内容简介:开源地址: github: https://github.com/sagframe/sagacity-sqltoy gitee: https://gitee.com/sagacity/sagacity-sqltoy idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins...
开源地址:
- github: https://github.com/sagframe/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
更新内容
1、 支持QueryExecutor、EntityQuery中使用分库分表策略配置 (原本只支持xml中定义)
//分库
dbSharding(String strategy, String... paramNames)
//分表
tableSharding(String strategy, String[] tables, String... paramNames)
sqltoy的十四个关键特点:
1、最简最直观的 sql 编写方式(不仅仅是查询语句),采用条件参数前置处理规整法,让sql语句部分跟客户端保持高度一致
2、sql中支持注释(规避了对hint特性的影响,知道hint吗?搜oracle hint),和动态更新加载,便于开发和后期维护整个过程的管理
3、支持缓存翻译和反向缓存条件检索(通过缓存将名称匹配成精确的key),实现sql简化和性能大幅提升
4、支持快速分页和分页优化功能,实现分页最高级别的优化,同时还考虑到了cte多个with as情况下的优化支持
5、支持并行查询
6、根本杜绝sql注入问题,以后不需要讨论这个话题
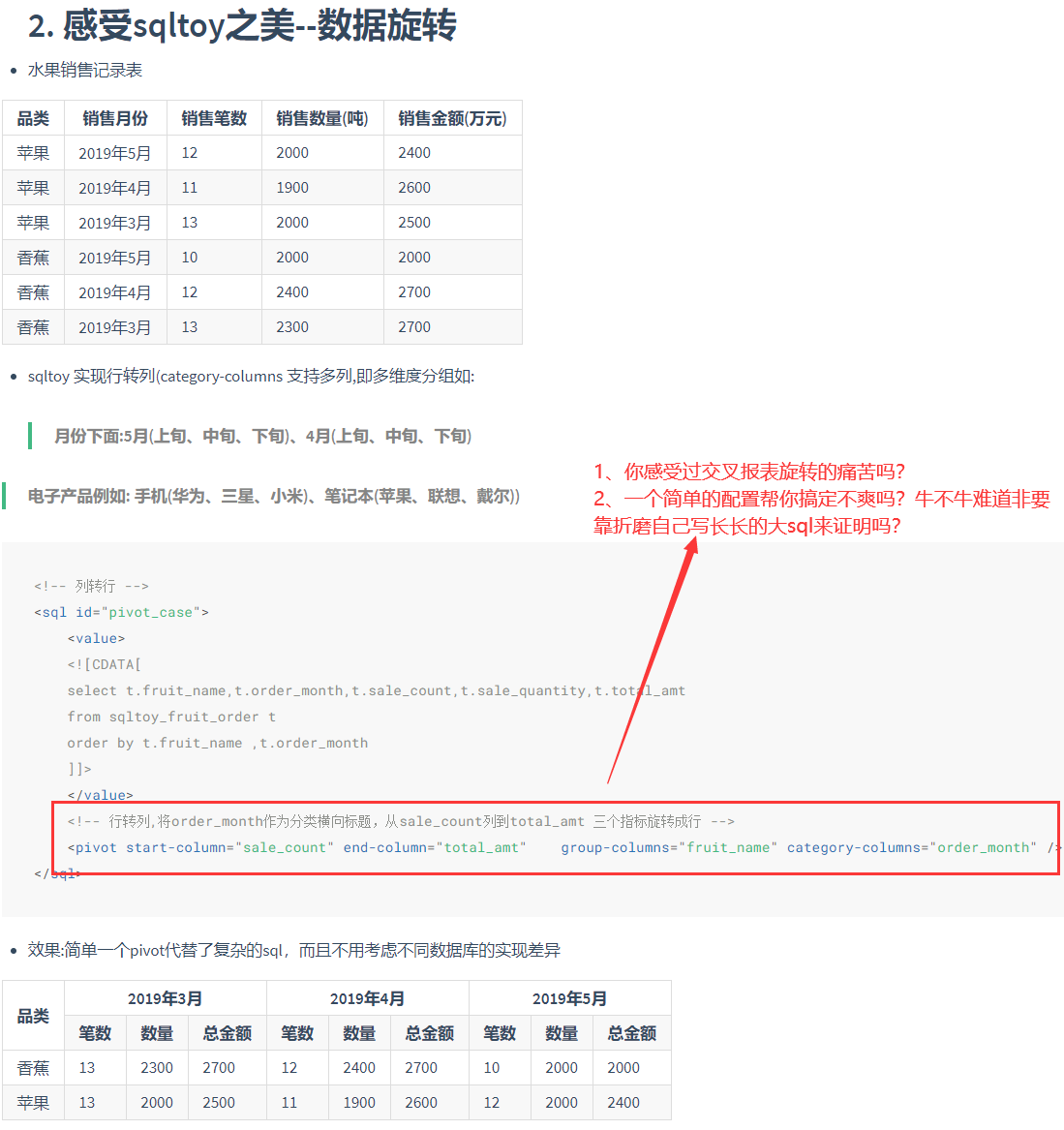
7、支持行列转换、分组汇总求平均、同比环比计算,在于用算法解决复杂sql,同时也解决了sql跨数据库问题
8、支持保留字自动适配
9、支持跨数据库函数自适配,从而非常有利于一套代码适应多种数据库便于产品化,比如oracle的nvl,当sql在 mysql 环境执行时自动替换为ifnull
10、支持分库分表
11、提供了取top、取random记录、树形表结构构造和递归查询支持、updateFetch单次交互完成修改和查询等实用的功能
12、sqltoy的update、save、saveAll、load 等crud操作规避了hibernate jpa的缺陷,可以深入对比update/updateAll、saveOrUpdate/saveOrUpdateAll内部差异
13、提供了极为人性化的条件处理:排它性条件、日期条件加减和提取月末月初处理等
14、提供了查询结果日期、数字格式化、安全脱敏处理,让复杂的事情变得简单,大幅简化sql或结果的二次处理工作
- sqltoy的crud:了解hibernate jpa吧?原理一致,但在update等一些功能上更加细致
StaffInfoVO staffInfo = new StaffInfoVO();
staffInfo.setStaffId("S2007").setStaffName("测试员工9");
//保存
sqlToyLazyDao.save(staffInfo);
//保持或修改
sqlToyLazyDao.saveOrUpdate(staffInfo);
//针对照片属性强制更新
sqlToyLazyDao.update(staffInfo, "photo");
//加载
sqlToyLazyDao.load(new StaffInfoVO("S2007"))
//删除
sqlToyLazyDao.delete(new StaffInfoVO("S2007"))
- 简要介绍一下sqltoy的几个特点
sqltoy提供了最简洁的动态sql编写
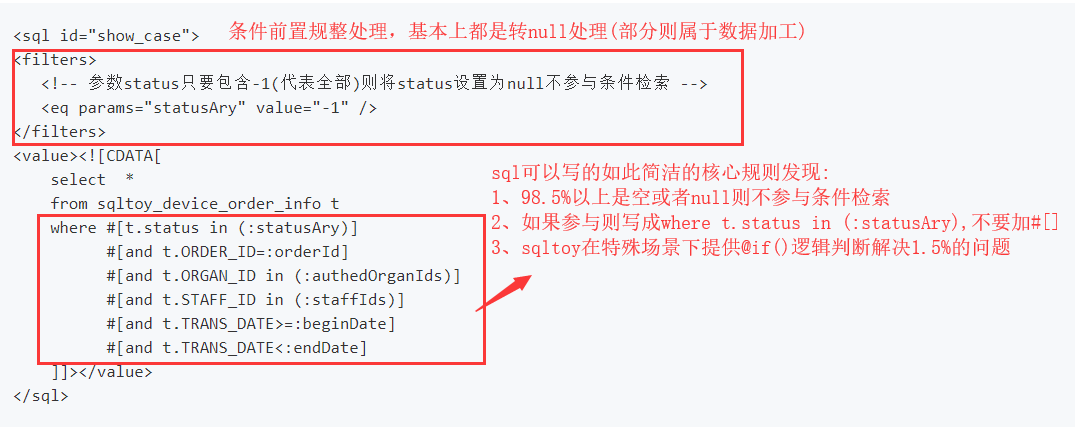
我们对比一下mybatis的实现(从可阅读、可维护等视角看):

- 缓存翻译,利用缓存减少关联查询,简化sql同时大幅提升效率
- 极致分页优化
- 并行查询
// 使用并行查询同时执行2个sql,条件参数是2个查询的合集
String[] paramNames = new String[] { "userId", "defaultRoles", "deployId", "authObjType" };
Object[] paramValues = new Object[] { userId, defaultRoles, DEPLOY_ID,GROUP };
List<QueryResult<TreeModel>> list = super.parallQuery(
Arrays.asList(ParallQuery.create().sql("webframe_searchAllModuleMenus").resultType(TreeModel.class),
ParallQuery.create().sql("webframe_searchAllUserReports").resultType(TreeModel.class)),
paramNames, paramValues);
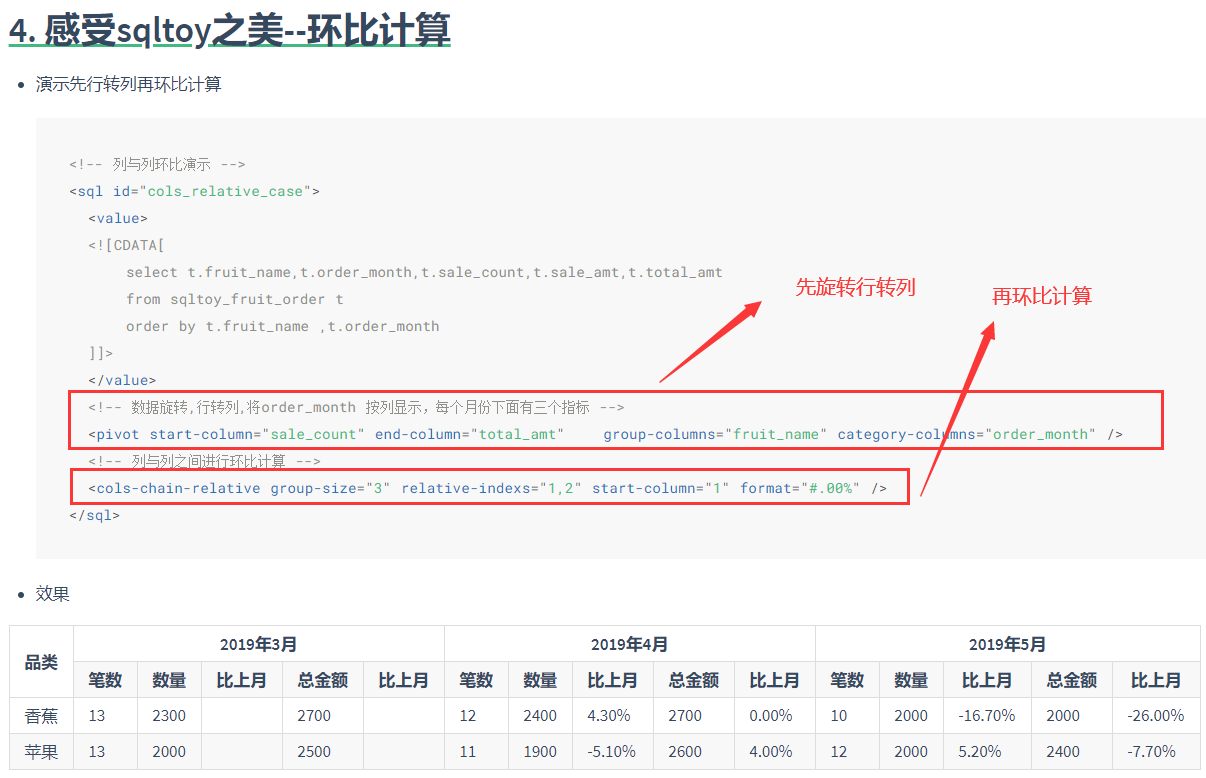
- 数据旋转
- 无限极分组统计(含汇总求平均),算法配置简单又跨数据库!
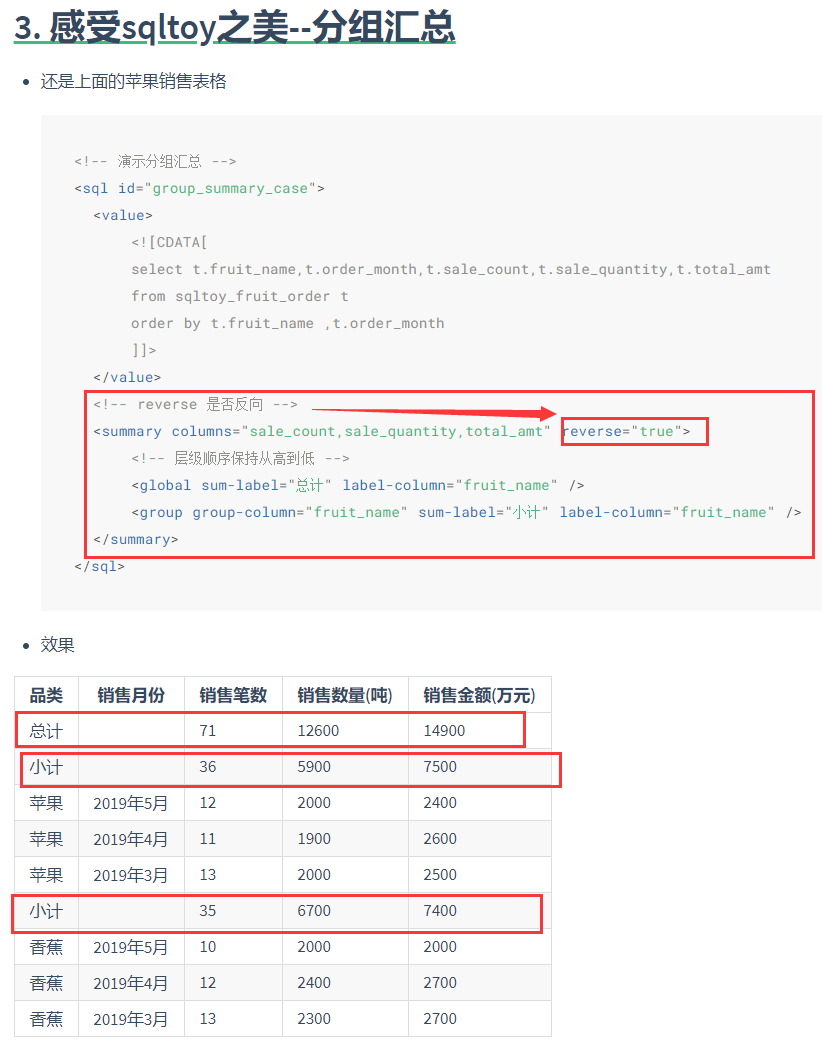
- 同比环比
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- 数据库考点:为什么要分库分表?用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?如何对数据库如何进行拆分?
- MySQL分库分表
- Mycat 和分库分表
- 浅谈分库分表那些事儿
- 分库分表后的索引问题
- 一次难得的分库分表实践
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Python语言程序设计
[美]梁勇(Lang Y. D.) / 李娜 / 机械工业出版社 / 2015-4 / 79.00元
本书采用“问题驱动”、“基础先行”和“实例和实践相结合”的方式,讲述如何使用Python语言进行程序设计。本书首先介绍Python程序设计的基本概念,接着介绍面向对象程序设计方法,最后介绍算法与数据结构方面的内容。为了帮助学生更好地掌握相关知识,本书每章都包括以下模块:学习目标,引言,关键点,检查点,问题,本章总结,测试题,编程题,注意、提示和警告。 本书可以作为高等院校计算机及相关专业Py......一起来看看 《Python语言程序设计》 这本书的介绍吧!

JS 压缩/解压工具
在线压缩/解压 JS 代码

XML、JSON 在线转换
在线XML、JSON转换工具