内容简介:开源地址: github: https://github.com/chenrenfei/sagacity-sqltoy gitee: https://gitee.com/sagacity/sagacity-sqltoy idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugi...
开源地址:
- github: https://github.com/chenrenfei/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
更新内容(感谢众多网友的反馈,使得一些边缘场景得以巩固)
1、增强group_concat的算法实现link功能,支持多列场景
<!-- 演示link操作,如果分页请用@fast() 取10条后再关联,最终会返回10条记录 -->
<sql id="qstart_link_case">
<value>
<![CDATA[
select t.ORGAN_ID ,t.ORGAN_ID ORGAN_NAME, t.STAFF_NAME , t.SEX_TYPE,t.SEX_TYPE sexTypeName
from sqltoy_staff_info t
order by t.ORGAN_ID
]]>
</value>
<!-- 多个列合并,可以先翻译后合并 -->
<link id-column="ORGAN_ID" columns="STAFF_NAME,sexTypeName" sign="," />
<translate cache="dictKeyName" columns="sexTypeName" cache-type="SEX_TYPE"/>
<translate cache="organIdName" columns="ORGAN_NAME"/>
</sql>
2、优化postgresql9.4 版本的saveOrUpdate功能(9.4 不支持insert table AS T1别名模式,剔除别名),推荐9.5+版本
3、增强loadBySql、load(entity)对象类型处理,避免new VO(){{setId("");}} 双大括号极端特殊场景下定义对象导致类型获取错误。
4、增强 sql 中参数:param判断逻辑,适配postgresql带有json形式的查询场景::jsonb 这种对条件参数的干扰
5、translateManager 简化了缓存更新、清除接口(之前是要再调一层),便于用户扩展来完成缓存的近实时更新
6、quickvo增强支持JSONB等类型
快速了解 sqltoy-orm:
- sqltoy是全新一代的ORM框架,兼顾jpa对象式操作的优势,同时极大增强了查询功能,辅以科学的sql编写模式、巧妙的缓存翻译集成、极致的分页优化以及针对大规模数据下的分库分表、超复杂场景下的 mongodb 、elastic、clickhouse组合应用!
- sqltoy给你带来了多种主键策略,除常规的UUID、sequence、identity外,还包含雪花算法和基于 redis 产生有规则的业务主键等。
- sqltoy还提供了针对统计分析的:数据旋转、无限级分组计算、同比环比等来减少开发者写复杂sql。
- sqltoy在很多方面提供了极为实用的方法,如:树形表处理、isUnique、findTop、getRandomResult、updateFetch等等
- sqltoy不走jooq全对象式、mybatis全sql式这种不是天就是地的极端路子,紧贴项目实战发展起来的框架,让各自技术以合理的方式应用于合理的地方!
简要举例介绍(因篇幅问题部分举例):
- JPA式的CRUD,但规避了其不足,提供了默认的SqlToyCRUDService(简单的则无需写service方法) 和 SqlToyLazyDao(开发无需自己写Dao,只需要写Service业务逻辑),可以了解类似于update、updateAll、saveOrUpdate等内在逻辑,减少了数据库交互,考虑了高并发和业务对象变更的特征!
@Autowired
private SqlToyCRUDService sqlToyCRUDService;
//基于对象保存
sqlToyCRUDService.save(staffInfo);
//基于对象更新(字段值为null的不会参与变更)
sqlToyCRUDService.update(staffInfo);
//深度变更,全部字段都参与变更
sqlToyCRUDService.updateDeeply(staffInfo);
//基于对象更新(制定强制修改的字段)
sqlToyCRUDService.update(staffInfo,new String[]{"staffName","onDuty"});
//基于对象更新
sqlToyCRUDService.saveOrUpdate(staffInfo);
//加载对象
sqlToyCRUDService.load(new StaffInfoVO("S190715009"));
//加锁获取对象
sqlToyCRUDService.load(new StaffInfoVO("S190715009"),LockMode.UPGRADE);
//判断对象是否唯一
sqlToyCRUDService.isUnique(staffInfo, "staffCode");
//delete\deleteAll\updateAll\loadAll 等等不一一写完
- 单表等简单的查询和变更操作,提供了链式操作
//单表对象查询,直接传参模式
List<StaffInfoVO> staffVOs = sqlToyLazyDao.findEntity(StaffInfoVO.class,
EntityQuery.create().where("#[staffName like ?] #[ and status=?]").values("陈", 1).lock(LockMode.UPGRADE)
.orderBy("staffName").orderByDesc("createTime"));
//单表查询,对象传参模式
List<StaffInfoVO> staffVOs = sqlToyLazyDao.findEntity(StaffInfoVO.class,
EntityQuery.create().where("#[staffName like :staffName] #[ and status=:status]")
.values(new StaffInfoVO().setStatus(1).setEmail("test3@aliyun.com")));
//代码中链式查询并删除
Long deleteCount = sqlToyLazyDao.deleteByQuery(StaffInfoVO.class,
EntityQuery.create().where("status=:status").values(new StaffInfoVO().setStatus(1)));
//链式变更
Long updateCount = sqlToyLazyDao.updateByQuery(StaffInfoVO.class,
EntityUpdate.create().set("staffName", "张三").where("staffName like ? and status=?").values("陈", 1));
- 更强大的查询,sqltoy强调复杂查询建议放置于xml中跟代码分离(当然等jdk15文本块来了你写在 java 也可以)
//sqltoy统一的规则就是直接传递sql语句或者对应的sqlId,并不是说sql只能写在xml中(推荐但不绝对)
findBySql(final String sqlOrSqlId, final String[] paramsNamed, final Object[] paramsValue,
final Class<T> voClass)
//嫌弃上面的格式化传参也可以使用这样链式查询
sqlToyLazyDao.findByQuery(new QueryExecutor("sqltoy_order_search").names("orderId", "authedOrganIds")
.values(null, authedOrgans).resultType(DeviceOrderInfoVO.class));
- sqltoy提供了最简洁的动态sql编写
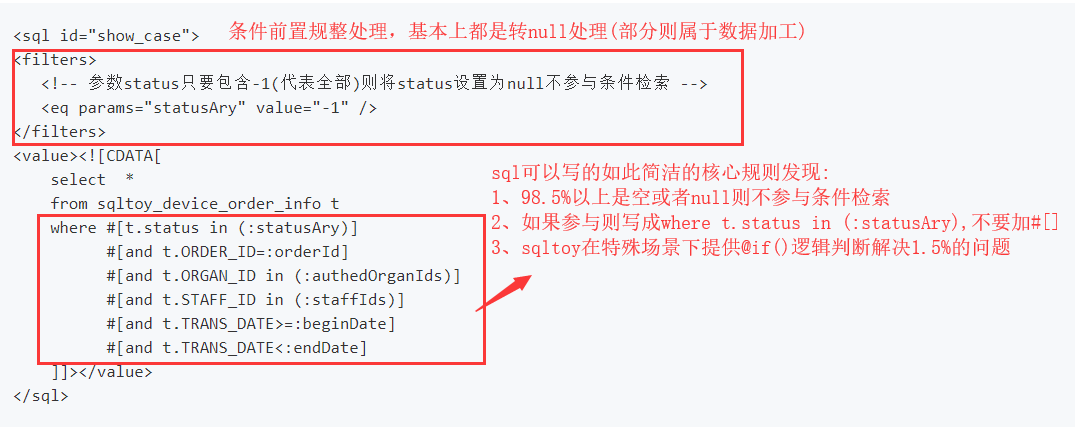
我们对比一下mybatis的实现(很简单的sql写的如此让人不愿意写!):

- 缓存翻译,利用缓存减少关联查询,简化sql同时大幅提升效率
- 极致分页优化
- 并行查询
// 使用并行查询同时执行2个sql,条件参数是2个查询的合集
String[] paramNames = new String[] { "userId", "defaultRoles", "deployId", "authObjType" };
Object[] paramValues = new Object[] { userId, defaultRoles, DEPLOY_ID,GROUP };
List<QueryResult<TreeModel>> list = super.parallQuery(
Arrays.asList(ParallQuery.create().sql("webframe_searchAllModuleMenus").resultType(TreeModel.class),
ParallQuery.create().sql("webframe_searchAllUserReports").resultType(TreeModel.class)),
paramNames, paramValues);
- 旋转数据并进行环比计算
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 码农网
猜你喜欢:
- spring cache 接口层缓存的演进过程
- gcs v0.1.1 加入接口缓存,Go 配置管理平台
- 微信 SDK 升级,全面支持异步缓存接口, .NET 3.5/4.0版本5月1日起停止更新
- 微信 SDK 升级,全面支持异步缓存接口, .NET 3.5/4.0版本5月1日起停止更新
- 轻松学会HTTP缓存(强缓存,协商缓存)
- 常见面试题之缓存雪崩、缓存穿透、缓存击穿
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

谁说菜鸟不会数据分析
张文霖、刘夏璐、狄松 编著 / 电子工业出版社 / 2011-7 / 59.00元
《谁说菜鸟不会数据分析(全彩)》内容简介:很多人看到数据分析就望而却步,担心门槛高,无法迈入数据分析的门槛。《谁说菜鸟不会数据分析(全彩)》在降低学习难度方面做了大量的尝试:基于通用的Excel工具,加上必知必会的数据分析概念,并且采用通俗易懂的讲解方式。《谁说菜鸟不会数据分析(全彩)》努力将数据分析写成像小说一样通俗易懂,使读者可以在无形之中学会数据分析。《谁说菜鸟不会数据分析(全彩)》按照数据......一起来看看 《谁说菜鸟不会数据分析》 这本书的介绍吧!


