内容简介:OpenKruise[1] 是阿里云开源的云原生应用自动化管理套件,也是当前托管在 Cloud Native Computing Foundation (CNCF) 下的 Sandbox 项目。它来自阿里巴巴多年来容器化、云原生的技术沉淀,是阿里内部生产环境大规...

OpenKruise[1] 是阿里云开源的云原生应用自动化管理套件,也是当前托管在 Cloud Native Computing Foundation (CNCF) 下的 Sandbox 项目。它来自阿里巴巴多年来容器化、云原生的技术沉淀,是阿里内部生产环境大规模应用的基于 Kubernetes 之上的标准扩展组件,也是紧贴上游社区标准、适应互联网规模化场景的技术理念与最佳实践。
OpenKruise 在 2021 年 5 月 20 日发布了最新的 v0.9.0 版本(ChangeLog[2]),新增了 Pod 容器重启、资源级联删除防护等重磅功能,本文以下对新版本做整体的概览介绍。
Pod 容器重启/重建
“重启” 是一个很朴素的需求,即使日常运维的诉求,也是技术领域较为常见的 “恢复手段”。而在原生的 Kubernetes 中,并没有提供任何对容器粒度的操作能力,Pod 作为最小操作单元也只有创建、删除两种操作方式。
有的同学可能会问,在云原生时代,为什么用户还要关注容器重启这种运维操作呢?在理想的 Serverless 模式下,业务只需要关心服务自身就好吧?
这来自于云原生架构和过去传统基础基础设施的差异性。在传统的物理机、虚拟机时代,一台机器上往往会部署和运行多个应用的实例,并且机器和应用的生命周期是不同的;在这种情况下,应用实例的重启可能仅仅是一条 systemctl 或 supervisor 之类的指令,而无需将整个机器重启。然而,在容器与云原生模式下,应用的生命周期是和 Pod 容器绑定的;即常规情况下,一个容器只运行一个应用进程,一个 Pod 也只提供一个应用实例的服务。
基于上述的限制,目前原生 Kubernetes 之下是没有 API 来为上层业务提供容器(应用)重启能力的。而 Kruise v0.9.0 版本提供了一种单 Pod 维度的容器重启能力,兼容 1.16 及以上版本的标准 Kubernetes 集群。在安装或升级 Kruise[3] 之后,只需要创建 ContainerRecreateRequest(简称 CRR) 对象来指定重启,最简单的 YAML 如下:
apiVersion: apps.kruise.io/v1alpha1kind: ContainerRecreateRequestmetadata:namespace: pod-namespacename: xxxspec:podName: pod-namecontainers:- name: app- name: sidecar
其中,namespace 需要与要操作的 Pod 在同一个命名空间,name 可自选。spec 中 podName 是 Pod 名字,containers 列表则可以指定 Pod 中一个或多个容器名来执行重启。
除了上述必选字段外,CRR 还提供了多种可选的重启策略:
spec:# ...strategy:failurePolicy: FailorderedRecreate: falseterminationGracePeriodSeconds: 30unreadyGracePeriodSeconds: 3minStartedSeconds: 10activeDeadlineSeconds: 300ttlSecondsAfterFinished: 1800
-
failurePolicy:Fail 或 Ignore,默认 Fail;表示一旦有某个容器停止或重建失败,CRR 立即结束。
-
orderedRecreate:默认 false;true 表示列表有多个容器时,等前一个容器重建完成了,再开始重建下一个。
-
terminationGracePeriodSeconds:等待容器优雅退出的时间,不填默认用 Pod 中定义的时间。
-
unreadyGracePeriodSeconds:在重建之前先把 Pod 设为 not ready,并等待这段时间后再开始执行重建。
-
-
注:该功能依赖于 KruisePodReadinessGate 这个 feature-gate 要打开,后者会在每个 Pod 创建的时候注入一个 readinessGate。否则,默认只会给 Kruise workload 创建的 Pod 注入 readinessGate,也就是说只有这些 Pod 才能在 CRR 重建时使用 unreadyGracePeriodSeconds。
-
-
minStartedSeconds:重建后新容器至少保持运行这段时间,才认为该容器重建成功。
-
activeDeadlineSeconds:如果 CRR 执行超过这个时间,则直接标记为结束(未完成的容器标记为失败)。
-
ttlSecondsAfterFinished:CRR 结束后,过了这段时间自动被删除掉。
实现原理:当用户创建了 CRR 后,经过了 kruise-manager 中心端的初步处理,会被 Pod 所在节点上的 kruise-daemon 收到并开始执行。执行的过程如下:
-
如果 Pod 容器定义了 preStop,kruise-daemon 会先走 CRI 运行时 exec 到容器中执行 preStop。
-
如果没有 preStop 或执行完成,kruise-daemon 调用 CRI 接口将容器停止。
-
kubelet 感知到容器退出,则会新建一个 “序号” 递增的新容器,并开始启动(以及执行 postStart)。
-
kruise-daemon 感知到新容器启动成功,上报 CRR 重启完成。
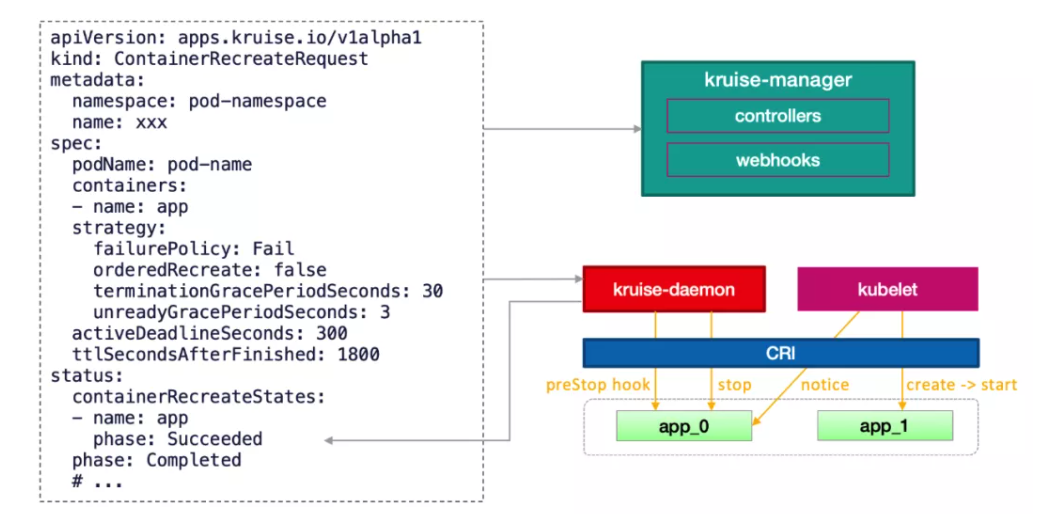
上述的容器 “序号” 其实就对应了 Pod status 中 kubelet 上报的 restartCount。因此,在容器重启后会看到 Pod 的 restartCount 增加。另外,因为容器发生了重建,之前临时写到旧容器 rootfs 中的文件会丢失,但是 volume mount 挂载卷中的数据仍然存在。
级联删除防护
Kubernetes 的面向终态自动化是一把 “双刃剑”,它既为应用带来了声明式的部署能力,同时也潜在地会将一些误操作行为被终态化放大。例如它的 “级联删除” 机制,即正常情况(非 orphan 删除)下一旦父类资源被删除,则所有子类资源都会被关联删除:
-
删除一个 CRD,其所有对应的 CR 都被清理掉。
-
删除一个 namespace,这个命名空间下包括 Pod 在内所有资源都被一起删除。
-
删除一个 workload(Deployment/StatefulSet/...),则下属所有 Pod 被删除。
类似这种 “级联删除” 带来的故障,我们已经听到不少社区 K8s 用户和开发者带来的抱怨。对于任何一家企业来说,其生产环境发生这种规模误删除都是不可承受之痛,阿里巴巴也不例外。
因此,在 Kruise v0.9.0 版本中,我们将阿里内部所做的防级联删除能力输出到社区,期望能为更多的用户带来稳定性保障。在当前版本中如果需要使用该功能,则在安装或升级 Kruise 的时候需要显式打开 ResourcesDeletionProtection 这个 feature-gate。
对于需要防护删除的资源对象,用户可以给其打上 policy.kruise.io/delete-protection 标签,value 可以有两种:
-
Always: 表示这个对象禁止被删除,除非上述 label 被去掉。
-
Cascading:这个对象如果还有可用的下属资源,则禁止被删除。
目前支持的资源类型、以及 cascading 级联关系如下:
| 类型 |
组 |
版本 |
级联校验逻辑 |
| Namespace |
core |
v1 |
namespace 下是否还有正常的 Pod |
| CustomResourceDefinition |
apiextensions.k8s.io |
v1beta1、v1 |
CRD 下是否还有存量的 CR |
| Deployment |
apps |
v1 |
replicas 是否为 0 |
| StatefulSet |
apps |
v1 |
replicas 是否为 0 |
| ReplicaSet |
apps |
v1 |
replicas 是否为 0 |
| CloneSet |
apps.kruise.io |
v1alpha1 |
replicas 是否为 0 |
| StatefulSet |
apps.kruise.io |
v1alpha1、v1beta1 |
replicas 是否为 0 |
| UnitedDeployment |
apps.kruise.io |
v1alpha1 |
replicas 是否为 0 |
CloneSet 新增功能
1. 删除优先级
controller.kubernetes.io/pod-deletion-cost[4] 是从 Kubernetes 1.21 版本后加入的 annotation,ReplicaSet 在缩容时会参考这个 cost 数值来排序。CloneSet 从 Kruise v0.9.0 版本后也同样支持了这个功能。
用户可以把这个 annotation 配置到 pod 上,它的 value 数值是 int 类型,表示这个 pod 相较于同个 CloneSet 下其他 pod 的 "删除代价",代价越小的 pod 删除优先级相对越高。没有设置这个 annotation 的 pod 默认 deletion cost 是 0。
注意这个删除顺序并不是强制保证的,因为真实的 pod 的删除类似于下述顺序:
-
未调度 < 已调度
-
PodPending < PodUnknown < PodRunning
-
Not ready < ready
-
较小 pod-deletion cost < 较大 pod-deletion cost
-
处于 Ready 时间较短 < 较长
-
容器重启次数较多 < 较少
-
创建时间较短 < 较长
2. 配合原地升级的镜像预热
当使用 CloneSet 做应用原地升级时,只会升级容器镜像、而 Pod 不会发生重建。这就保证了 Pod 升级前后所在 node 不会发生变化,从而在原地升级的过程中,如果 CloneSet 提前在所有 Pod 节点上先把新版本镜像拉取好,则在后续的发布批次中 Pod 原地升级速度会得到大幅度提高。
在当前版本中如果需要使用该功能,则在安装或升级 Kruise 的时候需要显式打开 PreDownloadImageForInPlaceUpdate 这个 feature-gate。打开后,当用户更新了 CloneSet template 中的镜像、且发布策略支持原地升级,则 CloneSet 会自动为这个新镜像创建 ImagePullJob 对象(OpenKruise 提供的批量镜像预热功能),来提前在 Pod 所在节点上预热新镜像。
默认情况下 CloneSet 给 ImagePullJob 配置的并发度是 1,也就是一个个节点拉镜像。如果需要调整,你可以在 CloneSet annotation 上设置其镜像预热时的并发度:
apiVersion: apps.kruise.io/v1alpha1kind: CloneSetmetadata:annotations:apps.kruise.io/image-predownload-parallelism: "5"
3. 先扩再缩的 Pod 置换方式
在过去版本中,CloneSet 的 maxUnavailable、maxSurge 策略只对应用发布过程生效。而从 Kruise v0.9.0 版本开始,这两个策略同样会对 Pod 指定删除生效。
也就是说,当用户通过 podsToDelete 或 apps.kruise.io/specified-delete: true 方式(具体见官网文档)来指定一个或多个 Pod 期望删除时,CloneSet 只会在当前不可用 Pod 数量(相对于 replicas 总数)小于 maxUnavailable 的时候才执行删除。同时,如果用户配置了 maxSurge 策略,则 CloneSet 有可能会先创建一个新 Pod、等待新 Pod ready、再删除指定的旧 Pod。
具体采用什么样的置换方式,取决于当时的 maxUnavailable 和实际不可用 Pod 数量。比如:
-
对于一个 CloneSet
maxUnavailable=2, maxSurge=1且有一个pod-a处于不可用状态, 如果你对另一个pod-b指定删除, 那么 CloneSet 会立即删除它,然后创建一个新 Pod。 -
对于一个 CloneSet
maxUnavailable=1, maxSurge=1且有一个pod-a处于不可用状态, 如果你对另一个pod-b指定删除, 那么 CloneSet 会先新建一个 Pod、等待它 ready,最后再删除pod-b。 -
对于一个 CloneSet
maxUnavailable=1, maxSurge=1且有一个pod-a处于不可用状态, 如果你对这个pod-a指定删除, 那么 CloneSet 会立即删除它,然后创建一个新 Pod。 -
...
4. 基于 partition 终态的高效回滚
在原生的 workload 中,Deployment 自身发布不支持灰度发布,StatefulSet 有 partition 语义来允许用户控制灰度升级的数量;而 Kruise workload 如 CloneSet、Advanced StatefulSet,也都提供了 partition 来支持灰度分批。
对于 CloneSet,Partition 的语义是保留旧版本 Pod 的数量或百分比。比如说一个 100 个副本的 CloneSet,在升级镜像时将 partition 数值阶段性改为 80 -> 60 -> 40 -> 20 -> 0,则完成了分 5 批次发布。
但过去,不管是 Deployment、StatefulSet 还是 CloneSet,在发布的过程中如果想要回滚,都必须将 template 信息(镜像)重新改回老版本。后两者在灰度的过程中,将 partition 调小会触发旧版本升级为新版本,但再次 partition 调大则不会处理。
从 v0.9.0 版本开始,CloneSet 的 partition 支持了 “终态回滚” 功能。如果在安装或升级 Kruise 的时候打开了 CloneSetPartitionRollback 这个 feature-gate,则当用户将 partition 调大时,CloneSet 会将对应数量的新版本 Pod 重新回滚到老版本。
这样带来的好处是显而易见的:在灰度发布的过程中,只需要前后调节 partition 数值,就能灵活得控制新旧版本的比例数量。但需要注意的是,CloneSet 所依据的 “新旧版本” 对应的是其 status 中的 updateRevision 和 currentRevision:
-
updateRevision:对应当前 CloneSet 所定义的 template 版本。
-
currentRevision:该 CloneSet 前一次全量发布成功的 template 版本。
5. 短 hash
默认情况下,CloneSet 在 Pod label 中设置的 controller-revision-hash 值为 ControllerRevision 的完整名字,比如:
apiVersion: v1kind: Podmetadata:labels:controller-revision-hash: demo-cloneset-956df7994
它是通过 CloneSet 名字和 ControllerRevision hash 值拼接而成。通常 hash 值长度为 8~10 个字符,而 Kubernetes 中的 label 值不能超过 63 个字符。因此 CloneSet 的名字一般是不能超过 52 个字符的,如果超过了,则无法成功创建出 Pod。
在 v0.9.0 版本引入了 CloneSetShortHash 新的 feature-gate。如果它被打开,CloneSet 只会将 Pod 中的 controller-revision-hash 的值只设置为 hash 值,比如 956df7994,因此 CloneSet 名字的长度不会有任何限制了。(即使启用该功能,CloneSet 仍然会识别和管理过去存量的 revision label 为完整格式的 Pod。)
SidecarSet
sidecar 热升级功能
SidecarSet 是 Kruise 提供的独立管理 sidecar 容器的 workload。用户可以通过 SidecarSet,来在一定范围的 Pod 中注入和升级指定的 sidecar 容器。
默认情况下,sidecar 的独立原地升级是先停止旧版本的容器,然后创建新版本的容器。这种方式更加适合不影响Pod服务可用性的sidecar容器,比如说日志收集 agent,但是对于很多代理或运行时的 sidecar 容器,例如 Istio Envoy,这种升级方法就有问题了。Envoy 作为 Pod 中的一个代理容器,代理了所有的流量,如果直接重启升级,Pod 服务的可用性会受到影响。如果需要单独升级 envoy sidecar,就需要复杂的 grace 终止和协调机制。所以我们为这种 sidecar 容器的升级提供了一种新的解决方案,即热升级(hot upgrade)。
apiVersion: apps.kruise.io/v1alpha1kind: SidecarSetspec:# ...containers:- name: nginx-sidecarimage: nginx:1.18lifecycle:postStart:exec:command:- /bin/bash- -c- /usr/local/bin/nginx-agent migrateupgradeStrategy:upgradeType: HotUpgradehotUpgradeEmptyImage: empty:1.0.0
-
upgradeType: HotUpgrade代表该sidecar容器的类型是hot upgrade,将执行热升级方案hotUpgradeEmptyImage: 当热升级sidecar容器时,业务必须要提供一个empty容器用于热升级过程中的容器切换。empty容器同sidecar容器具有相同的配置(除了镜像地址),例如:command, lifecycle, probe等,但是它不做任何工作。
-
lifecycle.postStart: 状态迁移,该过程完成热升级过程中的状态迁移,该脚本需要由业务根据自身的特点自行实现,例如:nginx热升级需要完成Listen FD共享以及流量排水(reload)。
具体 sidecar 注入和热升级流程,请参考官网文档。
最后
了解上述能力的更多信息,可以访问官网文档[5]。对 OpenKruise 感兴趣的同学欢迎参与我们的社区建设,已经使用了 OpenKruise 项目的用户请在 issue[6] 中登记。
参考资料
[1] OpenKruise:https://github.com/openkruise/kruise
[2] ChangeLog:https://github.com/openkruise/kruise/blob/master/CHANGELOG.md
[3] 安装或升级 Kruise:https://openkruise.io/zh-cn/docs/installation.html
[4] controller.kubernetes.io/pod-deletion-cost:https://kubernetes.io/docs/reference/labels-annotations-taints/#pod-deletion-cost
[5] 官网文档:https://openkruise.io/zh-cn/docs/what_is_openkruise.html
[6] issue:https://github.com/openkruise/kruise/issues/289
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
- Golang实现平滑重启(优雅重启)
- SOFAMosn 无损重启/升级
- nginx-平滑重启
- Unbuntu 自动重启MySQL
- Zabbix监控Windows进程重启
- Golang代码修改后自动重启
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

函数式算法设计珠玑
Richard Bird / 苏统华、孙芳媛、郝文超、徐琴 / 机械工业出版社 / 2017-4-1 / 69.00
本书采用完全崭新的方式介绍算法设计。全书由30个珠玑构成,每个珠玑单独列为一章,用于解决一个特定编程问题。这些问题的出处五花八门,有的来自游戏或拼图,有的是有趣的组合任务,还有的是散落于数据压缩及字串匹配等领域的更为熟悉的算法。每个珠玑以使用函数式编程语言Haskell对问题进行描述作为开始,每个解答均是诉诸于函数式编程法则从问题表述中计算得到。本书适用于那些喜欢学习算法设计思想的函数式编程人员、......一起来看看 《函数式算法设计珠玑》 这本书的介绍吧!


