内容简介:小伙伴们大家好,JuiceFS v0.17 在国庆小长假来临之际如期发布了!这是我们在 2021 年秋季推出的第二个版本,让我们直奔主题,看看都有哪些新变化吧。 本次更新累计 80+ 提交,共有 9 位来自 JuiceFS 社区的小伙伴...
小伙伴们大家好,JuiceFS v0.17 在国庆小长假来临之际如期发布了!这是我们在 2021 年秋季推出的第二个版本,让我们直奔主题,看看都有哪些新变化吧。
本次更新累计 80+ 提交,共有 9 位来自 JuiceFS 社区的小伙伴在 GitHub 上贡献代码。在这里,我们向每一位贡献者表示最诚挚的感谢,同时欢迎屏幕前的你也加入到 JuiceFS 开源社区,贡献代码、文档或讨论想法。
通过 LTP 1270 项测试,Linux 系统下兼容性更完美
JuiceFS 的最新版本针对 Linux 系统环境做了进一步的优化,改进了 rename 和 setxattr 读其他参数的支持,顺利通过了 LTP 的 1270 项测试。
LTP(Linux Test Project)是一个由 IBM,Cisco 等多家公司联合开发维护的项目,旨在为开源社区提供一个验证 Linux 可靠性和稳定性的测试集。LTP 中包含了各种 工具 来检验 Linux 内核和相关特性。
测试结果:
Testcase Result Exit Value
-------- ------ ----------
fcntl17 FAIL 7
fcntl17_64 FAIL 7
getxattr05 CONF 32
ioctl_loop05 FAIL 4
ioctl_ns07 FAIL 1
lseek11 CONF 32
open14 CONF 32
openat03 CONF 32
setxattr03 FAIL 6
-----------------------------------------------
Total Tests: 1270
Total Skipped Tests: 4
Total Failures: 5
Kernel Version: 5.4.0-1029-aws
Machine Architecture: x86_64
其中,跳过和失败的项目主要是由于几个尚未支持的功能,详情见此文档。
优化存储临时数据的性能
针对 Spark 的 shuffle 文件等临时数据存储需求,社区贡献者祝威廉(@allwefantasy)给 JuiceFS 贡献了数据延迟上传功能,它可以让 JuiceFS 优先将数据写入到本地缓存盘中,如果这些数据在短时间内又被删除,则无需写入对象存储,可以提供接近本地盘的读写性能。而当写入数据很多时,又会自动写到对象存储来释放本地盘空间,再也不用担心 shuffle 数据把磁盘写满了。
这个新功能让 JuiceFS 可以作为一个弹性本地盘使用,为临时数据提供无限存储空间和低延时访问。
为了进一步提升性能,还新增了一个运行在客户端内存中的元数据引擎(MemKV)。与其他元数据引擎一样,MemKV 的作用也是用来保存数据相关的元信息,但它不持久化,客户端 umount 以后,MemKV 的元数据就释放了。MemKV 完全在内存中运行,有着绝对的性能优势,非常适合用作临时文件的存储场景。
TiKV 元数据引擎在 Hadoop 场景中性能提升 5 倍
JuiceFS Java 客户端需要频繁做路径解析,Redis 引擎通过 Lua 实现了服务器端的多级路径解析,而 SQL 和 TiKV 引擎仍然需要多次元数据请求才能解析一个路径,尤其是当路径比较深时对影响有比较大的影响。
为了解决这个问题,本次更新在 JuiceFS Hadoop SDK 客户端中引入了类似于 Linux 内核的元数据缓存机制,可以分别通过参数控制目录、文件和属性的过期时间。可以通过如下的方式启用:
<property>
<name>juicefs.attr-cache</name>
<value>3</value>
</property>
<property>
<name>juicefs.entry-cache</name>
<value>3</value>
</property>
<property>
<name>juicefs.dir-entry-cache</name>
<value>3</value>
</property>
以下是对 9 层目录的元数据性能测试,可以看到启用元数据缓存够大幅提升元数据操作的性能。(数值代表操作的时延,越小越好。)

但需要注意的是,开启元数据缓存后会影响多客户端之间的一致性(有限时间窗口的最终一致性),比如一个客户端删除了某个文件后,其他节点可能因为缓存未到期,仍然认为文件存在。因此,一般建议在查询场景下使用该功能。如果是混合读写的场景,建议适当开启目录和属性的缓存,而关闭文件项的缓存。
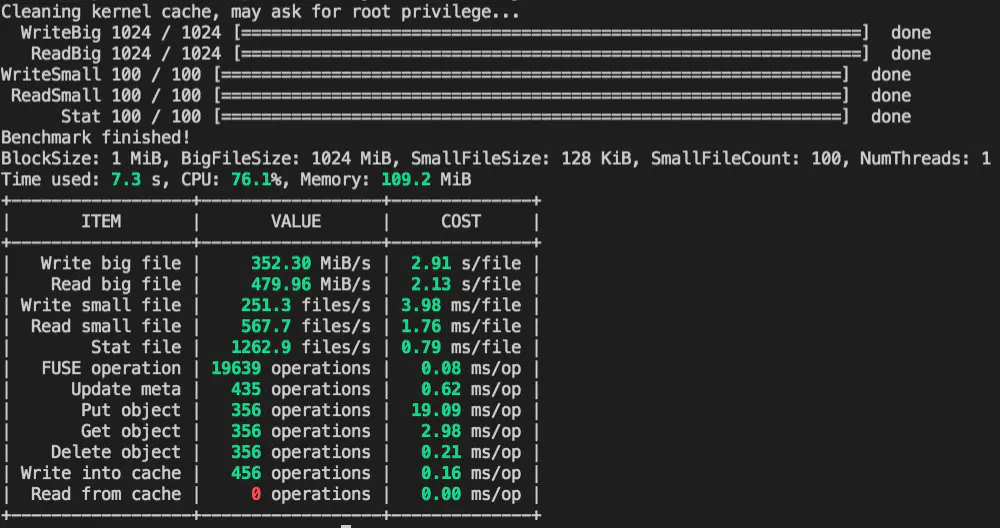
1 分钟上手性能测试,结果一目了然
我们为 JuiceFS 内置的性能测试工具 bench 的结果做了进一步的优化,在简洁直观的基础上,进一步的让关键数据高亮显示,如果某项性能数据偏离正常区间,会显示为黄色甚至红色,建议特别关注下。
有关 JuiceFS 新版的更多内容,欢迎访问 GitHub 项目主页了解详情。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- [译] 通过测试学习 Go 语言
- 通过Java连接mysql对反斜杠“\”转义的测试
- 通过libFuzzer实现结构敏感型的模糊测试技术(上)
- 通过libFuzzer实现结构敏感型的模糊测试技术(下)
- [ Laravel从入门到精通 ] 测试系列 —— 通过测试驱动开发构建待办任务项目(一):后端 API 接口篇
- CakePHP 3.6.16 发布,PHP 7.3 构建测试全部通过
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Compilers
Alfred V. Aho、Monica S. Lam、Ravi Sethi、Jeffrey D. Ullman / Addison Wesley / 2006-9-10 / USD 186.80
This book provides the foundation for understanding the theory and pracitce of compilers. Revised and updated, it reflects the current state of compilation. Every chapter has been completely revised ......一起来看看 《Compilers》 这本书的介绍吧!


