内容简介:Uber 近日宣布开源 Petastorm,这是由 Uber ATG 开发的数据访问库,可直接基于数 TB 的 Apache Parquet 格式数据集进行单机或分布式训练和深度学习模型评估。Petastorm支持流行的基于Python的机器学习(ML)框架,...
Uber 近日宣布开源 Petastorm,这是由 Uber ATG 开发的数据访问库,可直接基于数 TB 的 Apache Parquet 格式数据集进行单机或分布式训练和深度学习模型评估。Petastorm支持流行的基于 Python 的机器学习(ML)框架,如 Tensorflow、Pytorch 和 PySpark ,也可以直接用在 Python 代码中。

通常,我们通过连接来自多个数据源的记录来生成数据集。该数据集由 Apache Spark 的 Python 接口 PySpark 生成,稍后将被用在机器学习训练中。Petastorm 提供了一个简单的功能,可以使用 Petastorm 特定的元数据扩展标准的 Parquet ,从而使其与 Petastorm 兼容。
使用 Petastorm ,消耗数据就像在 HDFS 或文件系统路径创建和迭代读取对象一样简单。Petastorm 使用 PyArrow 库来读取 Parquet 文件。过程概述图如下:
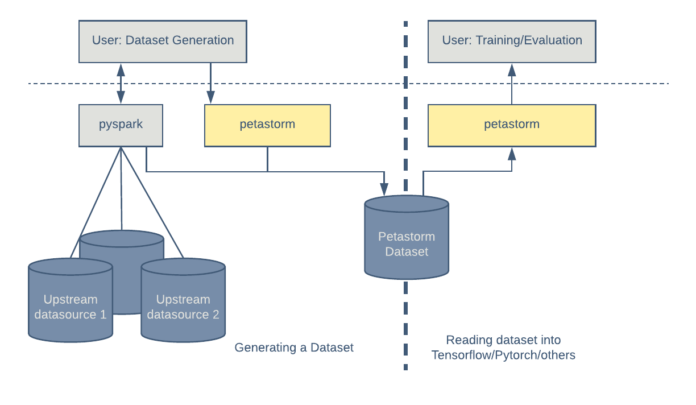
Petastorm 结合了各种特性以支持自动驾驶算法的训练,包括行过滤、数据分片、shuffle、对字段子集的访问,以及对时间序列数据(n-gram)的支持。
对于其他上下文,典型数据集的结构包括:
在自动驾驶汽车测试运行期间收集的传感器数据的多个列,包括摄像头、激光定位器和雷达。
手动生成的标签作为行中的字段进行存储。
行数据按照行分组的时间顺序排列,行组大小通常在 30-100 范围内。
Petastorm 的设计目标包括:
由单数据模式定义驱动数据的编码和解码。
提供 ML 框架和纯 Python 代码可用的高数据加载带宽。
将 Apache Spark 作为分布式集群计算框架来生成数据集。
与纯 Python,ML 平台无关的核心 Petastorm 组件的实现。
呈现给 Tensorflow 和 PyTorch 框架的界面原生接口。
【声明】文章转载自:开源中国社区 [http://www.oschina.net]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- 开源 | 深度有趣 - 人工智能实战项目合集
- Facebook开源深度学习推荐模型DLRM
- 谷歌开源强化学习深度规划网络 PlaNet
- 阿里开源深度神经网络推理引擎 MNN
- 小米崔宝秋:小米 AIoT 深度拥抱开源
- 深度强化学习中实验环境:开源平台框架汇总
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。



