内容简介:开源地址: github: https://github.com/sagframe/sagacity-sqltoy gitee: https://gitee.com/sagacity/sagacity-sqltoy idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins...

开源地址:
- github: https://github.com/sagframe/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
更新内容
1、升级log4j2依赖版本为2.15.0
2、 sql 补全优化,如from table where xxx 情况下自动补全select *
3、增加一些容错校验判断
周末因个别用户使用偌依(ruoyi)集成sqltoy,修改了一个简单的字典类别查询,真是由衷的感慨,都说 java 没有好的ORM框架,核心是mybatis代表了大家!
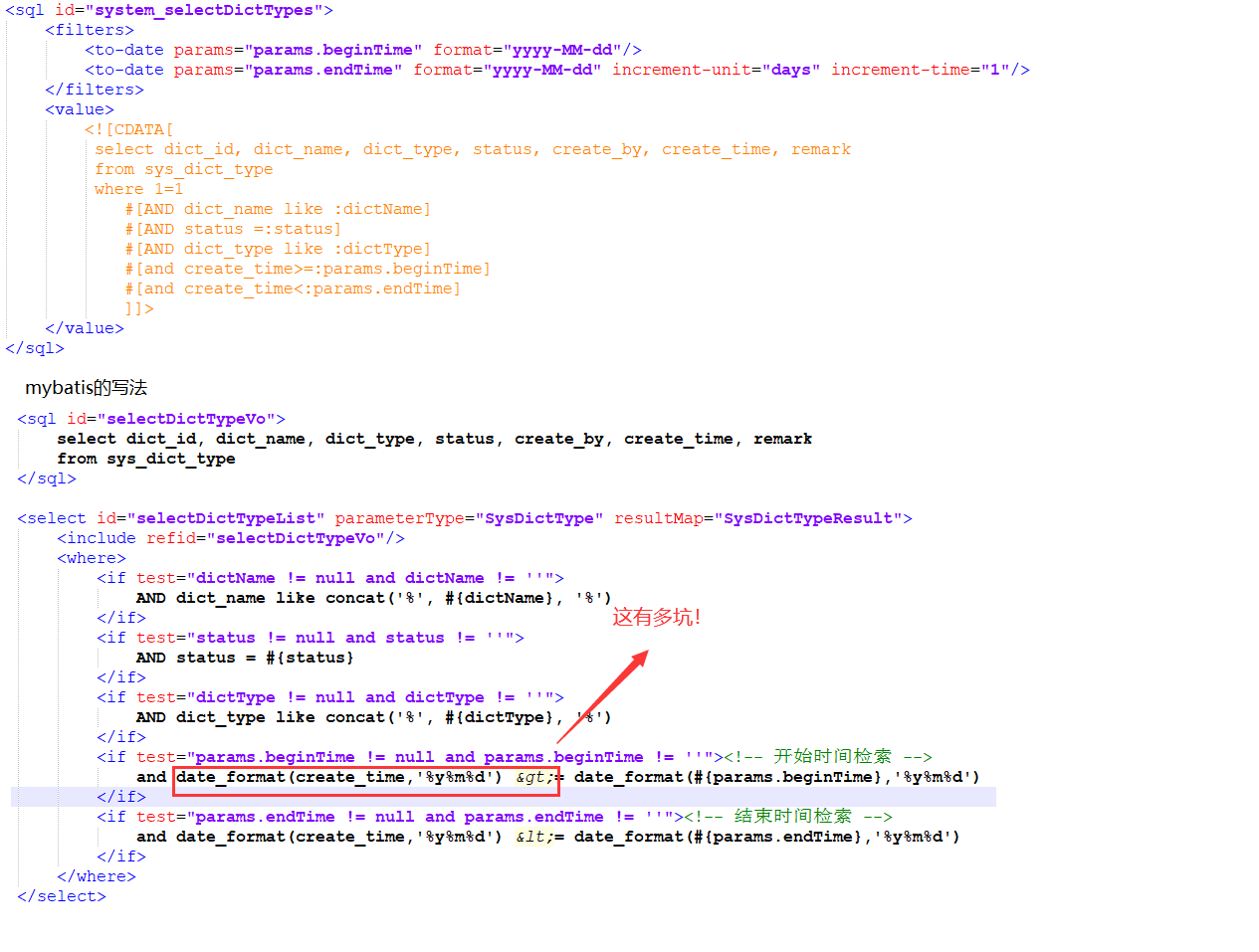
sqltoy特点介绍:
- sqltoy的核心构建思想
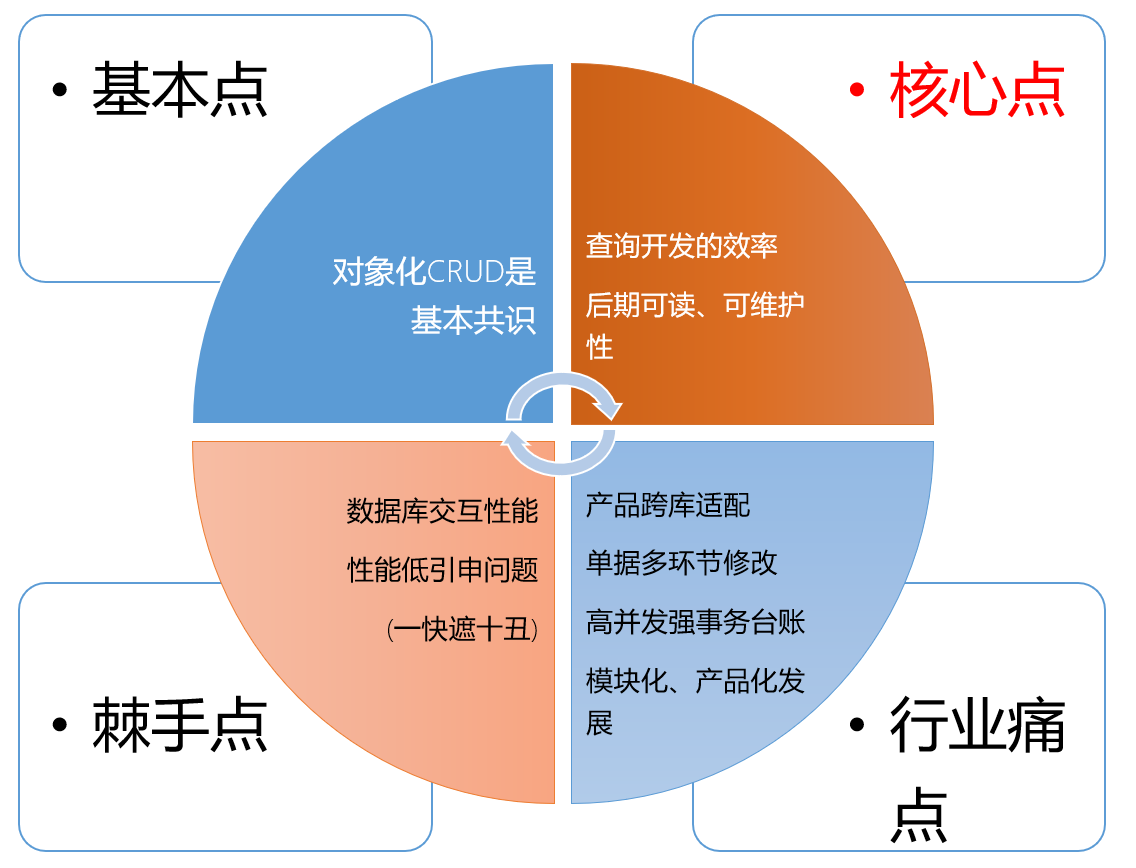
- sqltoy的对比mybatis(plus)和fluent mybatis的核心点:查询语句编写、可阅读性、可维护性
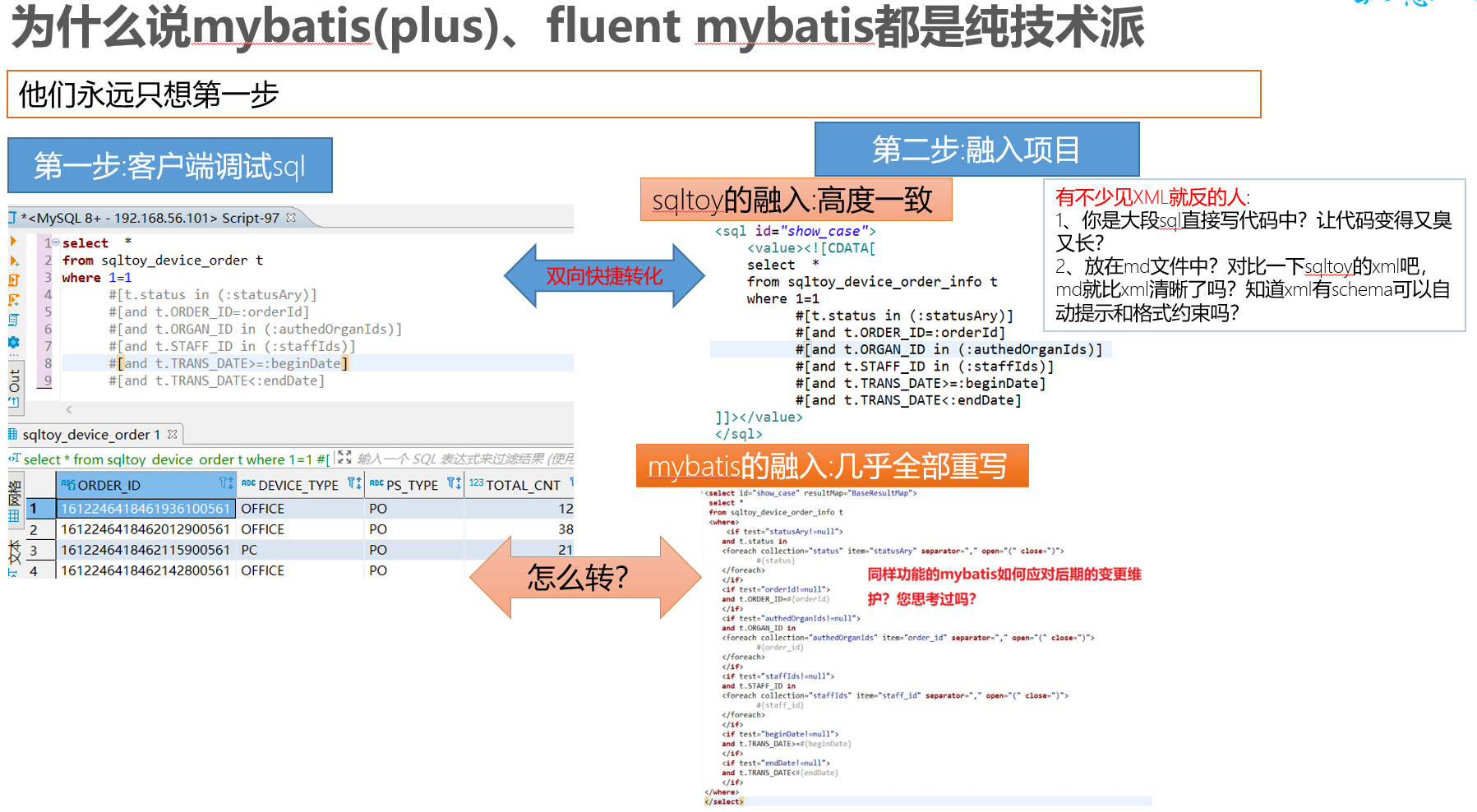
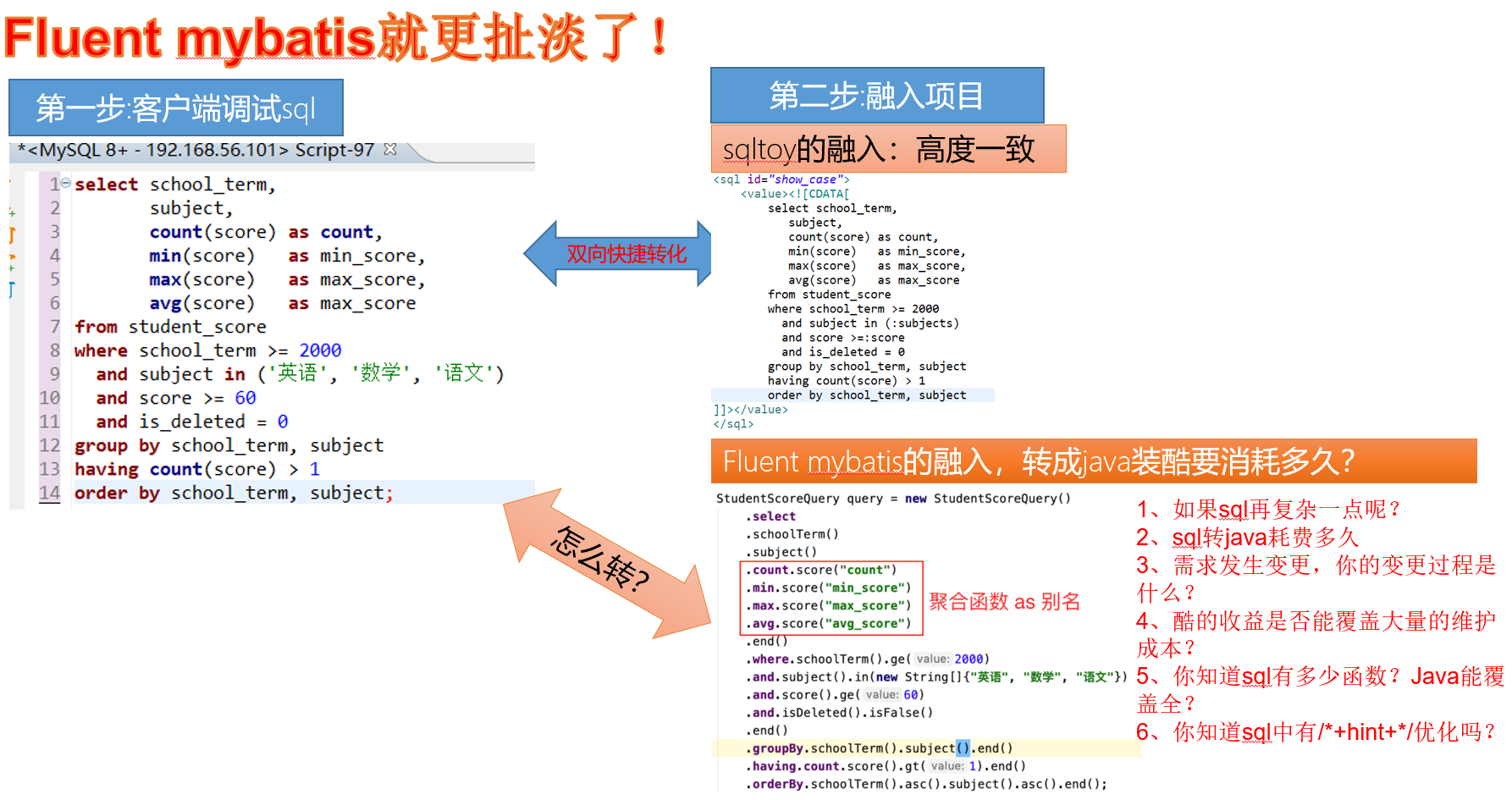
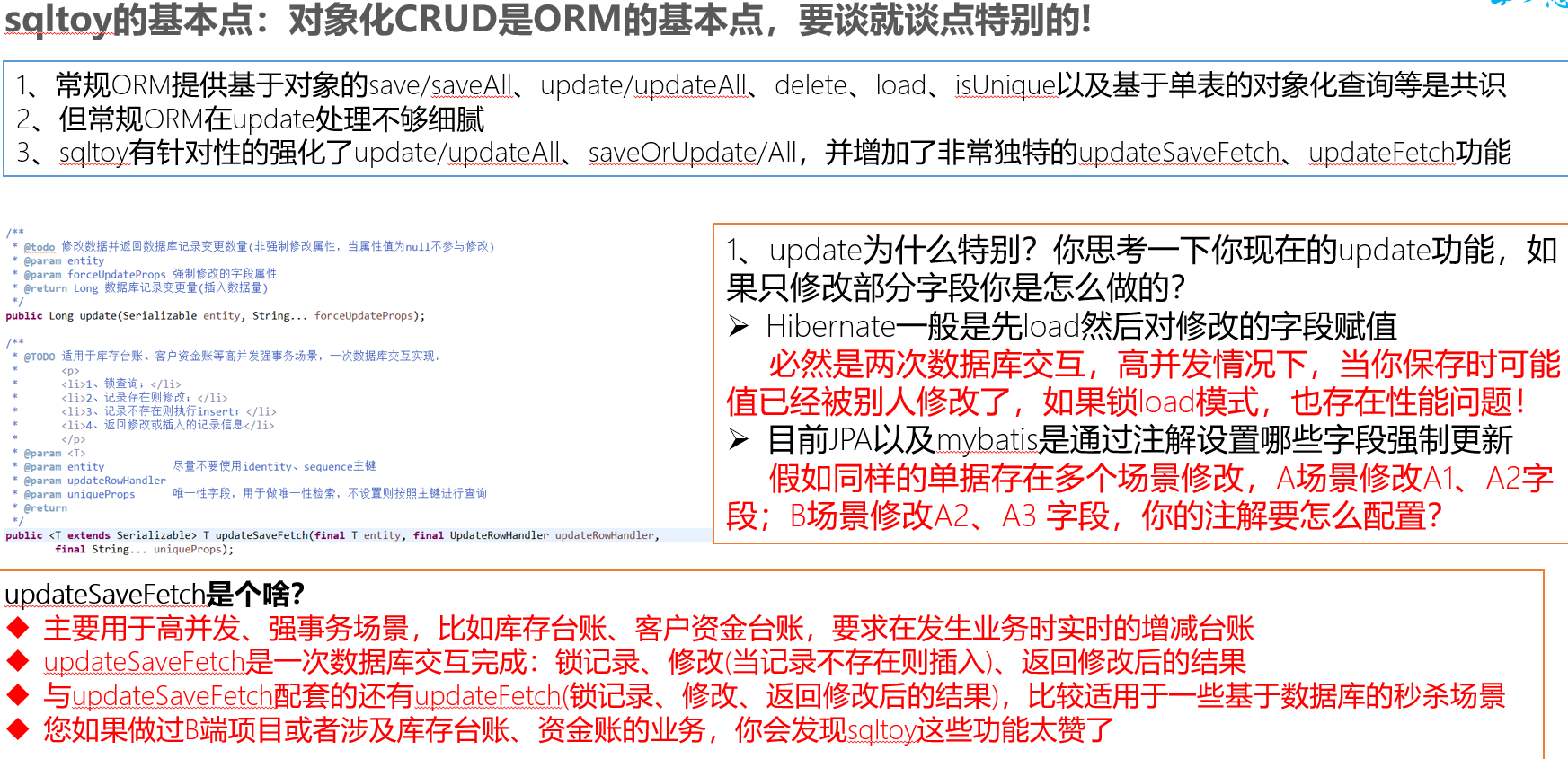
- 对象化crud是基础,但sqltoy有针对性的改进:update、updateSaveFetch、updateFetch等
- sqltoy的缓存翻译,大幅减少表关联简化sql,让你的查询性能成几何级提升
除xml配置模式外,也支持注解模式
@Translate(cacheName = "dictKeyName", cacheType = "DEVICE_TYPE", keyField = "deviceType")
private String deviceTypeName;
@Translate(cacheName = "staffIdName", keyField = "staffId")
private String staffName;
- 极致的分页,同样帮助你实现查询的性能大幅提升
- 快速分页:@fast() 实现先取单页数据然后再关联查询,极大提升速度
- 分页优化器:page-optimize 让分页查询由两次变成1.3~1.5次(用缓存实现相同查询条件的总记录数量在一定周期内无需重复查询
- sqltoy的分页取总记录的过程不是简单的select count(1) from (原始sql);而是智能判断是否变成:select count(1) from 'from后语句', 并自动剔除最外层的order by
- sqltoy支持并行查询:parallel="true",同时查询总记录数和单页数据,大幅提升性能
- 便利的跨数据库统计计算:数据旋转
- 便利的跨数据库统计计算:无限极分组统计(含汇总求平均)
- 便利的跨数据库统计计算:同比环比
以上所述就是小编给大家介绍的《sqltoy-orm 5.1.20 发版》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!

本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Python高效开发实战——Django、Tornado、Flask、Twisted(第2版)
刘长龙 / 电子工业出版社 / 2019-1 / 99
也许你听说过全栈工程师,他们善于设计系统架构,精通数据库建模、通用网络协议、后端并发处理、前端界面设计,在学术研究或工程项目上能独当一面。通过对Python 3及相关Web框架的学习和实践,你就可以成为这样的全能型人才。 《Python高效开发实战——Django、Tornado、Flask、Twisted(第2版)》分为3篇:上篇是Python基础,带领初学者实践Python开发环境,掌握......一起来看看 《Python高效开发实战——Django、Tornado、Flask、Twisted(第2版)》 这本书的介绍吧!


