内容简介:由 EMQ 开源的分布式云原生流数据库 HStreamDB v0.6 现已正式发布! HStreamDB 是首个专为流数据设计的云原生流数据库,致力于大规模数据流的高效存储和管理。不仅支持在动态变化的数据流上进行复杂的实时分析,还...

由 EMQ 开源的分布式云原生流数据库 HStreamDB v0.6 现已正式发布!
HStreamDB 是首个专为流数据设计的云原生流数据库,致力于大规模数据流的高效存储和管理。不仅支持在动态变化的数据流上进行复杂的实时分析,还支持对大规模数据流接入、存储、处理、分发等环节的一站式管理,未来在 IoT、互联网、金融等领域的实时流数据分析和处理场景将发挥重要作用。
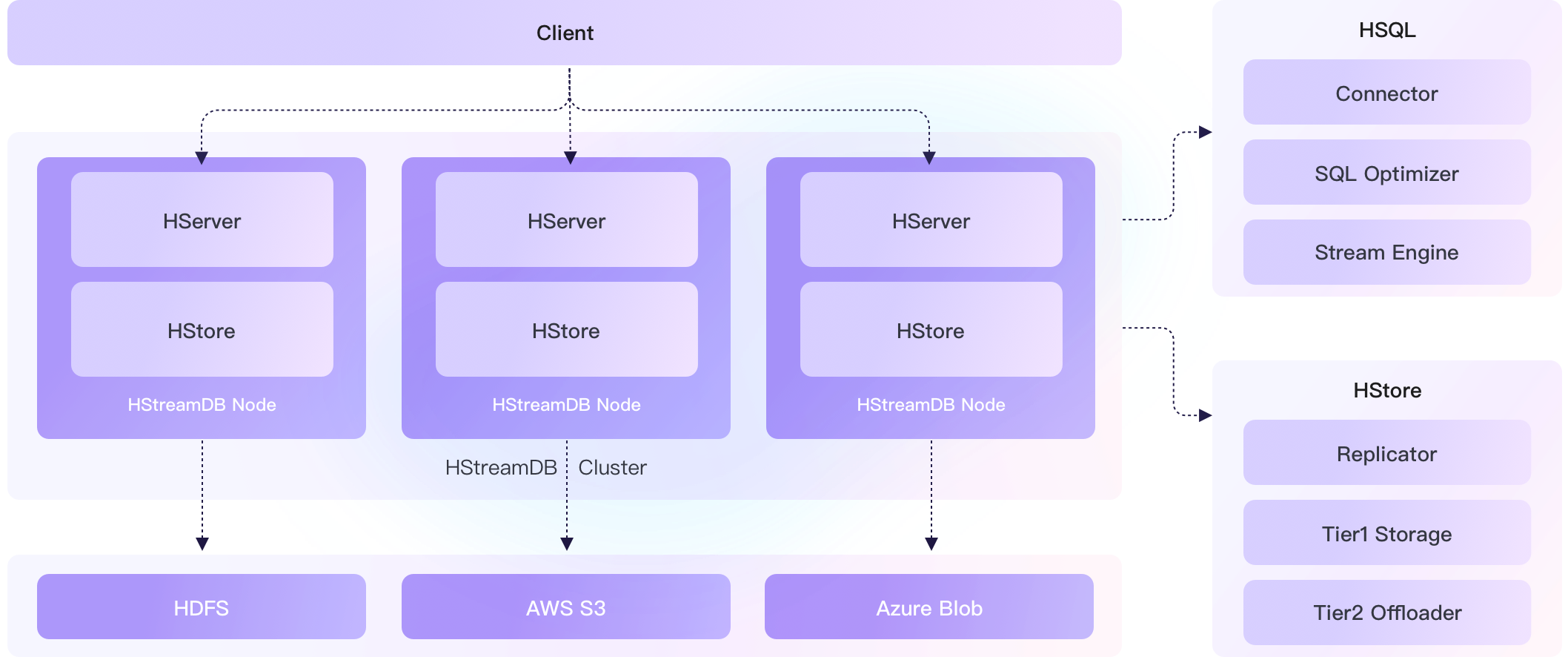
在全新的 v0.6 版本中,我们为 HServer 开启了集群模式,可以根据客户端请求和计算任务的规模对计算层节点进行弹性扩展。同时新增共享订阅功能,允许多个客户端在同一个订阅上并行消费,极大提升了实时数据的分发能力。
最新版本下载地址:Docker Hub
新版本功能速览
支持集群模式, HServer 水平扩展性提升
HStreamDB v0.6 正式支持 HServer 的集群模式。实现集群模式后,HServer 可以快速水平扩展,支持节点健康检测和失效恢复,提升了 HStreamDB 的容错能力和扩展能力。与此同时,HServer 支持负载均衡。通过监测集群中所有节点的实时负载状态,将计算任务合理分配到不同节点,实现了集群资源的高效利用。
关于集群的启动和部署,可以参考以下文档:
- https://hstream.io/docs/en/latest/start/start-hserver-cluster.html#start-local-hserver-cluster-with-docker
- https://hstream.io/docs/en/latest/deployment/deploy-k8s.html
支持共享订阅,数据分发实时性增强
在 HStreamDB v0.6 中,我们对之前的订阅模式进行了重构,推出全新的共享订阅功能。
在之前的版本中,一个订阅同一时间只能被一个客户端消费,这限制了 HStreamDB 对数据的实时分发能力。全新的共享订阅功能引入了消费者组(Consumer Group)的概念,通过消费者组来统一管理对 stream 的消费。一个 stream 的所有消费者都会加入到同一个消费者组中,客户端可以在任何时候加入或者退出当前消费者组。
HStreamDB 目前支持 at least once 的消费语义。HServer 将通过 round-robin 的方式向消费者组中的消费者派发数据。所有未收到客户端 Ack 回复的消息都会在超时后被 HServer 自动重发给可用的消费者。同一个消费者组中的所有成员共享消费进度,HServer 负责维护消费者组的消费进度。HStreamDB 的高容错能力保证了任意节点的崩溃不会影响对 stream 的消费。
与此同时,HSteamDB 的 Java 客户端 也更新至 v0.6 版本,完整支持 HStreamDB 的集群和共享订阅功能。新的 Java 客户端重构了订阅部分的 API,增强了客户端的易用性。关于 HStreamDB Java Client 的使用可参考 hstreamdb-java/examples at main · hstreamdb/hstreamdb-java
新增 HStream Metrics,系统可观测性增强
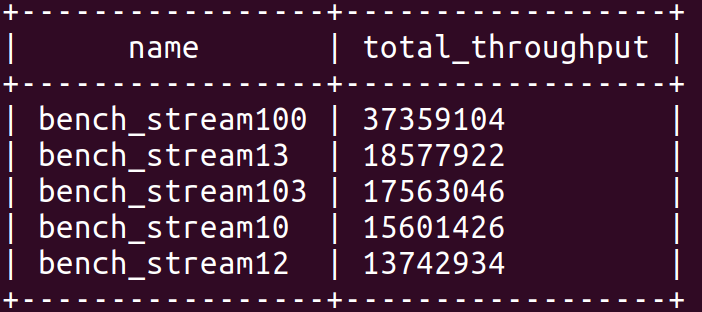
在 HStreamDB v0.6 中,新增了基本的指标统计功能,比如 stream 的写入速率,消费速率等。
用户可以通过如下方式在 HStream CLI 查看这些指标:
-- Find the top 5 streams that have had the highest throughput in the last 1 minutes.
sql>
SELECT streams.name, sum(append_throughput.throughput_1min) AS total_throughput
FROM append_throughput
LEFT JOIN streams ON streams.name = append_throughput.stream_name
GROUP BY stream_name
ORDER BY total_throughput DESC
LIMIT 0, 5;
查询结果如下图所示:
新增数据写入 Rest API,基于 HStreamDB 的更多可能
现在可以使用任何语言通过 Rest API 向 HStreamDB 写入数据,后续我们计划将开放更多 Rest API,方便开源用户围绕 HStreamDB 进行二次开发,例如:通过 HStream Rest API 结合 EMQ X 开源版的 Webhook 功能,能够实现 EMQ X 和 HStreamDB 的快速集成。

发展规划
在 HStreamDB 的后续版本,我们将主要围绕以下目标继续迭代:
- 提升集群的稳定性: 增加更多集成测试,错误注入测试,改进代码设计和修复 bug
- 改善可用性和运维能力:改进 CLI tools,配置,Rest API,Java Client
- 增加 stream 的扩展能力:当前 HStreamDB 可以高效支持大量 stream 的同时并发读写,但是当单个 stream 成为热点后会面临性能瓶颈,后续我们计划通过透明分区的方式解决这一问题,核心原则是尽力保持用户层面概念的简单性,将分区之类的复杂性封装在内部实现里,相比其它现有的解决方案,这将极大提升用户的使用体验。
HStreamDB 是数据基础设施迈向实时数据时代的一次开创性尝试。随着研发迭代的不断推进,相信未来从多种数据源持续产生的大规模流数据将通过 HStreamDB 得到更加高效的存储管理和实时分析,从数据获取洞察、产生价值的过程将被极大加速。 敬请关注 HStreamDB 的后续进展。
以上所述就是小编给大家介绍的《HStreamDB v0.6 正式发布:水平扩展性、数据分发实时性提升》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
猜你喜欢:
- 如何增强推荐系统模型更新的实时性?
- 为无服务器的Web应用程序带来实时性 - ITNEXT
- iOS的高性能、高实时性key-value持久化组件
- Storm Topology : Elasticsearch & Redis 构建实时性低延时数据统计分析 呈现大数据分析效果
- 写扩展性好的代码:函数
- 如何借助 Proxy 代理,提升架构扩展性
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Design for Hackers
David Kadavy / Wiley / 2011-10-18 / USD 39.99
Discover the techniques behind beautiful design?by deconstructing designs to understand them The term ?hacker? has been redefined to consist of anyone who has an insatiable curiosity as to how thin......一起来看看 《Design for Hackers》 这本书的介绍吧!


