内容简介:Uber 近日开源了已在内部使用多年的指标平台 —— M3 ,这是一个基于分布式时序数据库 M3DB 构建的度量平台,可每秒聚合 5 亿个指标,并且以每秒 2000 万笔的速度持续存储这些结果。 Uber 表示,为促进在全球的运...
Uber 近日开源了已在内部使用多年的指标平台 —— M3 ,这是一个基于分布式时序数据库 M3DB 构建的度量平台,可每秒聚合 5 亿个指标,并且以每秒 2000 万笔的速度持续存储这些结果。

Uber 表示,为促进在全球的运营发展,他们需要能够在任何特定时间快速存储和访问后端系统上的数十亿个指标。一直到 2014 年底,Uber 的所有服务、基础设施和服务器都是将指标发送到基于 Graphite 的系统中,该系统将这些资料以 Whisper 档案格式储存到分片 Carbon 丛集。此外,还将 Grafana 用于仪表板,Nagios 用于告警,并通过来源控制脚本发出 Graphite 阈值检查。但由于扩展 Carbon 集群需要手动重新分片的过程,并且由于缺乏副本,任何单一节点的磁盘故障都会导致其相关指标的永久性丢失。简而言之,随着公司的不断发展,这种解决方案无法再满足其需求。
在评估现有的解决方案后,Uber 没有找到能够满足其资源效率或规模目标,并能够作为自助服务平台运行的开源替代方案。因此在 2015 年,M3 诞生。起初,M3 几乎全部采用完全开源的组件来完成基本角色,像是用于聚合的 statsite ,用于时序存储具备 Date Tiered Compaction Strategy 的 Cassandra ,以及用于索引的 ElasticSearch 。基于运营负担,成本效率和不断增长的功能集考虑,M3 逐渐形成自己的组件,功能也超越原本使用的方案。
M3 目前拥有超过 66 亿条时序数据,每秒聚合5亿个指标,并在全球范围内每秒持续存储 2000 万个指标(使用 M3DB),批量写入将每个指标持久保存到不同区域的三个副本中。它还允许工程师编写度量策略,以不同的时间长度和不同粒度对资料进行保存。这使得工程师和数据科学家能以不同的留存规则,精细和智能地存储有不同保留需求的时序数据。
在 Uber,由于很多团队在广泛使用 Prometheus ,如何很好地搭配使用是很重要的事。通过一个 sidecar 组件 M3 Coordinator ,M3 集成了 Prometheus 。该组件会向本地区域的 M3DB 实例写入数据,并将查询扩展至“区域间协调器”(inter-regional coordinator)。
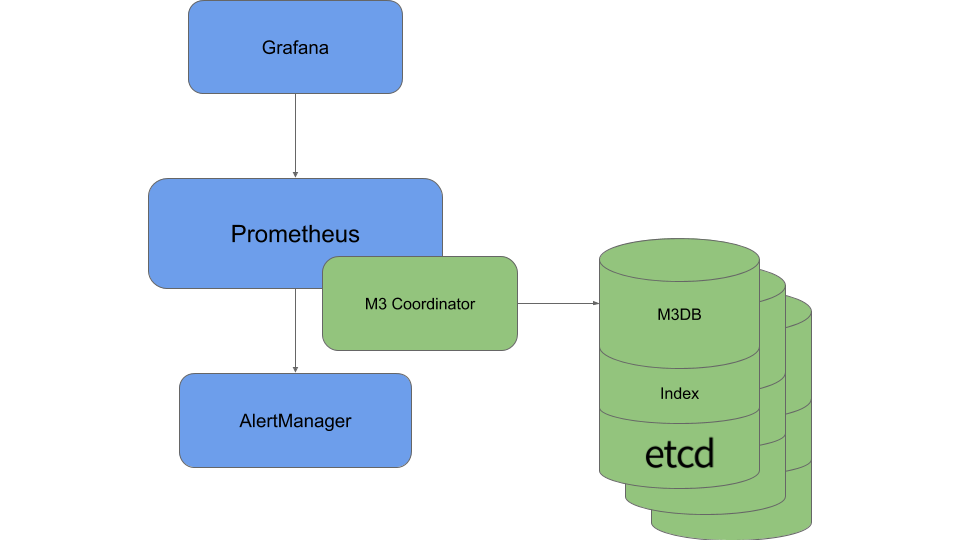
基于 Uber 日益增长的度量存储工作负载的经验,M3 具备以下特性:
优化指标管道的每个部分,为工程师提供尽可能多的存储空间,以实现最少的硬件支出成本。
通过自定义压缩算法 M3TSZ 确保数据尽可能高度压缩以减少硬件占用空间。
由于多数数据资料为“一次写入,永不读取”,尽量保持精简的内存占用空间以避免内存成为瓶颈。
尽可能避免压缩整理,通过缩小采样,以增加主机资源的利用率,从而实现更多并发写入,并提供稳定的写入/读取延迟。
时序数据采用本地存储,无需时刻警惕高写入量操作。
【声明】文章转载自:开源中国社区 [http://www.oschina.net]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- Uber开源其大规模指标平台M3
- 工具 | 滴滴开源的一站式 Apache Kafka 集群指标监控与运维管控平台
- ICML新研究提出泛化能力评估新指标:直接上向量余弦距离就OK,还开源了相关代码
- 指标体系:四个模型教会你指标体系构建的方法
- 有赞指标库实践
- 网站性能指标 - FMP
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

How to Build a Billion Dollar App
George Berkowski / Little, Brown Book Group / 2015-4-1 / USD 24.95
Apps have changed the way we communicate, shop, play, interact and travel and their phenomenal popularity has presented possibly the biggest business opportunity in history. In How to Build a Billi......一起来看看 《How to Build a Billion Dollar App》 这本书的介绍吧!


