内容简介:数据采集ETL工具 Elasticsearch-datatran v6.3.1 发布,Elasticsearch-datatran 由 bboss 开源的数据采集同步ETL工具,提供数据采集、数据处理清洗和数据入库功能。支持在Elasticsearch、关系数据库(mysql,oracle...
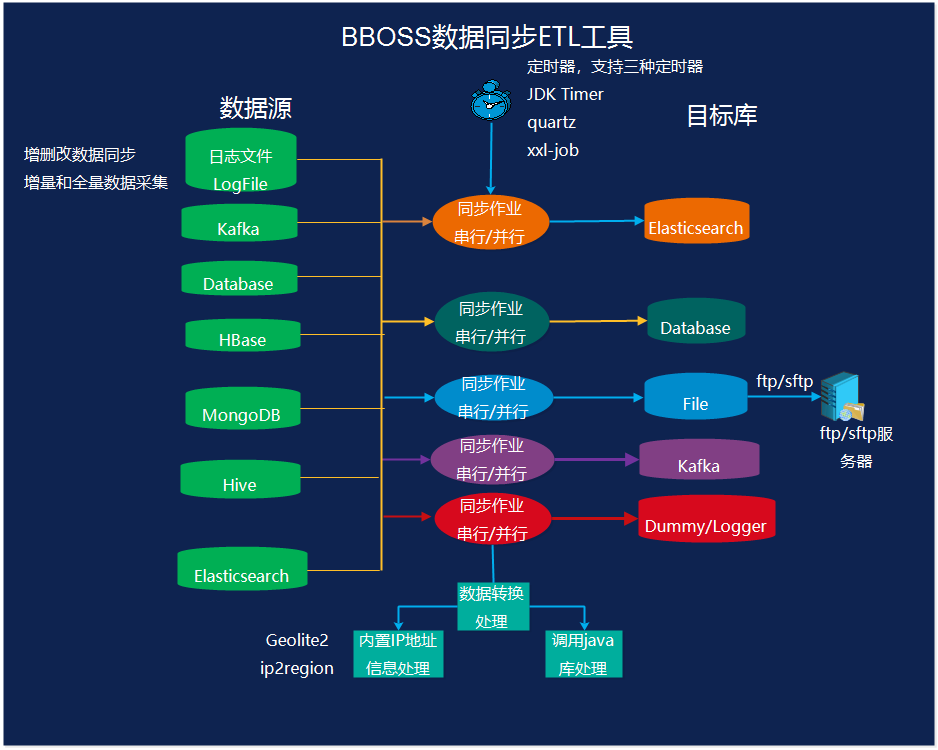
数据采集ETL工具 Elasticsearch-datatran v6.3.1 发布,Elasticsearch-datatran 由 bboss 开源的数据采集同步ETL工具,提供数据采集、数据处理清洗和数据入库功能。支持在Elasticsearch、关系数据库(mysql,oracle,db2,sqlserver、达梦等)、 Mongodb 、HBase、Hive、Kafka、文本文件、SFTP/FTP多种数据源之间进行海量数据同步;支持日志文件实时增量采集到kafka/elasticsearch/database。
Elasticsearch版本兼容性:支持各种Elasticsearch版本(1.x,2.x,5.x,6.x,7.x,+)之间相互数据迁移
6.3.1 功能改进
-
日志采集探针,属性maxBytes为0或者负数时忽略记录长度截取
-
日志采集探针,增加忽略条件匹配类型文件记录包含与排除条件匹配类型: REGEX_MATCH,REGEX_CONTAIN,STRING_CONTAIN, STRING_EQUALS,STRING_PREFIX,STRING_END; 使用案例:
config.addConfig(new FileConfig(logPath,//指定目录
fileName+".log",//指定文件名称,可以是正则表达式
startLabel)//指定多行记录的开头识别标记,正则表达式
.setCloseEOF(false)//已经结束的文件内容采集完毕后关闭文件对应的采集通道,后续不再监听对应文件的内容变化
.addField("tag",fileName.toLowerCase())//添加字段tag到记录中
.setEnableInode(true)
.setIncludeLines(levelArr, LineMatchType.STRING_CONTAIN)
3.默认采用异步机制保存增量同步数据状态,大幅提升数据同步效率,降低同步功耗,可以通过以下机制关闭异步机制:
importBuilder.setAsynFlushStatus(false);
bboss数据采集ETL案例大全
https://esdoc.bbossgroups.com/#/bboss-datasyn-demo
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Game Engine Architecture, Second Edition
Jason Gregory / A K Peters/CRC Press / 2014-8-15 / USD 69.95
A 2010 CHOICE outstanding academic title, this updated book covers the theory and practice of game engine software development. It explains practical concepts and techniques used by real game studios,......一起来看看 《Game Engine Architecture, Second Edition》 这本书的介绍吧!

HTML 编码/解码
HTML 编码/解码

正则表达式在线测试
正则表达式在线测试