内容简介:开源地址: github: https://github.com/sagframe/sagacity-sqltoy gitee: https://gitee.com/sagacity/sagacity-sqltoy idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins...
开源地址:
- github: https://github.com/sagframe/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
更新内容
1、支持greenplum olap数据库
2、并行查询支持自行定义并行数量和最大等待时长
//例如:ParallelConfig.create().maxThreads(20)
public <T> List<QueryResult<T>> parallQuery(List<ParallQuery> parallQueryList, Map<String, Object> paramsMap,
ParallelConfig parallelConfig);
- 简要介绍sqltoy的几个特点
sqltoy提供了最简洁的动态 sql 编写
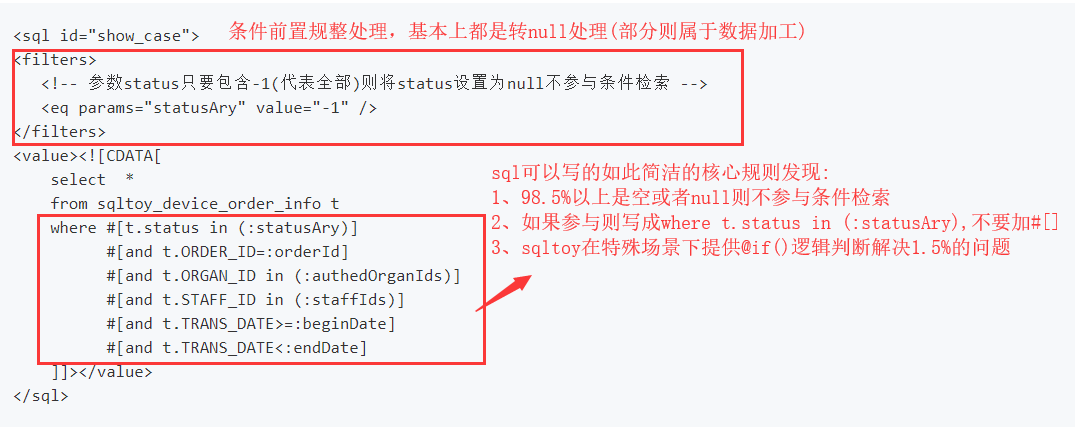
我们对比一下mybatis的实现(从可阅读、可维护等视角看):

- 缓存翻译,利用缓存减少关联查询,简化sql同时大幅提升效率
- 极致分页优化
- 并行查询
// 使用并行查询同时执行2个sql,条件参数是2个查询的合集
String[] paramNames = new String[] { "userId", "defaultRoles", "deployId", "authObjType" };
Object[] paramValues = new Object[] { userId, defaultRoles, DEPLOY_ID,GROUP };
List<QueryResult<TreeModel>> list = super.parallQuery(
Arrays.asList(ParallQuery.create().sql("webframe_searchAllModuleMenus").resultType(TreeModel.class),
ParallQuery.create().sql("webframe_searchAllUserReports").resultType(TreeModel.class)),
paramNames, paramValues);
- 数据旋转
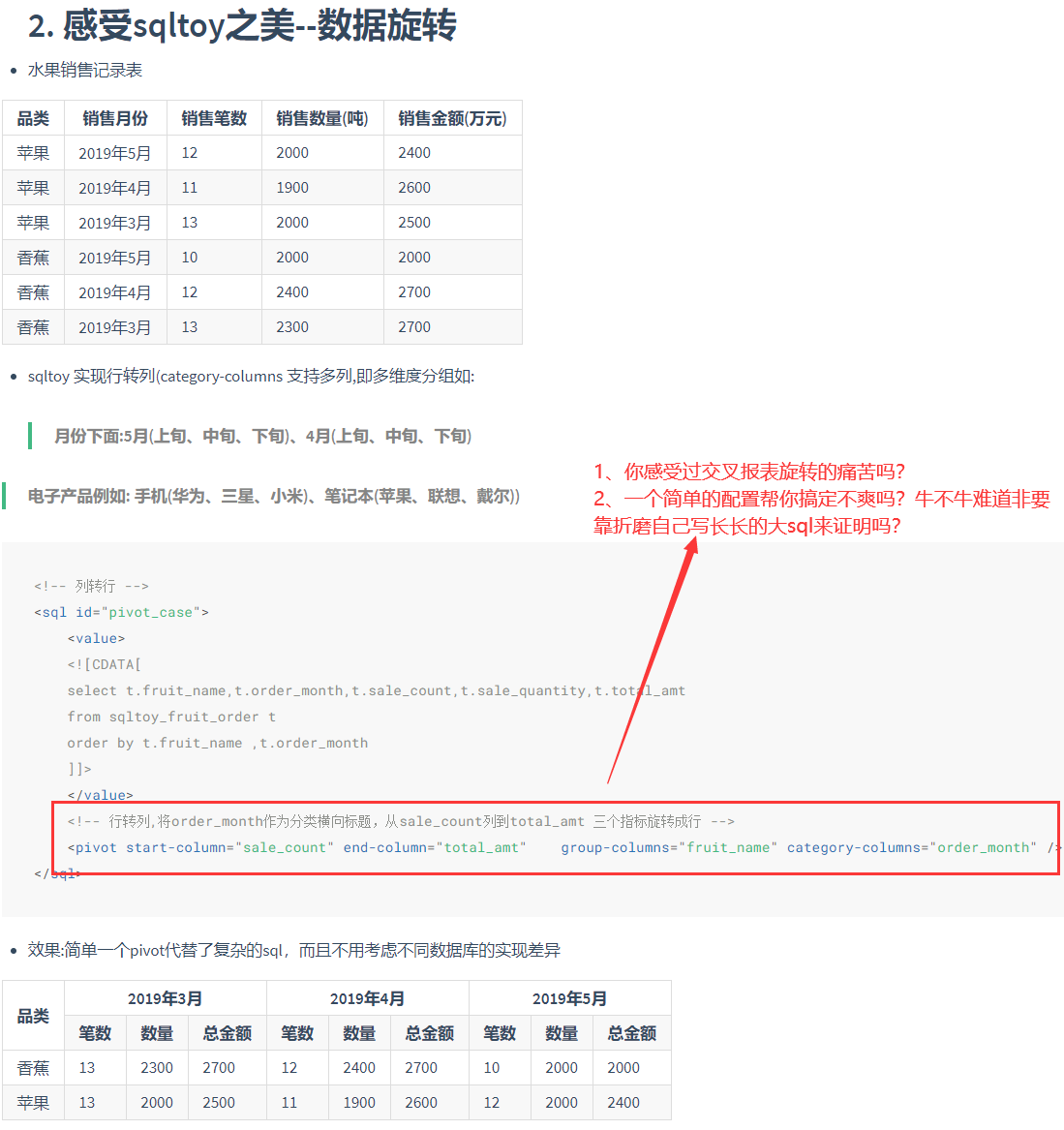
- 无限极分组统计(含汇总求平均),算法配置简单又跨数据库!
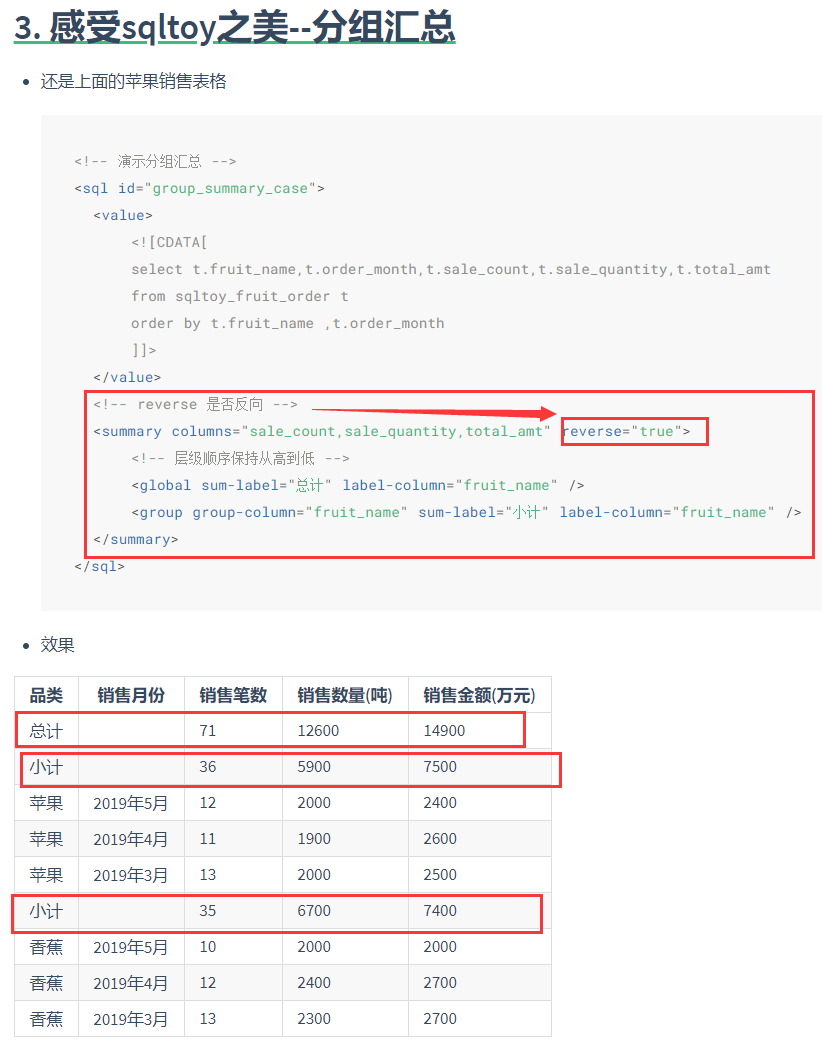
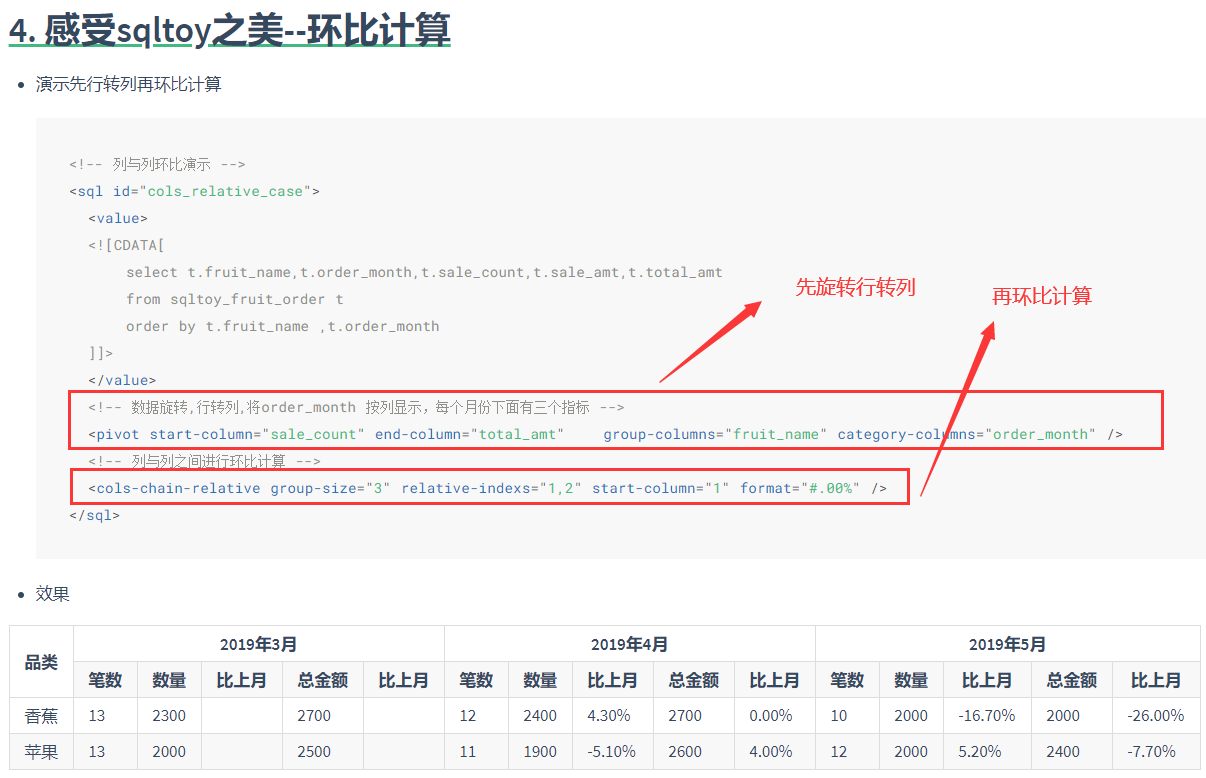
- 同比环比
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
- 字符串的长度,是字符数量,还是字节数量?
- Java并发 -- 线程数量
- kafka增加topic的备份数量
- 来,控制一下 Goroutine 的并发数量
- 控制 Goroutine 的并发数量的方式
- 线程池最佳线程数量到底要如何配置?
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

全景探秘游戏设计艺术
Jesse Schell / 吕阳、蒋韬、唐文 / 电子工业出版社 / 2010-6 / 69.00元
撬开你脑子里的那些困惑,让你重新认识游戏设计的真谛,人人都可以成为成功的游戏设计者!从更多的角度去审视你的游戏,从不完美的想法中跳脱出来,从枯燥的游戏设计理论中发现理论也可以这样好玩。本书主要内容包括:游戏的体验、构成游戏的元素、元素支撑的主题、游戏的改进、游戏机制、游戏中的角色、游戏设计团队、如何开发好的游戏、如何推销游戏、设计者的责任等。 本书适合任何游戏设计平台的游戏设计从业人员或即将......一起来看看 《全景探秘游戏设计艺术》 这本书的介绍吧!


