内容简介:Apache Flink 最新稳定版 1.12.0 已发布。Apache Flink 是一个流处理框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算...
Apache Flink 最新稳定版 1.12.0 已发布。Apache Flink 是一个流处理框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
根据发布公告的介绍,新版本显着提升了可用性。此外,新增的功能简化(并统一了)整个 API 堆栈的 Flink 处理。亮点如下:
DataStream API 中的批处理执行模式 (Batch Execution Mode)
在 DataStream API 中增加对高效批处理执行的支持。这是实现批处理和流处理真正统一运行时的下一个重要里程碑。
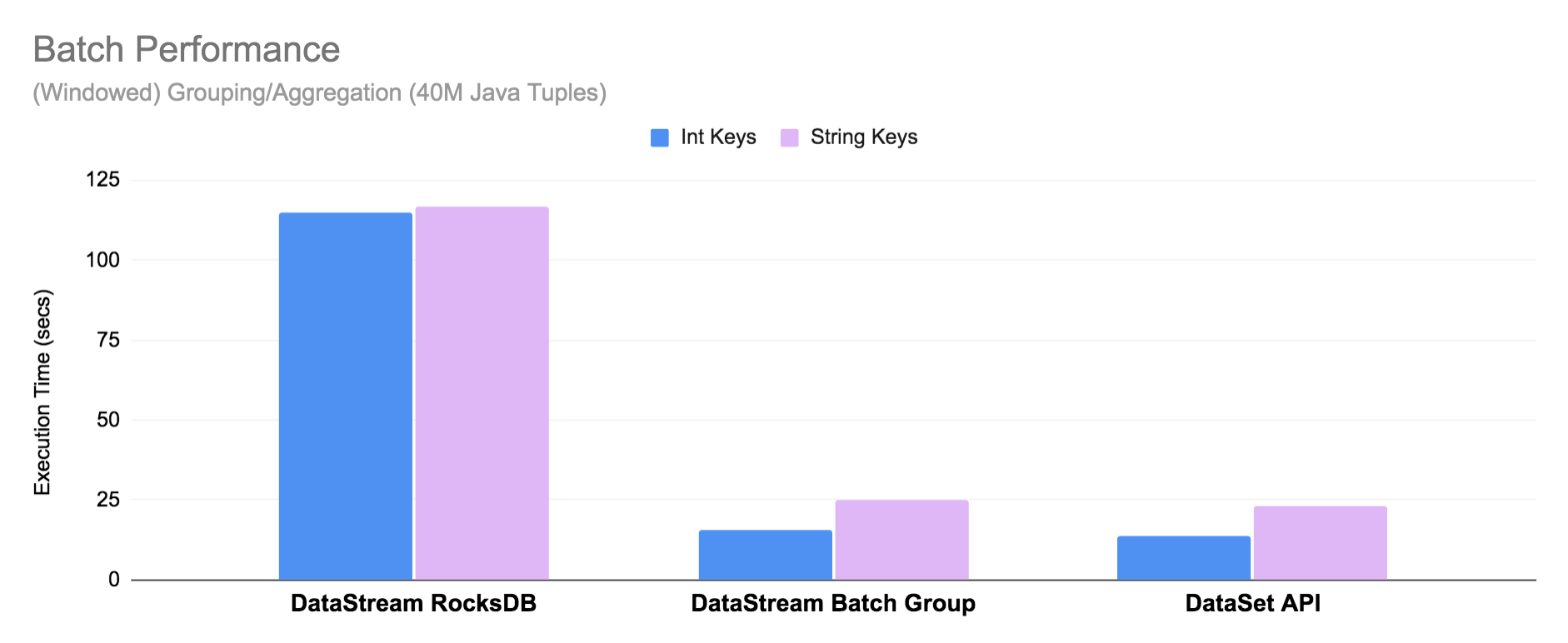
有限流上的批处理 (Batch for Bounded Streams)
现在已支持使用 DataStream API 来处理有限流(例如文件),然而运行时并不“知道”作业已受限制。为了优化在有限输入情况下的运行时性能,新BATCH执行模式对于聚合操作全部在内存中进行,并使用改进过的调度策略(查看 Pipelined Region Scheduling)。因此,DataStream API 中BATCH模式执行已经非常接近 Flink 1.12 中 DataSet API 的性能。
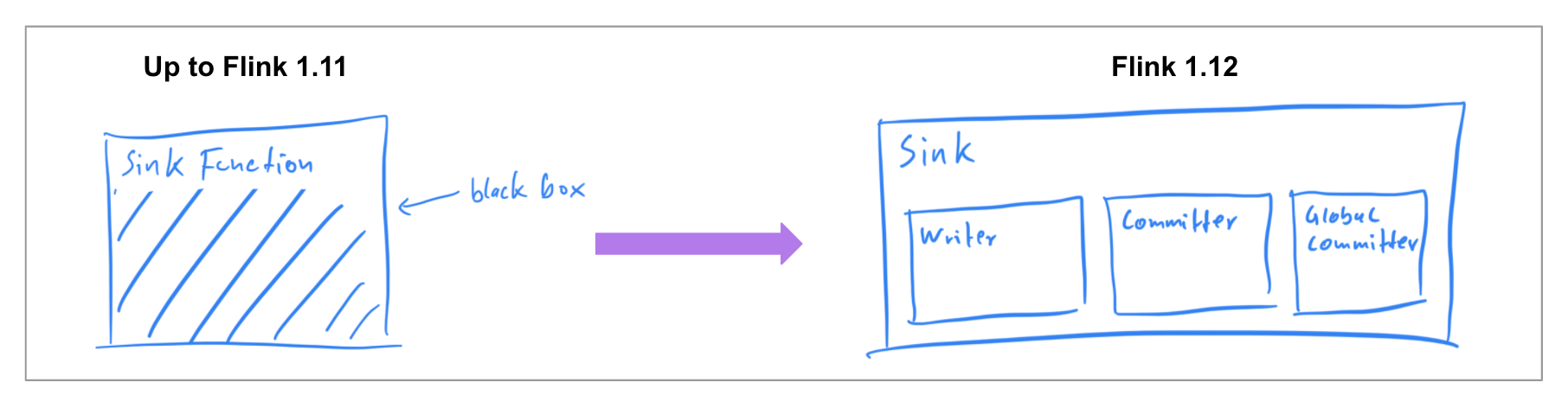
新的 Data Sink API (Beta)
在以前的版本中,已经确保数据源中的连接器可以同时在两种执行模式下工作,因此在 Flink 1.12 中,社区专注于实现统一的 Data Sink API (FLIP-143)。新的抽象引入了一个 write/commit 协议和一个更加模块化的接口,接口中各个组件会透明地暴露给框架。
Sink 实现者需要定义 what 和 how:SinkWriter 用于写数据,并输出需要 commit 的内容(例如 committables);Committer 和 GlobalCommitter 封装了如何处理 committables。框架会负责 when 和 where:即在什么时间,以及在哪些机器或进程中 commit。
Kubernetes 高可用性 (HA) 服务
实现基于 Kubernetes 的高可用性 (HA) 方案,在生产环境中可作为 ZooKeeper 的替代方案,以实现高可用性的生产设置。当然,这并不意味 ZooKeeper 会被删除,这只是为 Kubernetes 上的 Flink 用户提供另一种选择。
升级 Kafka Connector
Kafka SQL 连接器已扩展为可以在 upsert 模式下工作,并且能够处理 SQL DDL 中的 connector metadata。现在,Temporal table joins 也可以用 SQL 完全表示,而不再依赖于 Table API。
PyFlink:Python DataStream API
PyFlink 添加了对于 DataStream API 的支持,并将 PyFlink 扩展到了更复杂的场景,比如需要对状态或者定时器 timer 进行细粒度控制的场景。除此之外,现在原生支持将 PyFlink 作业部署到 Kubernetes 上。
以上所述就是小编给大家介绍的《Apache Flink 1.12.0 发布,初步实现批处理和流处理统一运行》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 码农网 的支持!
猜你喜欢:
- 动画骨骼节点批处理
- Spark 持续流处理和微批处理的对比
- Spring Batch批处理简介
- Jet 4.5 发布,分布式批处理和流处理引擎
- 注册中心 Eureka 源码解析 —— 任务批处理
- java – JMS和Spring批处理
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Algorithms
Robert Sedgewick、Kevin Wayne / Addison-Wesley Professional / 2011-3-19 / USD 89.99
Essential Information about Algorithms and Data Structures A Classic Reference The latest version of Sedgewick,s best-selling series, reflecting an indispensable body of knowledge developed over the ......一起来看看 《Algorithms》 这本书的介绍吧!


