内容简介:Apache Flink 1.13.0 现已发布,该版本使流处理应用像其他应用一样自然和简单地管理,只要改变并行进程的数量,就可以像其他应用程序一样扩展流媒体应用程序的运行。 反应式扩展 用户现在可以为 Flink 应用程序配...

Apache Flink 1.13.0 现已发布,该版本使流处理应用像其他应用一样自然和简单地管理,只要改变并行进程的数量,就可以像其他应用程序一样扩展流媒体应用程序的运行。
反应式扩展
用户现在可以为 Flink 应用程序配置一个自动缩放器,但要在配置自动缩放器的时候注意到重新缩放的成本。有状态的流媒体应用程序必须在扩展时移动状态。要尝试反应式扩展模式,请添加 scheduler-mode: reactive 配置项,并部署一个应用程序集群(独立的或 Kubernetes)。
分析应用程序性能
Flink 1.13 带来了一个改进的背压度量系统(使用任务邮箱时间,而不是线程堆栈采样),以及一个重新设计的作业数据流的图形表示,用颜色编码和繁忙程度和背压的比例。
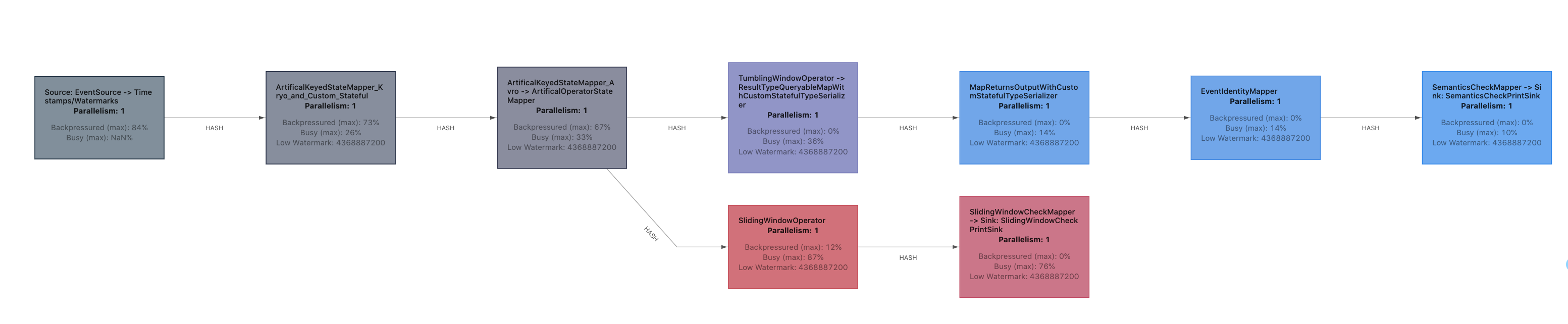
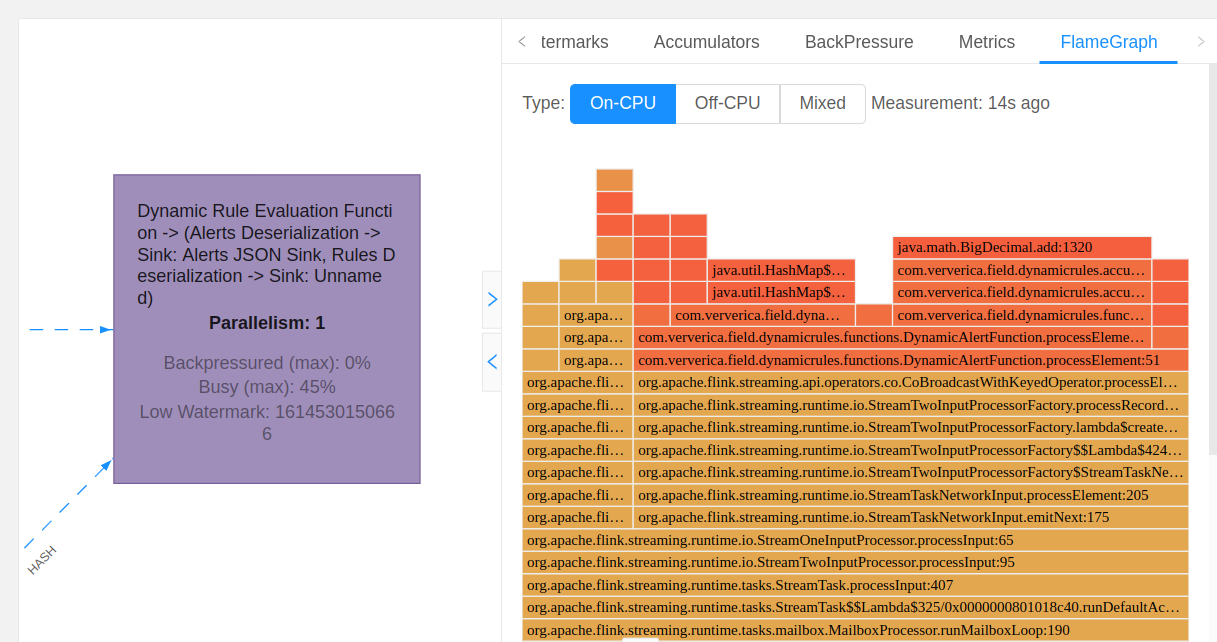
此外,Flink 1.13 还为 Web UI 添加了 CPU 火焰图,该火焰图是通过对线程堆栈痕迹的反复采样来构建的。每个方法的调用都用一个条形表示,条形的长度与它在样本中出现的次数成正比。启用后,图表会显示在所选操作者的新 UI 组件中。
使用保存点切换状态后端
用户现在可以在从保存点恢复时改变 Flink 应用程序的状态后端。这意味着应用程序的状态不再被锁定在应用程序最初启动时使用的状态后端。这使得初始启动 HashMap 状态后端(JVM Heap 中的纯内存)成为可能,一旦状态增长过大,就可以切换到 RocksDB 状态后端。Flink 现在有一个标准的保存点格式,所有的状态后端在为一个保存点创建数据快照时都会使用这个格式。
用户指定 Kubernetes 部署的 Pod 模板
原生的 Kubernetes 部署(Flink 主动与 K8s 对话以启动和停止 pod)现在支持自定义 pod 模板。有了这些模板,用户可以以 Kubernetes 的方式设置和配置 JobManagers 和 TaskManagers pods ,其灵活性超出了 Flink 的 Kubernetes 集成中直接内置的配置选项。
机器学习库移至单独的存储库
为了加速 Flink 的机器学习工作(流式、批处理和统一的机器学习)的发展,这项工作已经转移到 Flink 项目下的新仓库 flink-ml。
更多详细内容,请查看更新公告。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- 简述大数据实时处理框架
- gobox中的consumer处理框架
- 流式处理框架storm浅析(上篇)
- Bootstrap开发框架界面的调整处理
- iOS换肤功能的简单处理框架
- 一个不错的音视频快速处理框架
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。



