内容简介:这一节在没有特殊说明时,都是在raft/raft.go这个文件中(可以查看方法前的r *raft来知道当前是在raft.go中)。node的tick()方法调用raft/raft.go中raft结构体的tick()。在1.2节中,raft.becomeFollower()中设置了raft结构体的step函数和tick函数=tickElection。
1.6 node tick与raft的tickElection
这一节在没有特殊说明时,都是在raft/raft.go这个文件中(可以查看方法前的r *raft来知道当前是在raft.go中)。
node的tick()方法调用raft/raft.go中raft结构体的tick()。在1.2节中,
raft.becomeFollower()中设置了raft结构体的step函数和tick函数=tickElection。
在上一小节的最后,node.run()从n.tickc通道中获取到消息,调用raft.tick()方法,实际上调用了raft.tickElection()。
// tickElection is run by followers and candidates after r.electionTimeout.
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
当Follower或者Candidate超过选举时间后,会发送类型为MsgHup的一条消息给自己,接着调用r.campaign()方法。
如果消息类型不是MsgHup、MsgVote、MsgPreVote,则调用r.step(r, m)函数。
比如前面becomeFollower时设置了r.step=stepFollower,那么这里就会真正调用stepFollower()方法了。
在stepFollower()方法中,可以看到,它处理的消息类型并没有上面的MsgHup、MsgVote、MsgPreVote。
在最开始启动raft.Node时调用了becomeFollower,初始时,raft的Term为0,后来又被更新为1。
对于类型为MsgHup的pb.Message而言,它的Term初始时为0,所以会执行下面的m.Term==0分支,并接着执行pb.MsgHup分支。
注意:这里的第一个switch语句块的条件是先判断m.Term==0。除此之外,如果m.Term==r.Term,也会执行第二个switch语句块。
func (r *raft) Step(m pb.Message) error {
// Handle the message term, which may result in our stepping down to a follower.
switch {
case m.Term == 0:
// local message
case m.Term > r.Term:
...
case m.Term < r.Term:
...
return nil
}
switch m.Type {
case pb.MsgHup:
if r.state != StateLeader {
ents, err := r.raftLog.slice(r.raftLog.applied+1, r.raftLog.committed+1, noLimit)
if r.preVote {
r.campaign(campaignPreElection)
} else {
r.campaign(campaignElection)
}
} else {
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
}
case pb.MsgVote, pb.MsgPreVote:
...
default:
// 必须先调用r.step=xxx设置函数,然后才能调用下面的语句,真正执行函数。
r.step(r, m)
}
return nil
}
复习下raft调用becomeFollower,raft的状态会更新为StateFollower(下面也列出了成为其他两种角色的代码):
- 成为Follower,启动选举,定时器为tickElection,在electionTimeout超时后,成为Candidate
- 成为Candidate,增加Term,投票给自己,定时器为tickElection
- 成为Leader,定时器为tickHeartbeat,定时发送心跳给Follower
// raft/raft.go
func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
r.logger.Infof("%x became follower at term %d", r.id, r.Term)
}
func (r *raft) becomeCandidate() {
r.step = stepCandidate
// 成为候选人时,Term加1
r.reset(r.Term + 1)
r.tick = r.tickElection
// 投票给自己
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
func (r *raft) becomeLeader() {
r.step = stepLeader
r.reset(r.Term)
r.tick = r.tickHeartbeat
r.lead = r.id
r.state = StateLeader
r.pendingConfIndex = r.raftLog.lastIndex()
r.appendEntry(pb.Entry{Data: nil})
r.logger.Infof("%x became leader at term %d", r.id, r.Term)
}
1.7 竞选Leader
Follower在electionTimeout超时后,会竞选成为Candidate。这里我们暂时不考虑两阶段:
- 调用becomeCandidate,设置投票消息类型为MsgVote
- 如果获取到大多数选票,则调用becomeLeader()
- 向每个节点发送voteMsg
这里Follower第一次执行campaign时,步骤2获取到的选票肯定不满足大多数,所以会向其他节点发送MsgVote消息。
func (r *raft) campaign(t CampaignType) {
var term uint64
var voteMsg pb.MessageType
if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
r.becomeCandidate()
voteMsg = pb.MsgVote
term = r.Term
}
if r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true) {
// We won the election after voting for ourselves (which must mean that this is a single-node cluster). Advance to the next state.
if t == campaignPreElection {
r.campaign(campaignElection)
} else {
r.becomeLeader()
}
return
}
for id := range r.prs {
// 如果是自己,不需要发送
if id == r.id continue
var ctx []byte
if t == campaignTransfer ctx = []byte(t)
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
候选人发送VoteMsg给其他节点(Follower)后,当收到大多数Follower节点的投票结果后,候选人会成为Leader。
下面我们分析Follower节点收到候选人发送的MsgVote请求是如何处理的,这涉及到RPC调用,在Etcd中是rafthttp。
1.8 Raft HTTP
每个EtcdServer都有一个HTTP服务端,用来接收其他节点发送的消息,以及返回响应结果给发送者:
//etcdserver/api/rafthttp/http.go
func (h *pipelineHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
var m raftpb.Message
if err := h.r.Process(context.TODO(), m); err != nil {
switch v := err.(type) {
case writerToResponse:
v.WriteTo(w)
}
return
}
}
EtcdServer
实现了etcdserver/api/rafthttp/transport.go的 Raft
接口
//etcdserver/api/rafthttp/transport.go
type Raft interface {
Process(ctx context.Context, m raftpb.Message) error
IsIDRemoved(id uint64) bool
ReportUnreachable(id uint64)
ReportSnapshot(id uint64, status raft.SnapshotStatus)
}
Q:s.r返回的是etcdserver/raft.go的raftNode,它是一个结构体。而Step方法定义在raft/Node.go接口中。
那么问题是:raftNode结构体的Step方法,是怎么调用到Node接口的Step方法?
A:先看下node.go下的Node接口和node结构体。node结构体实现了Node接口的所有方法,所以可以把node看做是是Node接口的实现类。
虽然raftNode结构体中没有定义raft.Node接口,但是它的raftNodeConfig属性定义了!这种语法叫做struct内嵌/嵌套(embedded)interface。
EtcdServer的Process方法调用raft/node.go中Node接口(其实现类是这个文件下的node结构体)的Step方法:
// etcdserver/server.go
func (s *EtcdServer) Process(ctx context.Context, m raftpb.Message) error {
return s.r.Step(ctx, m)
}
// raft/node.go
func (n *node) Step(ctx context.Context, m pb.Message) error {
// ignore unexpected local messages receiving over network
if IsLocalMsg(m.Type) {
return nil
}
return n.step(ctx, m)
}
func (n *node) step(ctx context.Context, m pb.Message) error {
return n.stepWithWaitOption(ctx, m, false)
}
// Step advances the state machine using msgs. The ctx.Err() will be returned, if any.
func (n *node) stepWithWaitOption(ctx context.Context, m pb.Message, wait bool) error {
if m.Type != pb.MsgProp {
select {
case n.recvc <- m:
return nil
case <-ctx.Done():
return ctx.Err()
case <-n.done:
return ErrStopped
}
}
...
return nil
}
候选人发送请求给Follower节点,当Follower节点收到请求时,会将消息发送到node的recvc通道中。
注意:Etcd分布式集群中的所有节点都会启动raftNode、raft.Node,也都会运行node.run()方法。
// raft/node.go
func (n *node) run(r *raft) {
...
for {
select {
...
case <-n.tickc:
r.tick()
case m := <-n.recvc:
// filter out response message from unknown From.
if pr := r.getProgress(m.From); pr != nil || !IsResponseMsg(m.Type) {
r.Step(m)
}
}
}
}
回顾前面Candidate从n.tickc中获取到定时器(ElectionTimeout)的超时消息,通过tickElection()
调用到raft.go的 Step()
方法,然后参与竞选(campaign)并发送VoteMsg给Follower节点。
这里Follower节点收到VoteMsg请求,从n.recvc中获取到消息,也会调用 r.Step(m)
方法。
两个节点的角色不一样,但是都会调用相同的raft.Step()方法,当然两者的处理逻辑不一样。
1.9 Follower收到MsgVote,投票
Follower收到消息m的Term=1,它自己raft.Term=0,步骤如下:
- m.Term > r.Term,调用becomeFollower()
- 返回MsgVoteResp给候选人。
// raft/raft.go
func (r *raft) Step(m pb.Message) error {
// Handle the message term, which may result in our stepping down to a follower.
switch {
case m.Term == 0:
// local message
case m.Term > r.Term:
switch {
default:
if m.Type == pb.MsgApp || m.Type == pb.MsgHeartbeat || m.Type == pb.MsgSnap {
r.becomeFollower(m.Term, m.From)
} else {
// Follower收到Candidate的MsgVote请求,自己成为Follower(更改状态)
// 同样,这里只是设置Raft的step函数和tick函数,还没有真正执行成为Follower的逻辑
r.becomeFollower(m.Term, None)
}
}
case m.Term < r.Term:
...
return nil
}
switch m.Type {
case pb.MsgHup:
...
case pb.MsgVote, pb.MsgPreVote:
canVote := r.Vote == m.From || // We can vote if this is a repeat of a vote we've already cast...
(r.Vote == None && r.lead == None) || // ...we haven't voted and we don't think there's a leader yet in this term...
(m.Type == pb.MsgPreVote && m.Term > r.Term) // ...or this is a PreVote for a future term...
if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) { // ...and we believe the candidate is up to date.
r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)}) // 返回的消息类型为VoteResp
if m.Type == pb.MsgVote {
r.electionElapsed = 0 // Only record real votes. 重置选举计数器
r.Vote = m.From // 投票给发送这条消息的节点,即候选人
}
} else {
r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true}) // 拒绝投票
}
default:
err := r.step(r, m)
if err != nil {
return err
}
}
return nil
}
当Follower返回MsgVote的响应结果MsgVoteResp给Candidate,Candidate的处理流程与Follower收到消息的类似,也会调用r.Step()方法。
1.10 Candidate成为Leader
由于Follower返回消息的Term等于Candidate发送消息的Term,所以直接走第二个switch条件的default分支:
// raft/raft.go
func (r *raft) Step(m pb.Message) error {
// Handle the message term, which may result in our stepping down to a follower.
switch {
case m.Term == 0:
// local message
case m.Term > r.Term:
...
case m.Term < r.Term:
...
return nil
}
switch m.Type {
case pb.MsgHup:
...
case pb.MsgVote, pb.MsgPreVote:
...
default:
err := r.step(r, m) // 调用Raft的stepFunc,即1.7节通过becomeCandidate设置的stepCandidate
if err != nil {
return err
}
}
return nil
}
前面我们看到在Step(m)方法中都没有走到default分支,这里开始调用r.step(r,m)函数,对应的是stepCandidate:
// stepCandidate is shared by StateCandidate and StatePreCandidate; the difference is
// whether they respond to MsgVoteResp or MsgPreVoteResp.
func stepCandidate(r *raft, m pb.Message) error {
// Only handle vote responses corresponding to our candidacy (while in
// StateCandidate, we may get stale MsgPreVoteResp messages in this term from our pre-candidate state).
var myVoteRespType pb.MessageType
if r.state == StatePreCandidate {
myVoteRespType = pb.MsgPreVoteResp
} else {
myVoteRespType = pb.MsgVoteResp
}
switch m.Type {
case pb.MsgProp:
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
case pb.MsgApp:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleAppendEntries(m)
case pb.MsgHeartbeat:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleHeartbeat(m)
case pb.MsgSnap:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleSnapshot(m)
case myVoteRespType: // 候选人收到Follower的VoteMsg消息,判断投票个数
gr := r.poll(m.From, m.Type, !m.Reject)
r.logger.Infof("%x [quorum:%d] has received %d %s votes and %d vote rejections", r.id, r.quorum(), gr, m.Type, len(r.votes)-gr)
switch r.quorum() {
case gr:
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
r.becomeLeader() // 满足投票个数,成为Leader
r.bcastAppend() // 向其他Follower节点发送MsgApp请求
}
case len(r.votes) - gr:
// pb.MsgPreVoteResp contains future term of pre-candidate m.Term > r.Term; reuse r.Term
r.becomeFollower(r.Term, None)
}
case pb.MsgTimeoutNow:
r.logger.Debugf("%x [term %d state %v] ignored MsgTimeoutNow from %x", r.id, r.Term, r.state, m.From)
}
return nil
}
总结下每个节点在收到HTTP请求时,都会调用raft.Step(m)方法,如果消息的类型不是MsgHup、MsgVote、MsgPreVote,则调用r.step(r,m)方法。
Raft的stepFunc在发送/收到HTTP请求之前一定会被设置,设置的地方在调用becomeFollower、becomeCandidate、becomeLeader这三个方法中。
A:以Follower1转为Candidate为例:
- 调用becomeFollower,设置r.step=stepFollower
- ticker的electionTimeout超时,调用becomeCandidate,设置r.step=stepCandidate
- 调用campaign,发送VoteMsg给其他所有节点
B:以Follower2为例:
- 调用becomeFollower,设置r.step=stepFollower
- 收到候选节点的VoteMsg请求,投票给候选节点,返回VoteMsgResp
C:以Candidate转为Leader为例:
- 收到Follower发送的VoteMsgResp,调用r.step函数,即A:2中的stepCandidate
- 判断投票个数,如果得到大多数的选票,调用becomeLeader,设置r.step=stepLeader
- 向其他Follower节点发送MsgApp请求
D:以Follower2为例:
- 收到Leader的MsgApp请求,调用r.step函数,即B:1的stepFollower
- 处理AppendEntries请求,返回MsgAppResp请求给Leader
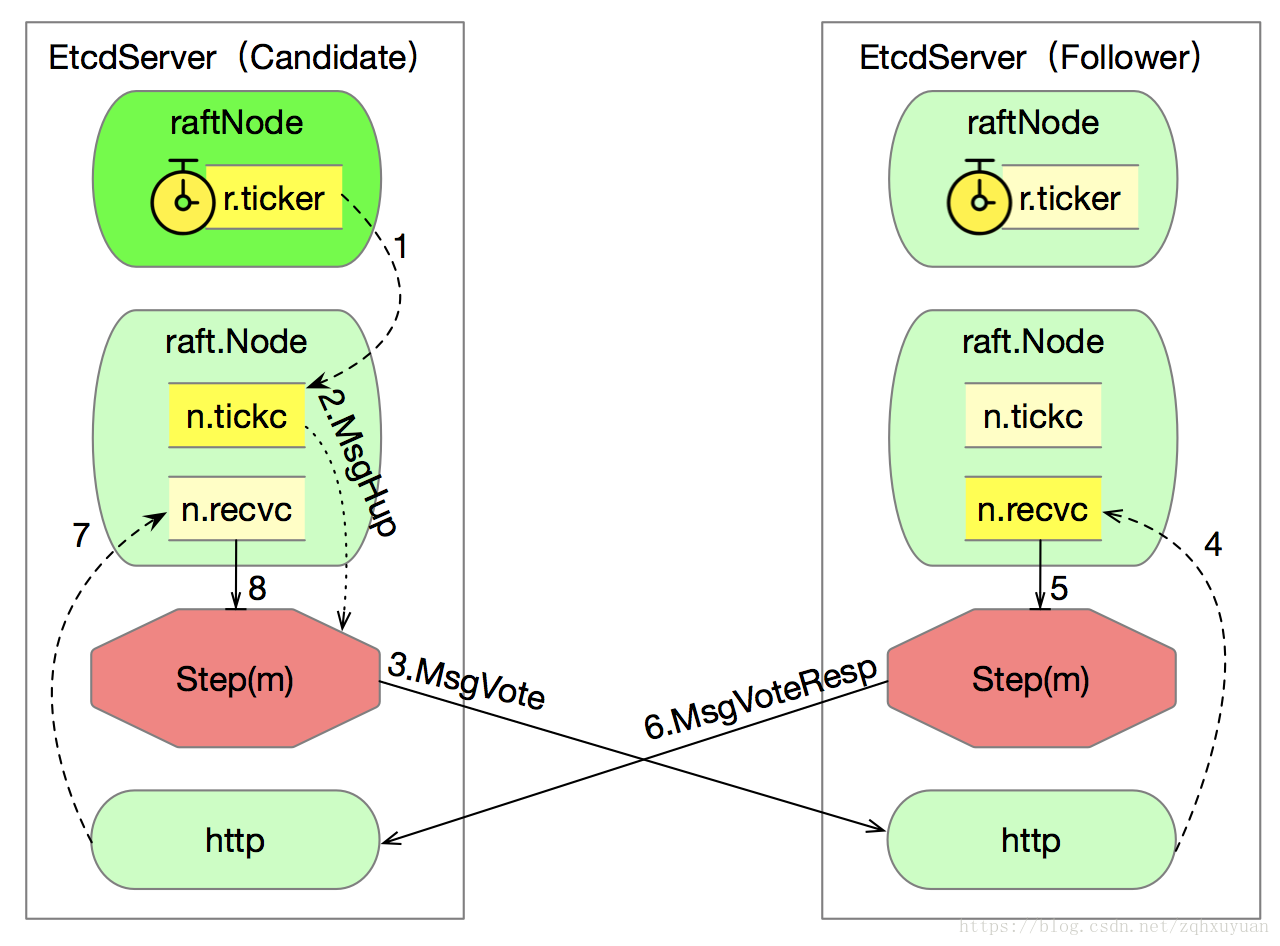
下面是Candidate发送MsgVote给Follower,Follower返回MsgVoteResp给Candidate的流程:
以上所述就是小编给大家介绍的《Etcd Raft源码分析之二:选举流程》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
猜你喜欢:
- zookeeper-选举源码分析
- zk集群运行过程中,服务器选举的源码剖析
- Kafka 源码系列之 topic 创建分区分配及 leader 选举
- 以太坊2.0:公开单一领导人选举(PSLE)+秘密概率后备选举(SPBE)研究
- 俄罗斯再度利用网络攻击试图干扰乌克兰选举 (附俄国历年干扰选举案例汇总)
- zookeeper选举算法
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Web性能权威指南
Ilya Grigorik / 李松峰 / 人民邮电出版社 / 2013-9 / 69
本书是谷歌公司高性能团队核心成员的权威之作,堪称实战经验与规范解读完美结合的产物。本书目标是涵盖Web 开发者技术体系中应该掌握的所有网络及性能优化知识。全书以性能优化为主线,从TCP、UDP 和TLS 协议讲起,解释了如何针对这几种协议和基础设施来优化应用。然后深入探讨了无线和移动网络的工作机制。最后,揭示了HTTP 协议的底层细节,同时详细介绍了HTTP 2.0、 XHR、SSE、WebSoc......一起来看看 《Web性能权威指南》 这本书的介绍吧!


