内容简介:In 2006, Robert Andersen sentIn a world without smartphones, Twitter’s primary interface was SMS. There were no threads, no @username autocomplete. If a user said something and you wanted to reply, your only option was to compose a new text to 40404, manua
In 2006, Robert Andersen sent the first tweet that @mentioned another user , and an internet convention was born.
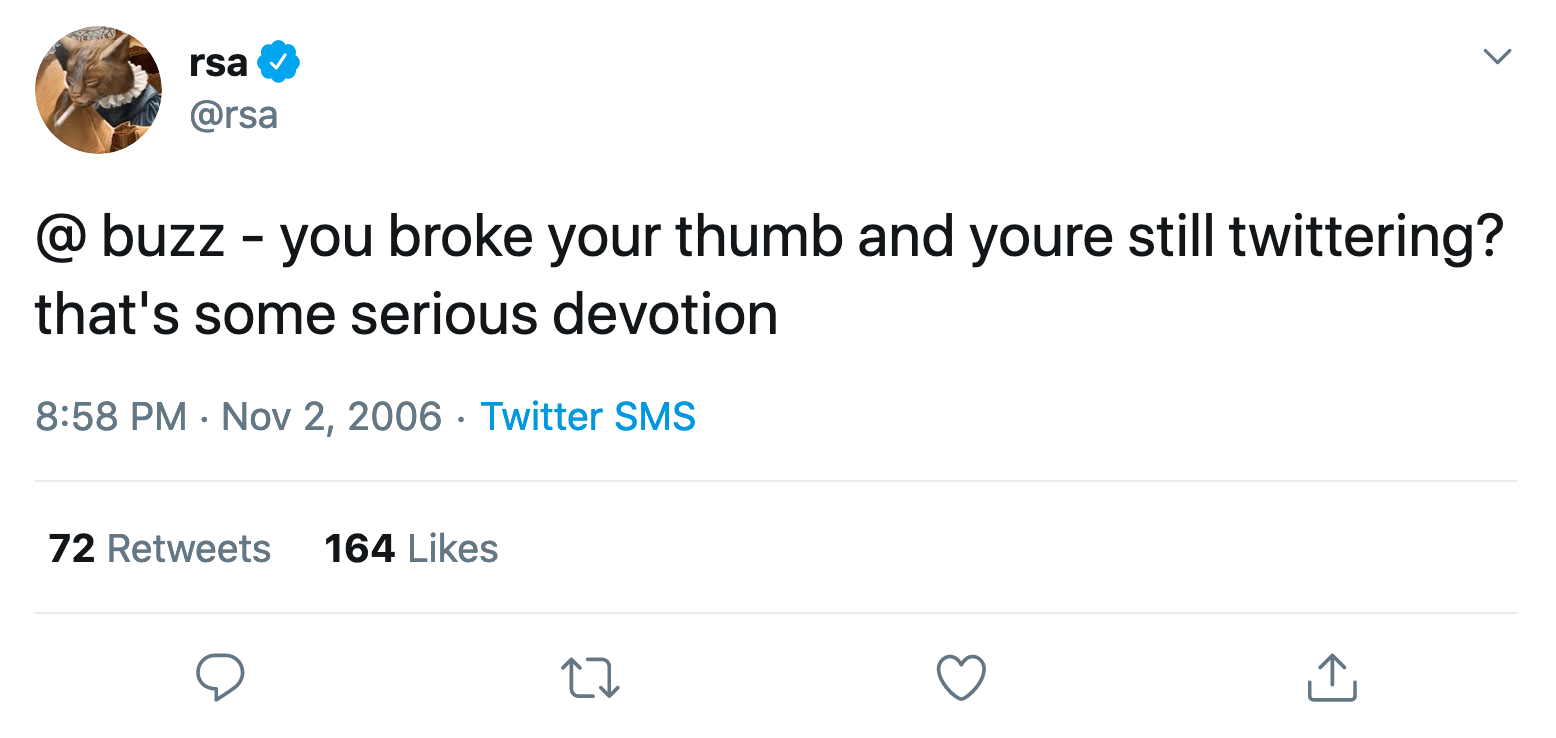
In a world without smartphones, Twitter’s primary interface was SMS. There were no threads, no @username autocomplete. If a user said something and you wanted to reply, your only option was to compose a new text to 40404, manually typing the @mention into your phone’s SMS text box. SMS was also the origin of Twitter’s original 140 character limit:
Twitter began as an SMS text-based service. This limited the original Tweet length to 140 characters (which was partly driven by the 160 character limit of SMS, with 20 characters reserved for commands and usernames).
Also a holdover from the SMS days, Twitter does not allow any formatted or rich text. Users today work around this limitation by using the wide array of possibilities that Unicode affords. Text generators convert ASCII characters into . Memes take advantage of repeated spaces to position text, or to draw Unicode houses. (All of that is, of course, completely inaccessible to screen readers.) Emoji modifiers allow expressing a wide range of emotions with modifiers for skin tones and gender.
Critically, this “plain” text is fully copy-pastable into any app with Unicode support. While many Twitter users from 2006 were likely limited to the GSM-7 encoding , the limitations of the T9 keyboard , and their phone’s limited text rendering and shaping, modern users have found new ways to express themselves using the full Unicode character space. Nowadays, tweets, names, URLs, hashtags, basically everything can contain Unicode characters. Of course, everything except the @mention.
Usernames on Twitter have more or less the same requirements as during the SMS era — up to 15 letters from a-z
, numbers from 0-9
and the underscore _
. This requirement is similar to many other websites: GitHub only allows alphanumeric characters and non-repeating hyphens, and Facebook allows just alphanumeric characters and the period.
As we will see, this limitation is one of several problems with usernames.
Unicode Usernames
Imagine if instead of alphanumerics, GitHub allowed usernames to only be made up of the numbers 0-9
and Chinese characters. It would be pretty frustrating, right? If forced to use a system like this, we would likely ignore the Chinese characters, and just use the numbers as usernames. This is often what happens on social media platforms in countries that don’t use Latin script. In China, the QQ instant messaging service (originally started in 1999) completely got rid of usernames used by similar services like AOL. Instead, each user is assigned a unique number, their QQ ID. This number cannot be chosed by the user, and is immutable. WeChat similarly assigns users a random number when they sign up, although it does allow each user exactly one opportunity to change it to an alphanumeric string of their choice. Typing long numbers isn’t particularly ergonomic, which could help explain the widespread use of QR codes in China.
Even in Latin-speaking countries, AOL-style usernames had issues. By requiring a username when logging in, and also requiring usernames to be unique among all users, users are often forced to use different usernames on different services, creating a second password that they had to memorize. Thankfully, most services have fixed at least this small problem by having login be email- instead of username-based.
Throughout the world, usernames are alphanumeric only. Why can’t we just allow Unicode, so that usernames could contain Chinese, Cyrillic, or other non-Latin alphabets? Unfortunately Unicode usernames have their own issues — just look at the largest username system in the world, the domain name system and the extension that allowed non-ASCII characters . This was an essential upgrade, and yet it has inperfections, allowing the registration of websites such as this one:
This is latest Firefox, as of July 2020, displaying what appears to be “epic.com”, the website of a large healthcare company. However, as you can see, the content is actually some random blog reminding people to drink water. How is this possible? If we stick the code into a Unicode character inspector, we can see what’s going on:
Byte-wise, the real “epic.com” and the false website “еріс.com” are completely different. But visually, they’re indistinguishable from each other in the URL bar, allowing phishing problems to run amock. Unicode canonicalization and normalization can help with certain cases of this problem, but does nothing for our epic.com example.
This particular example isn’t visible in Chrome, which instead shows https://xn--e1awd7f.com/
, the “punycode”
representation of the domain name. This is thanks to Chrome’s complex, 13 step process
for detecting if a domain name is likely to be a Unicode phish or not. “Well, it may be complex,” you tell me, “but at least it solves the phishing problem!” Unfortunately it does not.
Specific instances of IDN homograph attacks have been reported to Chrome, and we continually update our IDN policy to prevent against these attacks.
The Unicode spec is apparently too large to solve this problem 100% perfectly, and so their “solution” is to pay $2000 to anybody who finds new edge cases. This also doesn’t actually solve the problem for non-Latin alphabets — if for example, I own a Chinese domain name, it will never show punycode, and attackers can phish my site using duplicate encodings for those Chinese characters. Chrome just attempts to solve the much smaller problem of the numerous Unicode characters that visually look like the Latin alphabet.
This is probably frustrating to read, and you may want to point fingers Unicode, for failing to provide canonical encodings for a series of graphemes. Or perhaps we can blame the domain name registrars, for allowing visually identical registrations. But I think the real culprit here is the incorrect assumption we Latin script users have when we build usernames into our systems. We assume that two visually-identical printed text tokens will have the same bytewise encoding. This is simply not true for a huge portion of computer users, and is a root failing with username-based systems today. The only solution is to develop systems that don’t have usernames.
Even in a trusted system with no bad actors, there is no guarantee a user retyping a non-Latin username from a printed document will end up with the same bytes as the original document.
Changing Usernames
Let’s say you’re building a site for English use only, and so even after reading all of this, you think perhaps it’s ok to have usernames. After all, you’ll probably find, like Twitter did, that this makes text entry for @mentions much simpler to implement. You get to use just a plain text field, instead of building an input field that can insert custom @mention objects.
Unfortunately, you will still run into the issue of somebody changing their username. This is often an extremely complex problem. Take GitHub for example. Changing your username there will redirect your old repository links to new ones. However, somebody else can come in and use your old username. What happens if they create a repo with the same name as your old one?
If the new owner of your old username creates a repository with the same name as your repository, that will override the redirect entry and your redirect will stop working.
URLs aren’t the only place GitHub usernames are used. Using the web interface, in some cases, will create commits with the email [email protected]
. These commits will permanantly be disconnected from your account, unless you somehow are able to force push edited commit headers to every repository you’ve ever contributed to. Good luck with that.
Instagram has issues with changing usernames, too. Up until 2015, updating your username would cause you to lose all your previous @mentions. They’ve since fixed this; old @mentions eventually update. Twitter supposedly will also preserve your replies, although my testing shows this is an unreliable feature at best. Updating the actual @mention as it’s listed in the Tweet would have other issues, since if a user mentioned in a 280-character tweet adds 5 characters to their username, you’d suddenly get a 285-character tweet. Hope your Twitter clients can all support that.
The final example of username switching pains I have is from my year at Google. I was fortunate enough to never switch my username, perfectly satisfied every morning when I opened my laptop and saw [email protected]
on the login screen. But countless internal systems used by engineers there assume usernames are immutable, making a username switch a multi-day process that is never really complete.
There is one easy “solution” to all of this, of course, which is to make it impossible to change your username. This is what gmail does :
If your account’s email address ends in @gmail.com, you usually can’t change it.
I love the “usually”. I guess in certain, mysterious cases it’s possible to change it? In any case, making a random, numeric user ID immutable is fine. But if that user ID contains letters and is user-selected, making it immutable is an unacceptable solution for real-world situations. Whether it contains a user’s deadname, or an old nickname they don’t go by any longer, or even for those of us who, in sixth grade, decided “lordjubjub” would be an excellent and professional email address (just a hypothetical example, of course), usernames need to be editable. If they’re editable, why not avoid all these username troubles and just go for a fully-Unicode, non-unique display name instead?
Username Alternatives
250 million people have registered for Discord, a chat app similar to Slack or IRC. However, unlike Slack and IRC whose usernames are local to a particular server, Discord has just one server, and usernames are universal. With 250 million users in a single username space, collisions become a massive problem, finding short or reasonable usernames becomes nearly impossible, and you start to see users mass-registering accounts to sell the usernames for Bitcoin.
To avoid all these issues, Discord dropped uniqueness requirements. Multiple users can all have the same username, although they aren’t quite a display namee, since a Discord-generated #1234
discriminator number appears at the end of usernames in certain contexts. This even allows them to have fully-Unicode usernames
; username phishing is less of a problem when users expect duplicate usernames, and none of your systems depend on username uniqueness.
Slack went futher than this, and in 2017 decided to phase out usernames completely
in favor of display names only. Users @mention each other by typing an @
, a few characters of a persons name, and clicking on the dropdown. In some cases when there are duplicate display names, not selecting from the dropdown will result in an error:
As a text editing engineer, I also can’t help but look at this through the lens of text editing technologies. (Yes, that’s right! It’s always about text editing.) Usernames are a product of the text input and encoding systems used in decades past — just look at how Twitter’s username needs were influenced by SMS protocols. The username advances made by Slack and Discord are only possible because they’re able to build rich text editors ( difficult with modern frameworks! ) that allow embedded, autocompleted @mentions that don’t rely on the uniqueness of text tokens. You might be surprised just how much of the UI landscape is driven by these changes and advances in text editing.
I’ve just got one final note: while they’re extremely common, usernames are far from the only example of text as a unique token. JSON APIs use text tokens everywhere; we’ve only recently seen protocols with renamable fields like protobuf and capnproto gain popularity. Variables in programming languages are also common text tokens, and while arguably changing a name isn’t a large deal for local variables, changing the name of a public class in most languages I know is a breaking change. Filesystem directories, too, are unique text tokens, and can suffer from naming conflicts where two bits of software have the same command name, or store their settings in the same directory.
Proposing to get rid of variable labels or filenames may sound impossible, or wild, or unnecessary, but our industry’s waning love for the username shows there are numerous benefits to avoiding text-based unique tokens. If we want to move onward from these limitations, we shouldn’t look toward fixing the tokens themselves. We already know technically how to generate unique numeric identifiers, and we could easily just generate unique numbers for directories or programming language entities. Instead, Slack and Discord show us the main problem — plain text editing forces us to conflate our model of identity with our model for labels.
It turns out this isn’t a text token problem. It’s a text editing problem.
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网
猜你喜欢:
本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

指数型组织
萨利姆•伊斯梅尔 (Salim Ismail)、迈克尔•马隆 (Michael S. Malone)、尤里•范吉斯特 (Yuri van Geest) / 苏健 / 浙江人民出版社 / 2015-8-1 / CNY 69.90
《指数型组织》是一本指数级时代企业行动手册。作者奇点大学创始执行理事萨利姆·伊斯梅尔归纳了指数型组织的11个强大属性,并提出了建立指数型组织的12个关键步骤。通过自己创建的一套“指数商”测试题,伊斯梅尔还测量出了指数型组织世界100强。 为什么小米、海尔和阿里巴巴能进入“指数型组织世界100强”名单?“独角兽”Uber、Airbnb、谷歌等知名企业是如何指数化自己的组织的? 未......一起来看看 《指数型组织》 这本书的介绍吧!


