内容简介:01 背 景 dl_inference是58同城推出的通用深度学习推理服务,可在生产环境中快速上线由TensorFlow、PyTorch、Caffe等框架训练出来的深度学习模型。dl_inference于2020年3月26号发布,可参见《开源|dl_inference:...


01 背 景
dl_inference是58同城推出的通用深度学习推理服务,可在生产环境中快速上线由TensorFlow、PyTorch、Caffe等框架训练出来的深度学习模型。dl_inference于2020年3月26号发布,可参见《开源|dl_inference:通用深度学习推理服务》。
我们在2021年11月对dl_inference再次进行更新,从发布至今新增如下Features:
1、集成TensorRT加速深度学习推理,支持将TensorFlow-SavedModel模型、PyTorch-Pth模型进行自动优化,转换为TensorRT模型后部署,提高模型在GPU上的推理速度。
2、集成Intel Math Kernel Library库的TensorFlow Serving推理框架,加速TensorFlow模型CPU上推理。
3、支持Caffe模型推理,提供丰富的模型应用示例。
02 使用TensorRT加速深度学习推理
深度学习模型推理阶段对算力和时延具有很高的要求,如果将训练好的神经网络直接部署到推理端,很有可能出现算力不足无法运行或者推理时间较长等问题,因此我们需要对训练好的神经网络进行一定的优化。TensorRT是NVIDIA推出的一款基于CUDA和cuDNN的神经网络推理加速引擎,能从以下几个方面来提升模型在GPU上的推理性能:
-
权重与激活精度校准:支持将模型量化为FP16/INT8精度,提高吞吐量的同时保持高准确度。
-
层与张量融合:TensorRT可以做计算图优化,通过kernel融合,减少数据拷贝等手段,生成网络的优化计算图。
-
内核自动调整:TensorRT可以自动选取最优kernel。同样是矩阵乘法,在不同GPU架构上以及不同矩阵大小,最优的GPU kernel的实现方式不同,TensorRT可以把它优选出来。
-
动态张量显存:更大限度减少显存占用,高效地为张量重复利用显存。
-
多流执行:并行处理多个输入流的可扩展设计。
同时NVIDIA提供了Triton Inference Server(以下简称TIS)框架支持多种模型的推理服务部署。TIS是NVIDIA针对旗下GPU推出的高性能在线推理解决方案,可通过HTTP或gRPC端点提供服务,为模型部署方案提供更多灵活性的同时可以充分发挥GPU的并行计算能力。
dl_inference基于TensorRT 7.1.3版本和TIS 20.08版本实现GPU推理加速功能,支持将TensorFlow和PyTorch框架训练出来的模型通过TensorRT引擎自动进行优化,转换为TensorRT格式模型,然后通过TIS推理框架进行服务化部署。使用dl_inference的GPU推理加速功能包括模型转换和模型部署两步,详细介绍如下。
1、 模型转换
开发者提供TensorFlow训练好的SavedModel.pb或PyTorch训练好的Model.pth模型文件,dl_inference会先将其转换为ONNX(Open Neural Network Exchange)格式模型,ONNX是一种针对机器学习所设计的开放式文件格式,用于存储训练好的模型,它使得不同的深度学习框架可以在相同格式存储模型数据并交互,然后dl_inference再将ONNX模型文件自动进行优化,转换得到TensorRT格式模型。开发者除了要提前准备好模型文件外还需提供模型元数据描述文件config.txt,TensorFlow SavedModel.pb模型元数据可由saved_model_cli 命令 工具 查看,PyTorch pth模型由于没有name概念,可设置为单字母名称,如 i, o等,表示inputs,outputs。以Resnet50(dl_inference/DLPredictOnline/demo/model/tis)为例模型元数据描述文件config.txt如下:
{"batch_size":0,"input":[{"name":"image","data_type":"float","dims":[-1,224,224,3],"node_name":"input_1:0"}],"output":[{"name":"probs","data_type":"float","dims":[-1,19],"node_name":"dense_1/Softmax:0"}]}
模型和模型元数据描述文件准备好后,在dl_inference/TisPredictOnline/DockerImage目录下进行镜像生成。
cd DockerImagedocker build -t tis-model-convert:lastest .
最后启动镜像,自动化执行模型转换操作,完成模型转换。
cd $模型所在路径docker run -v `pwd`:/workspace/source_model -e SOURCE_MODEL_PATH=/workspace/source_model -e TARGET_MODEL_PATH=/workspace/source_model -e MODEL_NAME=tensorflow-666 -e MODEL_TYPE=tensorflow tis-model-convert:lastest# SOURCE_MODEL_PATH 原始模型所在路径,也是模型描述文件所在路径# TARGET_MODEL_PATH 生成TensorRT模型所在路径# MODEL_NAME 模型名称# MODEL_TYPE 模型类型 (tensorflow or pytorch)
2、模型部署
首先需要拉取镜像,然后启动镜像进行模型TIS推理部署。
docker pull nvcr.io/nvidia/tritonserver:20.08-py3docker run -v ${TARGET_MODEL_PATH}:/workspace -p 8001:8001 nvcr.io/nvidia/tritonserver:20.08-py3 /opt/tritonserver/bin/tritonserver --model-repository=/workspace# TARGET_MODEL_PATH即为模型转换服务中环境变量值,默认使用8001端口且此端口固定
至此模型TIS推理服务已经就绪,开发者可以通过客户端对其进行测试,dl_inference定义了rpc接口TisPredict用于进行调用,同时也提供了client demo
(dl_inference/DLPredictOn-line/demo/src/main/java/com/bj58/ailab/demo/client/TisClient.java)供开发者进行参考。
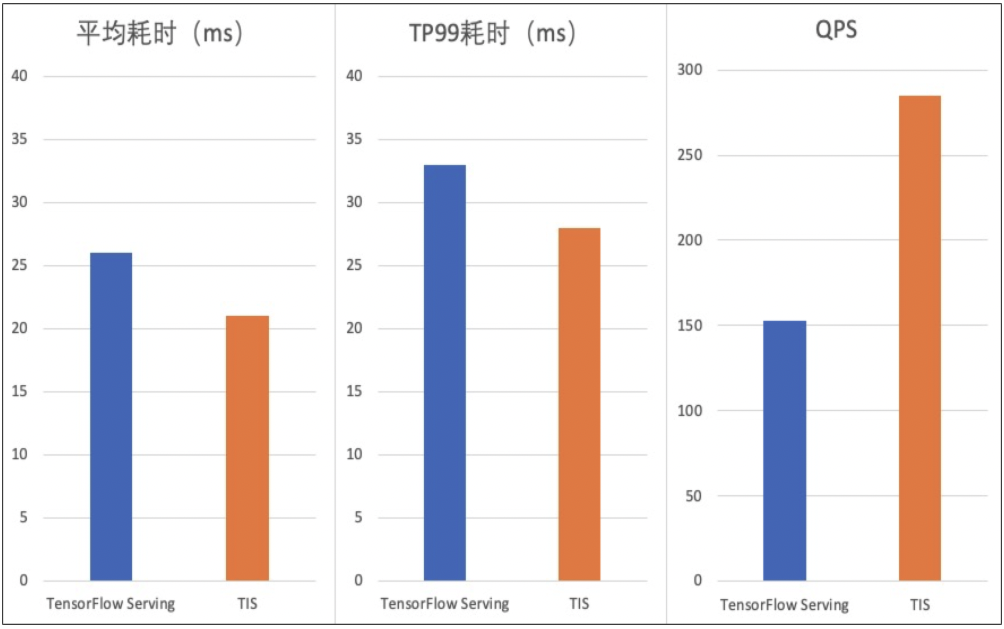
使用TensorRT加速深度学习推理能够使得GPU上推理性能大幅提升,如dl_inference在TensorFlow框架训练的Resnet50模型上应用TensorRT加速功能,在不降低推理精度情况下,T4卡上加速后QPS提升80%,耗时降低18%,如下图所示。
03 使用Intel MKL 加速深度学习推理
Math Kernel Library(简称MKL,后改名为oneDNN)为Intel推出的数学核心函数库,能够在CPU上利用AVX2、FMA等指令进行指令集优化。dl_inference通过利用MKL库,在以下几个方面对TensorFlow模型推理进行了优化:
-
在CPU上运行时将TensorFlow替换为Intel优化版本,这样能在不改变模型网络的前提下提升性能。
-
消除不必要且耗费计算资源的数据层转换。
-
将多个运行融合在一起以在CPU上高效重复使用高速缓存。
dl_inference使用带有MKL编译选项的TensorFlow Serving版本,开发者准备好TensorFlow训练好的SavedModel格式模型后按TensorFlow Serving方式部署到dl_inference提供的TensorFlow Serving MKL镜像即可获得加速效果,TensorFlow Serving能够兼容低版本模型,即使是TensorFlow1.x训练的模型,也可以在TensorFlow Serving2.x上使用,因此开发者无需考虑版本问题。MKL版本提供一些参数供开发者进行调整,参数说明如下:
KMP_BLOCKTIME - 设置线程在执行完并行区域之后,在休眠之前应该等待的时间(以毫秒为单位)
KMP_AFFINITY - 控制线程如何分布并绑定到特定的处理单元
KMP_SETTINGS - 允许 (true) 或禁止 (false) 在程序执行期间输出 OpenMP* 运行时库环境变量
OMP_NUM_THREADS - OpenMP运行时可用的最大线程数,通常设置为等于物理内核的数量
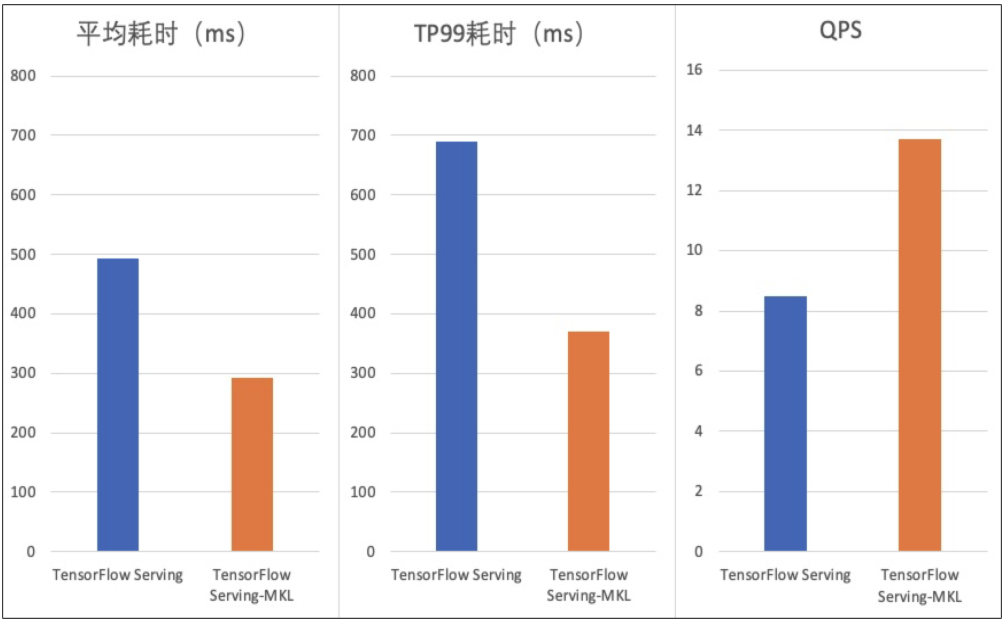
dl_inference在Intel(R) Xeon(R) CPU E5-2620上部署Resnet50模型推理使用MKL版本获取了不错的加速效果,使用MKL版本的TensorFlow Serving相对直接使用TensorFlow Serving QPS提升60%,耗时降低40%,对比时分配的CPU资源为4核,效果如下图所示。
Caffe模型推理支持
Caffe是一款较为主流的深度学习框架,使用人数虽然相比TensorFlow和PyTorch较少,但是仍然有着较大的应用基数。因此dl_inference在v1.1版本中,基于Seldon封装了Caffe模型推理RPC服务,统一接口协议,适用任何类型的Caffe模型,极大减少模型部署工作量。同时在模型RPC服务封装时我们进行了创新,首先,引入前后预处理程序, 支持用户在执行模型推理前后进行相关数据的处理;其次 ,开放模型调用,用户可以根据业务及模型的特点进行模型调用独立定制,Caffe模型推理流程如下图。
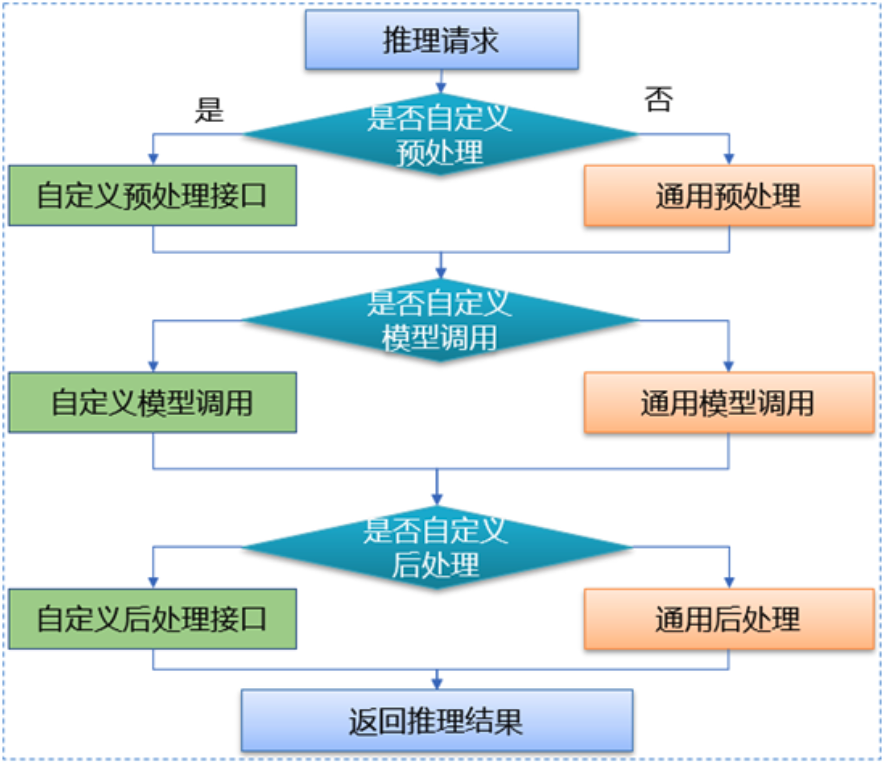
dl_inference提供了可以由用户自定义的接口文件preprocess(模型执行前数据预处理)和postprocess(模型执行后数据后处理)。在preprocess中,可以对传入的推理数据和参数进行预处理操作,比如对图片的字节流数据进行处理,返回模型推理需要的Tensor类型数据;在postprocess中,可以对模型返回的推理结果进行处理,比如对结果进行筛选并剔除多余结果数据,或者将结果数据进行压缩、数学变换等操作。支持推理前后的数据处理,使得线上线下可以使用同一套数据处理,极大的简化了算法开发人员部署模型的工作量,同时还可以在远程部署时,减小网络传递的数据包大小,提高整体推理性能。
不同的业务场景模型实现不尽相同,为了支持在不同场景下的模型调用需求,用户可以在自定义接口文件中,重新定义模型的执行过程。默认的模型执行是单次执行,自定义接口函数中,可以多次执行同一个模型,或通过推理数据的参数修改模型内部权重,然后再进行模型调用,实现同一模型适应不通场景下的推理。dl_inference开放了模型调用的过程,提高了模型实现的灵活性,从而满足不同业务方的定制化需求。
提供丰富的应用示例
为了方便大家使用,dl_inference提供了更多模型案例供用户参考,包括: qa_match (由58同城开源的基于深度学习的问答匹配工具)训练模型、推荐 排序 和图像识别模型。
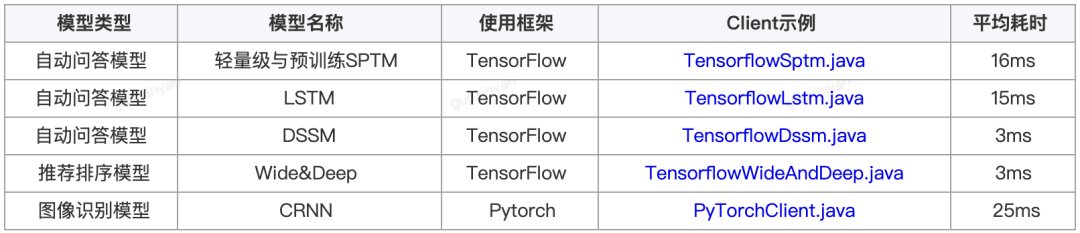
注:以上数据均在CPU Intel(R) Xeon(R) CPU E5-2620 v4上测试得到
另外在2021年7月58同城举办的第二届算法大赛中,dl_inference发布了Baseline模型,为参选选手提供示例,拓展解题思路。Baseline模型基于MMoE模型完成,详细可参考文章 《WPAI中使用MMoE模型完成58同城AI算法大赛》 。
04 总结
dl_inference2020年3月发布以来完成的三次版本迭代,丰富了使用案例,支持了Caffe框架训练的模型推理,提升了模型在GPU和CPU上推理性能。
后续我们还将对这三次版本迭代进行线上的沙龙直播,敬请期待!
未来我们会继续优化扩展dl_inference的能力,计划开源如下
1、持续优化CPU上推理性能,如兼容Intel的OpenVINO加速组件。
2、持续优化GPU上推理性能,如兼容INT8低精度推理、支持更多的算子等。
项目地址:https://github.com/wuba/dl_inference
贡献指引:
本次开源只是dl_inference贡献社区的一小步,我们真挚地希望开发者向我们提出宝贵的意见和建议。您可以挑选以下方式向我提交反馈建议和问题
1、在https://github.com/wuba/dl_inference 提交PR或者lssue。
2、邮件发送至 ailab-opensource@58.com
参考资料:
[1] 通过Intel MKL优化TensorFlow:https://www.intel.cn/content/www/cn/zh/developer/articles/technical/tensorflow-optimizations-on-modern-intel-architecture.html
[2] 在Intel CPU上通过参数配置优化TensorFlow性能:https://www.intel.com/content/www/us/en/developer/articles/technical/maximize-tensorflow-performance-on-cpu-considerations-and-recommendations-for-inference.html
[3] Intel深度学习加速调优指南:https://www.intel.cn/content/www/cn/zh/developer/articles/technical/deep-learning-with-avx512-and-dl-boost.html
[4] NVIDIA TensorRT介绍:https://docs.nvidia.com/deeplearning/tensorrt/
[5] NVIDIA Triton-Inference-Server介绍:https://developer.nvidia.com/nvidia-triton-inference-server
以上所述就是小编给大家介绍的《开源 | dl_inference 更新:增加 TensorRT、MKL 集成,提高深度学习模型推理速度》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
猜你喜欢:
- 阿里开源深度神经网络推理引擎 MNN
- 英伟达深度学习推理引擎TensorRT,现在开源了
- 开源|dl_inference:通用深度学习推理服务
- Facebook 开源 FBGEMM,服务器端推理优化库
- Facebook 开源 FBGEMM,服务器端推理优化库
- 微软开源用于机器学习模型的高性能推理引擎ONNX
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。


HTML 编码/解码
HTML 编码/解码

SHA 加密
SHA 加密工具