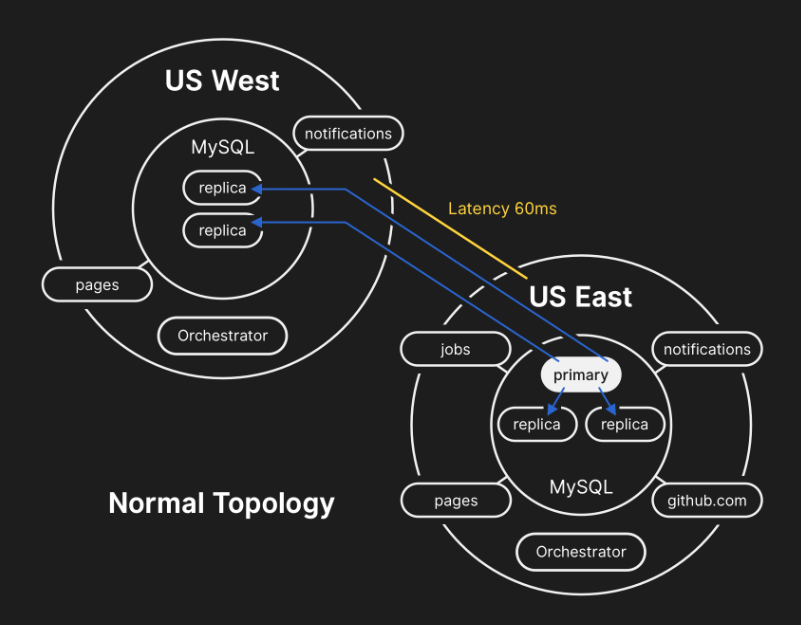
然而 21 日,在网络分区过程中,Orchestrator 在主数据中心根据 Raft 的共识机制,执行了取消领导的选举(leadership deselection)。美国西海岸数据中心和美国东海岸公有云 Orchestrator 节点获得合规票数,并开始对群集进行故障转移,将写入指向美国西海岸数据中心。Orchestrator 继续组织美国西海岸数据库集群拓扑,当连接恢复时,应用层立即开始将写入流量引导到西海岸站点的新当选主节点上。
美国东海岸数据中心的数据库服务器包含一小段时间的写入数据,它们尚未复制到美国西海岸的设施。由于两个数据中心中的数据库集群都包含了其它数据中心中不存在的写入数据,因此无法安全地将主数据库故障转移到美国东海岸数据中心。
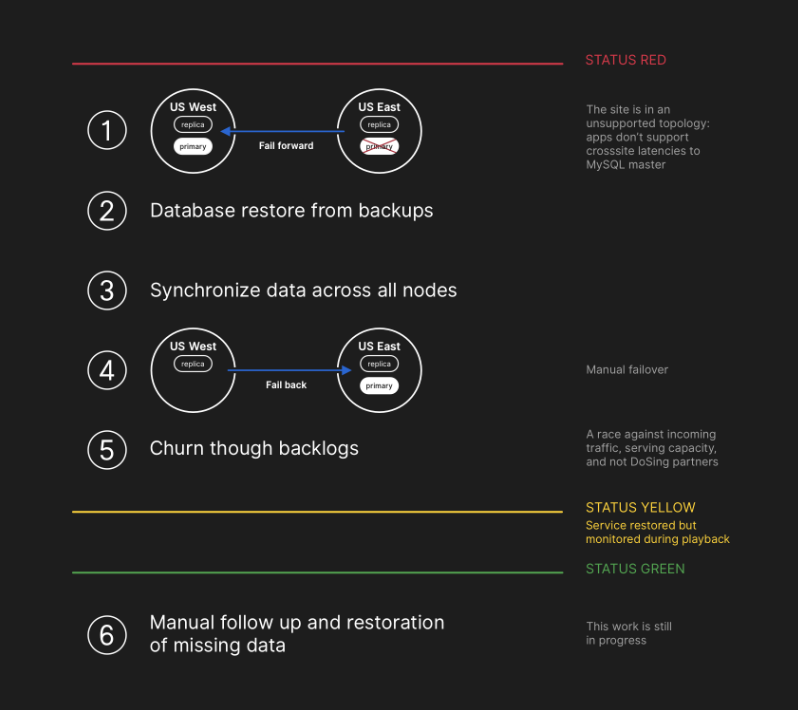
GitHub 工程师发现问题后进行了一系列抢救措施,“最终没有用户数据丢失,但是,几秒钟的数据库写入的手动协调仍在进行中。”
而之所以服务降级时间长达 24 小时 11 分,是因为在此次事件中,GitHub 的策略是优先考虑用户数据完整性,而不是站点可用性和恢复时间。
GitHub 对所有受影响的用户表示歉意,并表示“我们已经吸取了教训,并且采取了一系列措施,我们希望更好地确保不再发生类似情况。”
同时 GitHub 也表示接下来将进一步解决由此导致的数据不一致问题。
详细分析与事件时间线请查阅 GitHub 公告。
【声明】文章转载自:开源中国社区 [http://www.oschina.net]
以上所述就是小编给大家介绍的《GitHub 发布 10 月 21 日系统故障分析报告》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
猜你喜欢:
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

应用Rails进行敏捷Web开发
Dave Thomas, David Hansson等 / 林芷薰 / 电子工业出版社 / 2006-7 / 65.00元
这是第一本关于Ruby on Rails的著作。 全书主要内容分为两大部分。在“构建应用程序”部分中,读者将看到一个完整的“在线购书网站” 示例。在演示的过程中,作者真实地再现了一个完整的迭代式开发过程,让读者亲身体验实际应用开发中遇到的各种问题、以及Rails如何有效解决这些问题。在随后的“Rails框架”部分中,作者深入介绍了Rails框架的各个组成部分。尤为值得一提的是本部分的后几章......一起来看看 《应用Rails进行敏捷Web开发》 这本书的介绍吧!

Base64 编码/解码
Base64 编码/解码

XML 在线格式化
在线 XML 格式化压缩工具