内容简介:spark中有两种共享变量。分别为广播变量和累加器。广播变量主要用于高效分发较大的数据对象,累加器主要用于对信息进行聚合。广播变量允许我们将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。
spark两种共享变量
spark中有两种共享变量。分别为广播变量和累加器。
广播变量主要用于高效分发较大的数据对象,累加器主要用于对信息进行聚合。
广播变量
广播变量允许我们将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。
广播的数据被集群不同节点共享,且默认存储在内存中,读取速度比较快。
Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。
Spark的动作通过一系列的步骤执行,这些步骤由分布式的shuffle操作分开。Spark自动地广播每个步骤每个任务需要的通用数据。这些广播数据被序列化地缓存,在运行任务之前被反序列化出来。这意味着当我们需要在多个阶段的任务之间使用相同的数据,或者以反序列化形式缓存数据是十分重要的时候,显式地创建广播变量才有用。
累加器是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。它可以被用来实现计数器和总和。Spark原生地只支持数字类型的累加器。我们可以自己添加新类型。
提供了将工作节点中的值聚合到驱动器程序中的简单语法。
广播变量的使用
广播变量引入的原因
Spark 会自动把闭包中所有引用到的变量发送到工作节点task上。假如你可能会在多个并行操作中使用同一个变量,但是 Spark 会为每个操作分别发送。
例如下面一段伪代码:
val sparkConf: SparkConf = new SparkConf().setAppName("test").setMaster("local[2]")
//创建SparkContext
val sc = new SparkContext(sparkConf)
//读取日志数据,获取 相关信息
val test_data= sc.textFile("D:\\tmp\\test_data.txt").map(_.split("\\|"))
val ips = sc.textFile("D:\\tmp\\http.format").map(_.split("\\|")(1))
//遍历ips中每一条数据,获取每一个ip值
val result:RDD[((String,String),Int)]=ips.mapPartitions(iter=>{
val array = test_data.contains(iter)
}).foreach(println)
test_data是任务执行需要的一份共同数据。假如test_data比较大,为1G,需要共500个task去运行,默认spark的driver会将test_data中的数据,以task的形式发送到executor,加载到executor端设备的内存中。则会导致需要内存为500*1G=500G,而我们的设备不可能提供这么大的内存,则会导致内存溢出。于是便引入了广播变量。
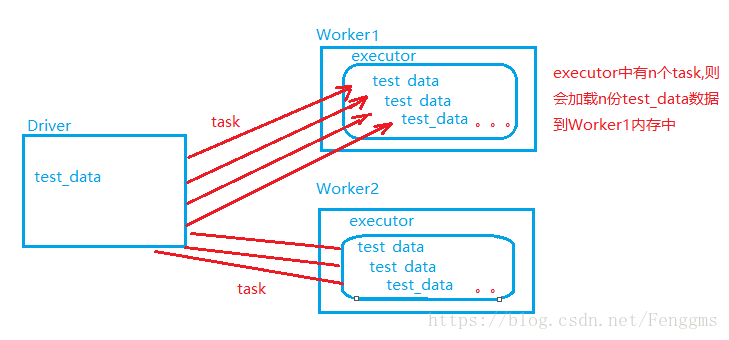
广播变量,会将这份共同数据test_data通过driver端下发给每一个executor进程中,而不是给每个task进行发送。后期task在执行时,直接共享executor中这份数据即可。这样就可以减少内存的开销。
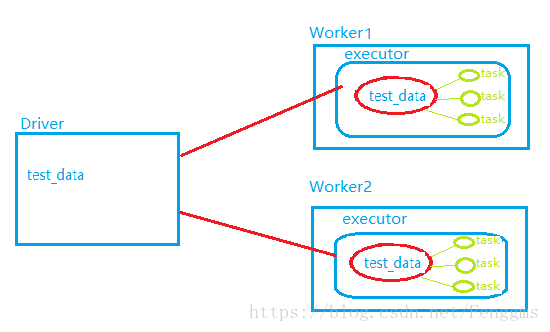
广播变量的使用
(1) 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
(2) 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
val sparkConf: SparkConf = new SparkConf().setAppName("test").setMaster("local[2]")
//创建SparkContext
val sc = new SparkContext(sparkConf)
//读取日志数据,获取 相关信息
val test_data= sc.textFile("D:\\tmp\\test_data.txt").map(_.split("\\|"))
val test_data_broadcast = sc.broadcast(test_data.collect())
val ips = sc.textFile("D:\\tmp\\http.format").map(_.split("\\|")(1))
//遍历ips中每一条数据,获取每一个ip值
val result:RDD[((String,String),Int)]=ips.mapPartitions(iter=>{
val array = test_data_broadcast.value.contains(iter)
}).foreach(println)
广播变量的其他说明
不能将一个RDD使用广播变量进行广播出去,因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Drvier端定义。
在Drvier端可以修改广播变量的值。在Executor端无法修改广播变量的值。在Executor端,广播变量时只读的。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
- Spark 共享变量
- Python多线程-共享全局变量
- Hystrix 跨线程共享变量 原 荐
- python使用锁访问共享变量实例解析
- Go笔记之基于共享变量的并发
- golang笔记之基于共享变量的并发
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Essential PHP Security
Chris Shiflett / O'Reilly Media / 2005-10-13 / USD 29.95
Being highly flexible in building dynamic, database-driven web applications makes the PHP programming language one of the most popular web development tools in use today. It also works beautifully wit......一起来看看 《Essential PHP Security》 这本书的介绍吧!


