内容简介:Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构Hadoop 底层用Java语言、跨平台性,可以部署在廉价的计算机集群中。Hadoop在分布式环境下提供了海量数据的处理能力
Hadoop简介:
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
Hadoop 底层用 Java 语言、跨平台性,可以部署在廉价的计算机集群中。
Hadoop在分布式环境下提供了海量数据的处理能力
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化 工具 和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
Hadoop核心:
Hadoop组成:
- 分布式文件系统 HDFS(Hadoop Distributed File System) | 存储系统
- 分布式计算 MapReduce | 并行运算框架
Hadoop的特性:
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在 Linux 平台上
- 持多种编程语言
Hadoop1 生态系统架构
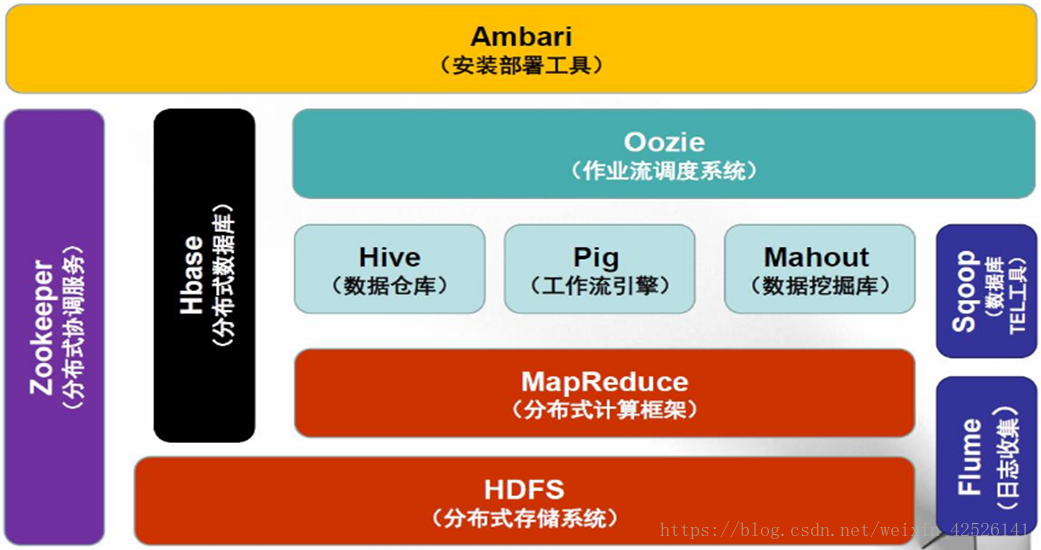
- Hdfs: 构建于廉价计算机集群之上的分布式文件系统,低成本、高可靠性、高吞吐量
- Mapreduce: 分布式编程模型和软件框架,用于在集群上编写对海量数据处理的并行化程序
- Common: 整体架构提供基础支撑性功能,主要包括了文件系统、RPC和数据串行化库
- Hive: 数据仓库工具,将结构化数据文件映射为库表,并提供强大的类 SQL 查询功能
- Hbase: 分布式的、面向列的数据库,是一个适合于非结构化海量数据存储的数据库
- Pig: 适合海量数据分析的脚本语言工具,包括了一个数据分析语言和支持的运行环境
- Sqoop: 在Hadoop与传统数据库间进行数据交换的工具,支持两者之间的数据导入和导出
- Zookeeper: 维护Hadoop集群的配置和命名信息,并提供分布式锁同步功能和群组管理功能
- Ambari: 安装、管理和监控Hadoop集群的Web界面工具。目前已支持大部分组件的管理,就 Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群
Hadoop完全分布模式安装
step 0: 此步为可选项,建议用户创建一个新用户及用户组,后续的操作基本都是在次用户下来操作。但是用户亦可在自己当前非root用户下进行操作。创建一个用户,名为zhangyu,并为此用户创建home目录,此时会默认一个与zhangyu同名的用户组。
- 了解hadoop的完全分布式安装与伪分布式安装,单机安装的区别
- 了解hadoop的集群搭建流程
sudo useradd ‐d /home/zhangyu ‐m zhangyu
为zhangyu用户设置密码,执行下面的语句
sudo passwd zhangyu
按提示消息,输入密码以及确认密码即可,此处密码设置为zhangyu,将zhangyu用户的权限,提升到sudo超级用户级别
sudo usermod ‐G sudo zhangyu
后续操作,我们需要切换到zhangyu用户下来进行操作。
su ‐ zhangyu
step 1:添加hosts的地址映射,用ifconfig 或 ip a 命令获取三台服务器的ip地址;
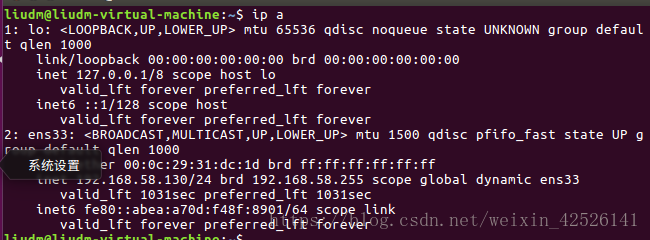
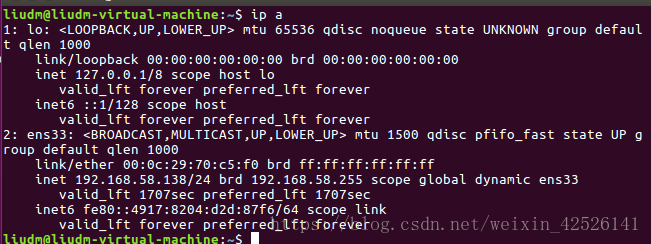
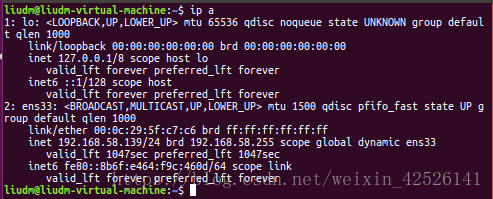
将他们的IP地址和对应的映射名都添加到三台服务器上的/etc/host 文件里
sudo vim /etc/hosts
192.168.58.130 master 192.168.58.138 slave1 192.168.58.139 salve2
添加到192.168.58.130服务器master上
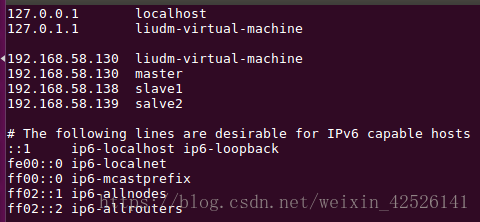
添加到192.168.58.138服务器slave1上
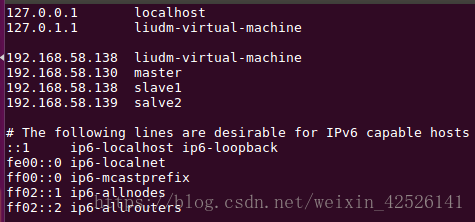
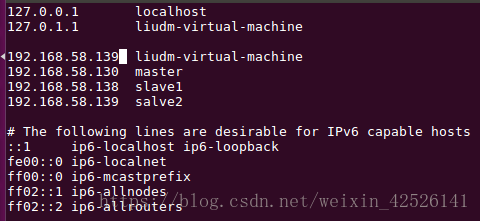
添加到192.168.58.139服务器slave2上
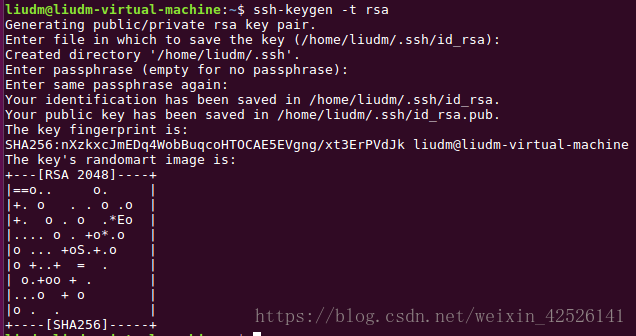
step 2 :首先来配置SSH用于集群间免密码登陆,SSH免密码登陆需要在三台服务器执行以下命令,生成公钥和私钥对
ssh‐keygen ‐t rsa
此时会有多处提醒输入,在冒号后输入文本,这里主要是要求输入 ssh密码以及密码的放置位置。在这里,只需要使用默认值,按回车即可。(一路Enter~~~
拷贝公钥到各个节点,包括本机,过程中需要输入用户的密码
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- 大数据学习 | 初识 Hadoop
- 大数据学习(一) | 初识 Hadoop
- Python 数据结构与算法 —— 初识算法
- 数据分析——SPSS基本操作初识
- 0基础搭建Hadoop大数据处理-初识
- 大数据系列——Spark学习笔记之初识Spark
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。



