内容简介:开源地址: github: https://github.com/sagframe/sagacity-sqltoy gitee: https://gitee.com/sagacity/sagacity-sqltoy idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins...
开源地址:
- github: https://github.com/sagframe/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
更新内容
1、完善SqlToyLazyDao,增加finByQuery支持锁查询
2、其他一些代码整理和注释强化
分析为什么sqltoy-orm是最值得拥有的!
您的痛点和诉求分析,我们将大多数人遇到的问题分成3个阶段:
- 初级阶段诉求(单库,crud+一些较复杂查询)
- 希望拥有jpa式的对象操作的简洁舒畅,如:save(entity)\update\saveOrUpdate\saveAll\updateAll,loadById()等
- 希望简单的查询可以是对象链式操作模式
- 希望复杂的查询可以直接写 sql 便于sql优化,同时希望sql文件更新可以热更新
- 不希望有sql注入问题
- 希望可以方便分页
- 中级阶段诉求(开始遇到一些复杂场景开始思辨,crud不再是重点,查询问题开始凸显)
- 提供诸如唯一性验证、取top记录、取随机记录现成的方法
- 遇到一些分布式、高并发场景,考虑主键生成策略诉求,比如传统jpa的update操作无法规避null覆盖则需要先加载后更新(高并发就易导致将别人已经更新后的内容又覆盖了)
- 遇到产品要适用多种数据库的诉求,希望一个sql可以跑在myql、oracle、mssql、postgres等,如树结构递归查询、group_concat等函数适配
- 随着业务的成熟,企业的管理开始注重数据,对查询和统计要求变高(但查询往往需求会多变),所以较长的动态条件sql比重越来越大。
- 遇到了一些复杂统计问题,比如数据旋转、同比环比,纯sql写起来过于复杂,且换数据库又不通用
- 高级阶段诉求(ETL(跑批+流实时处理)+极致查询,这个阶段查询问题极为凸显,处理不好性能用户体验将极为糟糕)
- 因为数据规模的扩大,老套的表分区也难以支撑,需要分表、分库了
- 因为大数据和高并发,对查询性能提出了极致性要求
- 传统数据库无法适应大规模数据和业务多样性带来的要求,需要进行领域细分,引入 mongodb 、elastic、clickhouse等组合使用
- sqltoy-orm就是上述过程的演绎
- sqltoy起初是hibernate jpa的补充,用于增强查询,后来因为不希望项目中引入太多技术,sqltoy实现了hibernate jpa的功能,同时将其不足之处进行了完善,正式称之为ORM框架!
- sqltoy是个人带团队给各个金融企业做项目过程中成长起来的,不同企业数据库不一样,而且金融企业数据规模基本上都是百万千万级,所以要求基础模块可以适用于不同数据库。
- sqltoy是经历个人负责拉卡拉支付集团数据团队时,单交易表日均1300万(2017年底),年均30亿规模的洗礼的,在大规模ETL(hive+spark跑批和流实时)的基础上结合oracle一体机、索引优化、表分区、内存表、分表分库、缓存翻译、极致分页等各种策略都难以支撑,通过融合mongo、elasticsearch、clickhouse进行组合专题化应用得以很好的解决。
- 从2018年sqltoy经历了目前公司erp复杂场景的洗礼,走向了成熟。
- 从2020年4月sqltoy对外开源推广,得到了大量的反馈,结合积极的响应和完善,sqltoy基本上完成了各种边缘场景的覆盖!
- 简要介绍一下sqltoy的几个特点
sqltoy提供了最简洁的动态sql编写
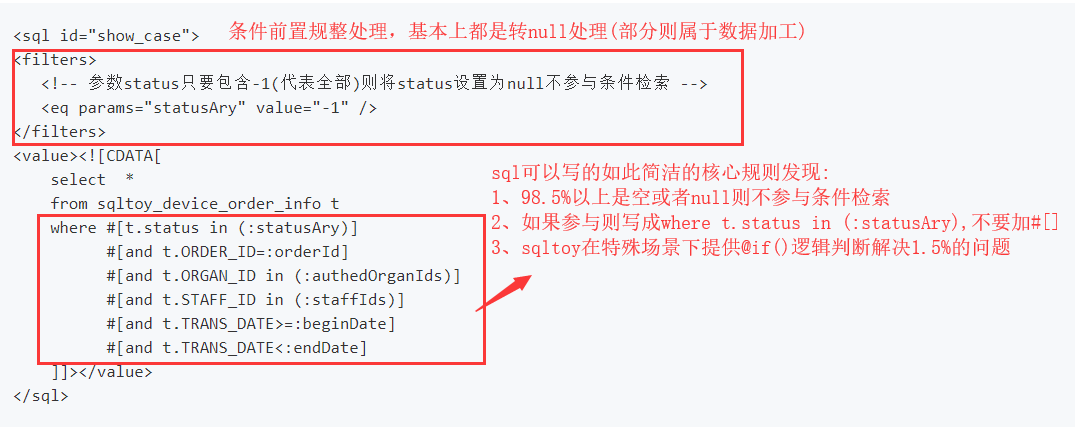
我们对比一下mybatis的实现(从可阅读、可维护等视角看):

- 缓存翻译,利用缓存减少关联查询,简化sql同时大幅提升效率
- 极致分页优化
- 并行查询:同时执行多个查询,提升效率
// 使用并行查询同时执行2个sql,条件参数是2个查询的合集
String[] paramNames = new String[] { "userId", "defaultRoles", "deployId", "authObjType" };
Object[] paramValues = new Object[] { userId, defaultRoles, DEPLOY_ID,GROUP };
List<QueryResult<TreeModel>> list = super.parallQuery(
Arrays.asList(ParallQuery.create().sql("webframe_searchAllModuleMenus").resultType(TreeModel.class),
ParallQuery.create().sql("webframe_searchAllUserReports").resultType(TreeModel.class)),
paramNames, paramValues);
- 数据旋转
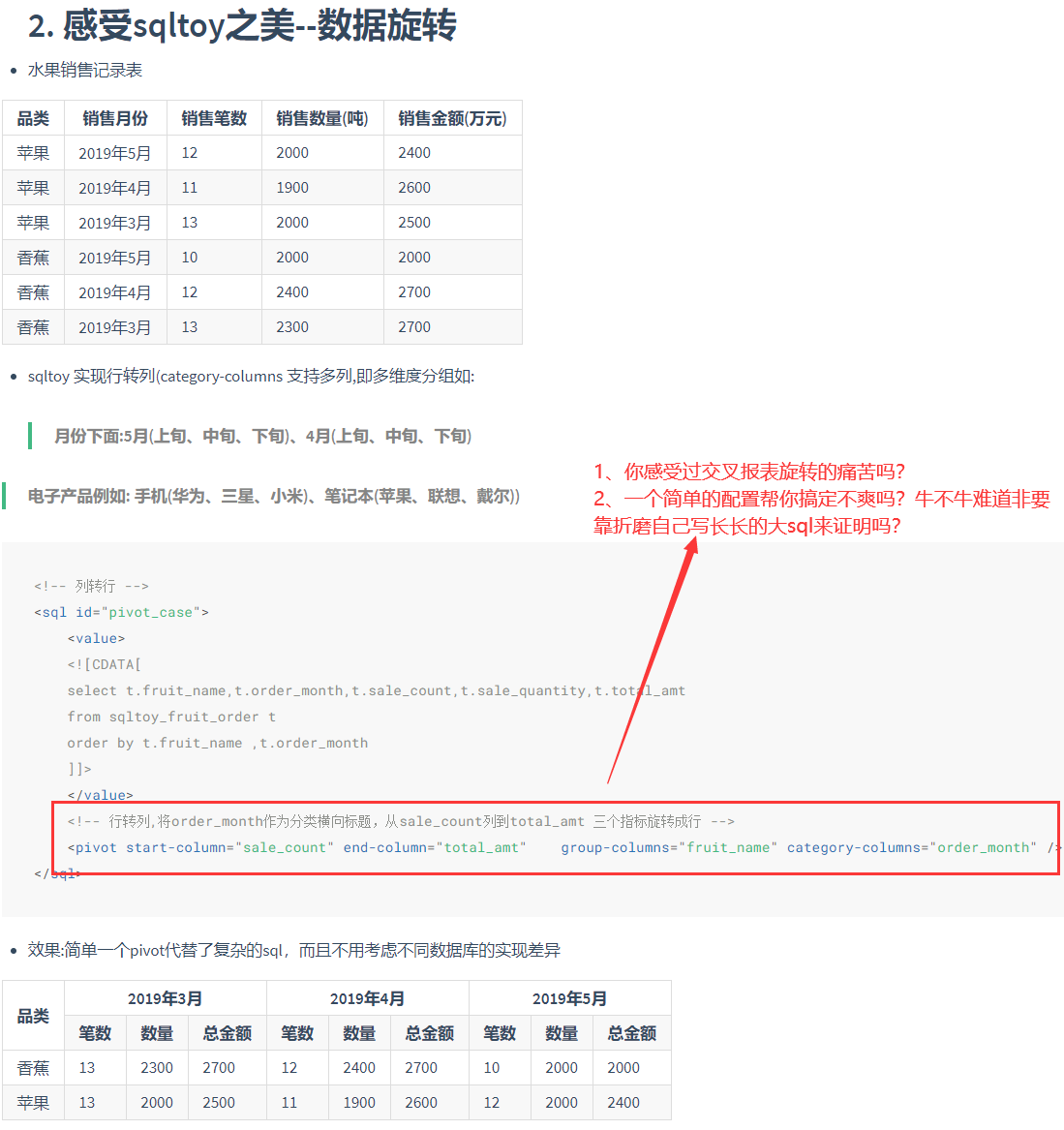
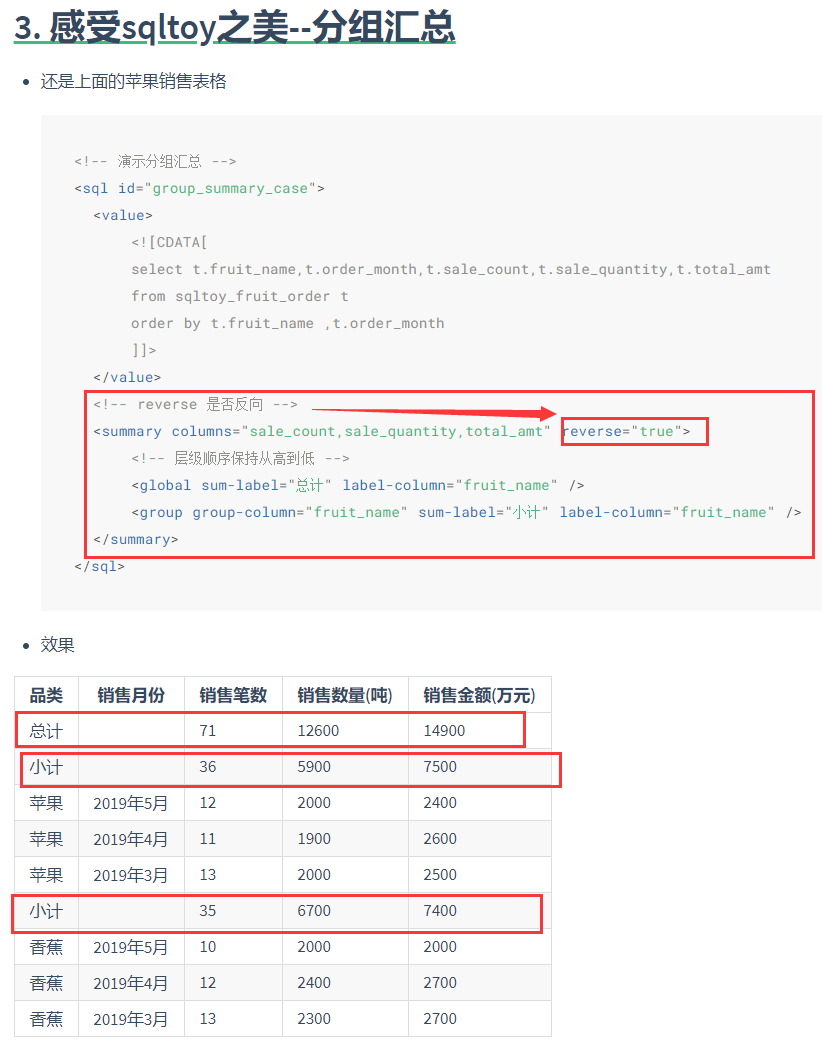
- 无限极分组统计(含汇总求平均),算法配置简单又跨数据库!
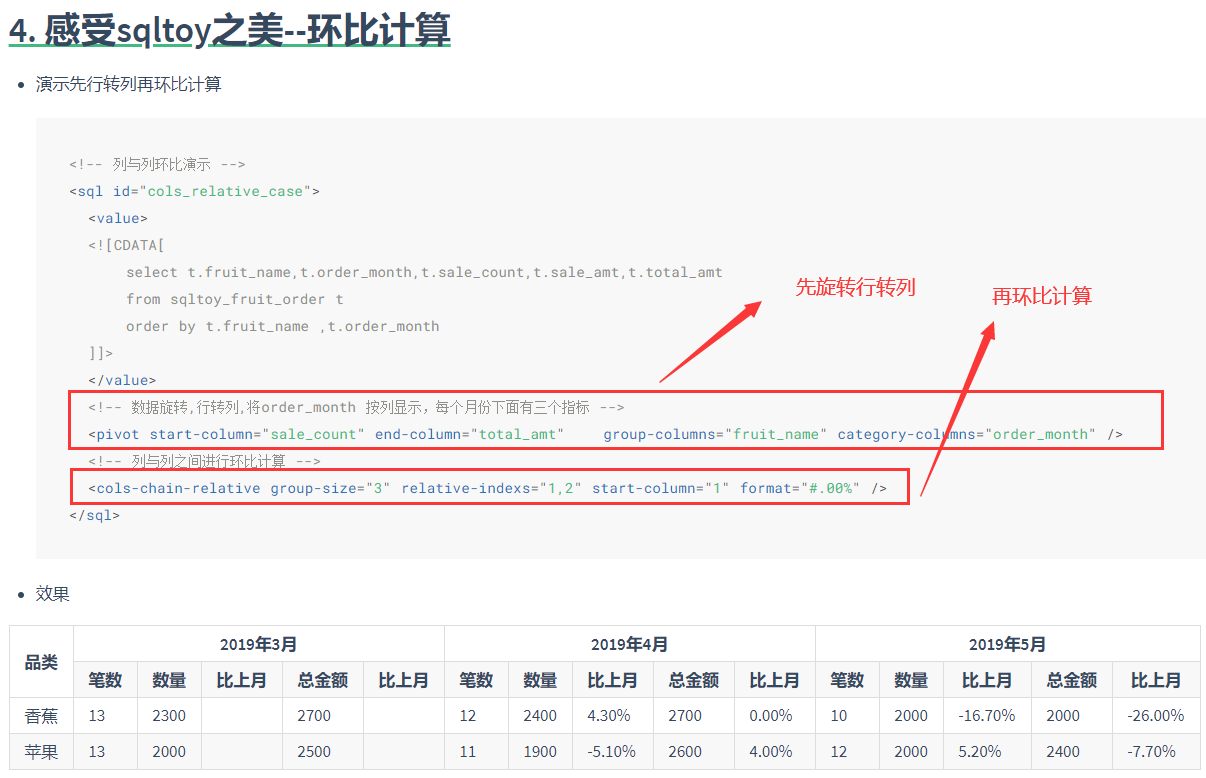
- 同比环比
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- 直面企业安全痛点,FIT 2019 企业安全俱乐部全议题回顾(附PPT下载)
- 直面算法霸权:我们该如何应对
- 机器学习直面“房间里的大象”
- 直面底层:“吹上天”的协程,带你深入源码分析
- 抗DDoS技术征战网络江湖,上海云盾直面黑客攻击本宗
- 通过“拖拽”搭建数据分析模型,「时代大数据」让经营管理者“直面数据”
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

MATLAB实用教程
穆尔(Holly Moore) / 高会生 刘童娜 李聪聪 / 电子工业出版社 / 2010-1-1 / 59.00元
MATLAB实用教程(第二版),ISBN:9787121101793,作者:(美)穆尔 著,高会生,刘童娜,李聪聪 译一起来看看 《MATLAB实用教程》 这本书的介绍吧!


