内容简介:版本新特性 JS渲染:支持JS渲染方式采集数据,可参考 "爬虫示例6"; 抽象并设计PageLoader,方便自定义和扩展页面加载逻辑,如JS渲染等。底层提供 "JsoupPageLoader(默认/推荐)","HtmlUnitPageLoader"两种实现,...
版本新特性
JS渲染:支持JS渲染方式采集数据,可参考 "爬虫示例6";
抽象并设计PageLoader,方便自定义和扩展页面加载逻辑,如JS渲染等。底层提供 "JsoupPageLoader(默认/推荐)","HtmlUnitPageLoader"两种实现,可自定义其他类型PageLoader如 "Selenium" 等;
修复Jsoup默认加载1M的限制;
爬虫线程中断处理优化;
简介
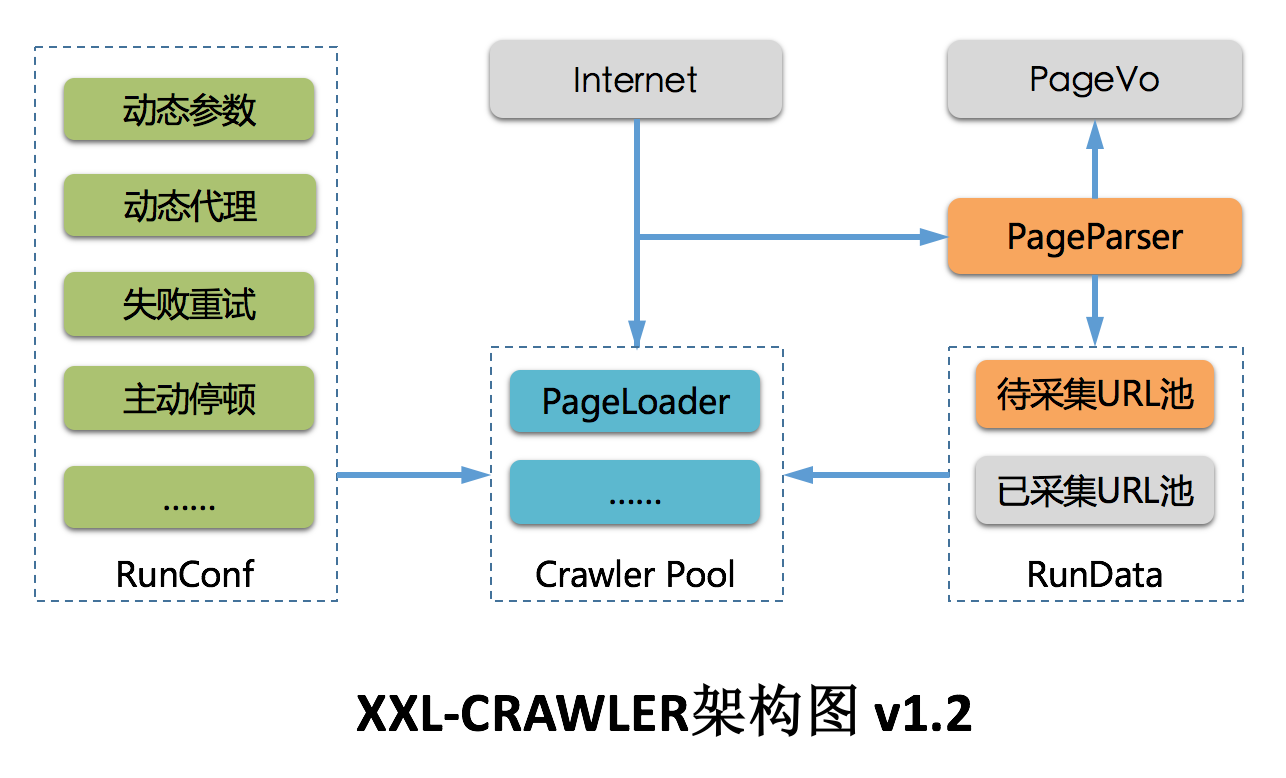
XXL-CRAWLER 是一个分布式爬虫框架。一行代码开发一个分布式爬虫,拥有"多线程、异步、IP动态代理、分布式、JS渲染"等特性;
特性
1、简洁:API直观简洁,可快速上手;
2、轻量级:底层实现仅强依赖jsoup,简洁高效;
3、模块化:模块化的结构设计,可轻松扩展
4、面向对象:支持通过注解,方便的映射页面数据到PageVO对象,底层自动完成PageVO对象的数据抽取和封装返回;单个页面支持抽取一个或多个PageVO
5、多线程:线程池方式运行,提高采集效率;
6、分布式支持:通过扩展 "RunData" 模块,并结合 Redis 或DB共享运行数据可实现分布式。默认提供LocalRunData单机版爬虫。
7、JS渲染:通过扩展 "PageLoader" 模块,支持采集JS动态渲染数据。原生提供Jsoup(快速、推荐)和HtmlUnit(较慢、JS渲染)两种实现,支持自由扩展其他实现。
8、失败重试:请求失败后重试,并支持设置重试次数;
9、代理IP:对抗反采集策略规则WAF;
10、动态代理:支持运行时动态调整代理池,以及自定义代理池路由策略;
11、异步:支持同步、异步两种方式运行;
12、扩散全站:支持以现有URL为起点扩散爬取整站;
13、去重:防止重复爬取;
14、URL白名单:支持设置页面白名单正则,过滤URL;
15、自定义请求信息,如:请求参数、Cookie、Header、UserAgent轮询、Referrer等;
16、动态参数:支持运行时动态调整请求参数;
17、超时控制:支持设置爬虫请求的超时时间;
18、主动停顿:爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截;
文档地址
技术交流
【声明】文章转载自:开源中国社区 [http://www.oschina.net]
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
- python爬虫 | 一文搞懂分布式进程爬虫
- 装个虚拟机,然后拿来玩爬虫!也是极好的!Scrapy分布式爬虫!
- 分布式爬虫对新站的协助
- 分布式通用爬虫框架Crawlab
- 如何构建一个分布式爬虫:基础篇
- 基于redis的分布式爬虫实现方案
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

你不知道的JavaScript(上卷)
[美] Kyle Simpson / 赵望野、梁杰 / 人民邮电出版社 / 2015-4 / 49.00元
JavaScript语言有很多复杂的概念,但却用简单的方式体现出来(比如回调函数),因此,JavaScript开发者无需理解语言内部的原理,就能编写出功能全面的程序;就像收音机一样,你无需理解里面的管子和线圈都是做什么用的,只要会操作收音机上的按键,就可以收听你喜欢的节目。然而,JavaScript的这些复杂精妙的概念才是语言的精髓,即使是经验丰富的JavaScript开发者,如果没有认真学习也无......一起来看看 《你不知道的JavaScript(上卷)》 这本书的介绍吧!


